






作者:Adrian Rosebrock
翻译:吴振东
校对:郑滋
本文约5000字,建议阅读10+分钟
本文教你如何在树莓派和Movidius神经加速棒上运用Tiny-YOLO来实现近乎实时的目标检测。

在这篇教程中,你将会学到如何用YOLO和Tiny-YOLO在树莓派和Movidius NCS上完成一个接近实时的目标检测任务。
YOLO目标检测在近期经常会被人们提起,它是速度最快的深度学习目标检测算法之一,它所实现的FPS(画面每秒传输帧数)指标要比那些消耗大量计算资源的two-stage探测器(例如:Faster R-CNN)或某些single-stage探测器(例如:RetinaNet或某些SSD的变种)更高。即便如此,YOLO的高速并不足以使得它在树莓派上运行,即便是加上Movidius NCS的话也不会有明显的起色。
为了让YOLO变得更快一些,YOLO的创造者们Redmon等人定义了一个YOLO架构的变种,称作Tiny-YOLO。
Tiny-YOLO的处理速度约是老大哥YOLO的442%,在单个GPU上处理视频的刷新率为每秒244帧。
Tiny-YOLO具有模型小(小于50MB)和推理速度快这两大优势,使得它作为目标检测器非常适合移植在树莓派、Google Coral和NVIDIA Jetson Nano上。
关注头条号《数据派THU》后台回复“200229”获取本文项目代码下载链接
今天你将会了解到如何使用Tiny-YOLO,并将它部署在树莓派上,再加上Movidius NCS的作用,可以组成一个接近实时的目标检测项目。
在树莓派+Movidius NCS上运用YOLO和Tiny-YOLO完成目标检测
在这篇教程的第一部分,让我们来了解一下YOLO和Tiny-YOLO目标检测。
随后,我来告诉你如何去配置你的树莓派和OpenVINO的环境,这样你就可以使用Tiny-YOLO了。
然后来回顾一下这个项目的目录结构,其中包括利用一个shell脚本来正确地进入到你的OpenVINO环境中。
在我们了解了整个项目结构后,就需要植入一个含有以下内容的Python脚本:
- 进入我们的OpenVINO环境。
- 在视频中读取帧图像。
- 利用树莓派、Movidius NCS和Tiny-YOLO来完成接近实时的目标检测。
最后,我们以检验脚本的结果作为整篇教程的结尾。
什么是YOLO和Tiny-YOLO?
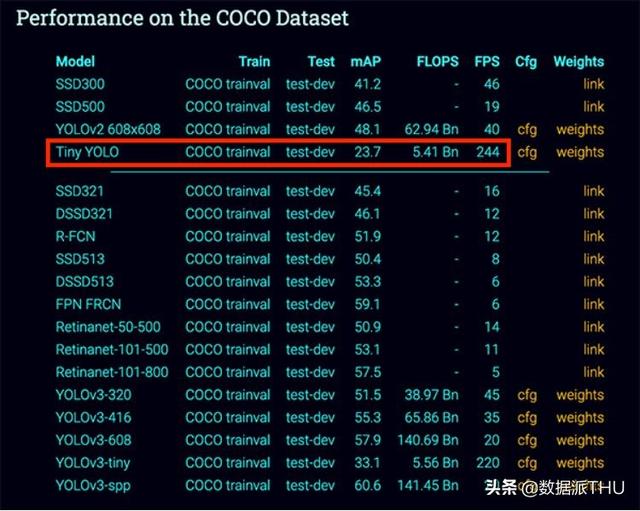
图1:Tiny-YOLO对于COCO数据集的mAP值比其他物体检测器更低。这说明Tiny-YOLO在你的树莓派+Movidius NCS上有可能会是一个有用处的物体检测器
Tiny-YOLO是Redmon 等人在2016年公开发表论文《You Only Look Once: Unified, Real-Time Object Detection》中提到的'You Only Look Once' (YOLO)物体检测器的一个变种。
《You Only Look Once: Unified, Real-Time Object Detection》:
https://arxiv.org/abs/1506.02640
YOLO的出现是为了提高two-stage目标检测器的速度,例如Faster R-CNN。
R-CNNs的精确度很高,但是即便是在GPU上运行,他们的速度依然很慢。与此相反,像YOLO这样的single-stage检测器速度非常快,在GPU上运行的话能够达到实时检测的效果。
YOLO的缺点就是准确率不是特别高(而且以我的经验,YOLO要比SSDs和RetinaNet更难训练)。
另外Tiny-YOLO是小巧版的YOLO,这意味着他的准确率要相对更低。
作为参考,在Redmon等人的报告中,YOLO在COCO基准数据集上的mAP约是51-57%,而Tiny-YOLO的mAP只有23.7%,准确率比它“大哥”的一半还要低。
实际上,23%的mAP对于某些应用来说还是在合理范围内的。
我一般的建议是用YOLO来进行“最初的尝试”:
- 在一些案例中,它可能非常适合你的项目;
- 如果不合适,你可以再去尝试其他更准确的检测器(Faster R-CNN, SSDs, RetinaNet等等)
想要了解YOLO,Tiny-YOLO或者其他版本的YOLO,请一定要阅读Redmon等人在2018年所发表的论文。
配置你的树莓派和OpenVINO的环境

图2:在树莓派和Movidius NCS上配置OpenVINO工具包,用于使用TinyYOLO做目标检测
想要再现这篇教程中的结果,需要配有树莓派4B和Movidius NCS2(不支持NCS1)两项硬件。
我建议你选择一版《Raspberry Pi for Computer Vision》并将 icluded pre-configured.img拷在你的存储卡里,这个文件非常重要,可以省去你数小时的无谓工作。
《Raspberry Pi for Computer Vision》:
https://www.pyimagesearch.com/raspberry-pi-for-computer-vision/
configured.img:
https://www.pyimagesearch.com/2016/11/21/raspbian-opencv-pre-configured-and-pre-installed/
如果有人固执地想要自己去搞树莓派和OpenVINO的配置,这里有一个简单的指导:
- 根据BusterOS安装指导手册来创建一个名为cv的环境。
- 根据OpenVINO的安装指导手册创建第二个环境,命名为openvino。请确保下载的是OpenVINO 4.1.1版本(4.1.2版本有未解决的问题)
BusterOS:
https://pyimagesearch.com/2019/09/16/install-opencv-4-on-raspberry-pi-4-and-raspbian-buster/
OpenVINO:
https://www.pyimagesearch.com/2016/11/21/raspbian-opencv-pre-configured-and-pre-installed/
为了解析JSON结构,你需要在你的虚拟环境中安装JSON-Minify包:
$ pip install json_minify到了这一步,你的树莓派就有了一个普通的OpenCV环境和一个OpenVINO-OpenCV环境。对于本篇教程,你需要用到openvino 环境。
现在,只需要把你的NCS2插入到蓝色的USB 3.0端口上(树莓派4B有一个高速的USB 3.0端口),然后用下面两种方式中的某一种来开启你的环境:
- 选项A:执行Pre-configured Raspbian .img脚本文件。
Pre-configured Raspbian .img:
https://pyimagesearch.com/2016/11/21/raspbian-opencv-pre-configured-and-pre-installed/
然后激活你的OpenVINO环境,然后敲入一行简单的命令:
$ source ~/start_openvino.shStarting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...- 选项B:组合方法
如果你不介意到底是输入一行命令还是两行命令,你可以打开终端并输入:
$ workon openvino$ source ~/openvino/bin/setupvars.sh第一行命令用于激活我们的OpenVINO虚拟环境,第二行命令建立Movidius NCS与OpenVINO之间的联系。(这一步非常重要,否则你的脚本将会出问题)
这两种方式都是假设你没有使用我的Pre-configured Raspbian .img脚本的情况下,或者说没有遵循OpenVINO安装指导手册,完全你自己来安装OpenVINO 4.1.1
Pre-configured Raspbian .img:
https://pyimagesearch.com/2016/11/21/raspbian-opencv-pre-configured-and-pre-installed/
OpenVINO安装指导手册:
https://pyimagesearch.com/2019/04/08/openvino-opencv-and-movidius-ncs-on-the-raspberry-pi/
警告:
- 有些版本的OpenVINO在读取mp4格式的视频时会遇到一些问题,这个bug已经反馈给英特尔团队。我们提供的preconfigured .img文件包含一个由Abhishek Thanki编辑的源代码和编译过的OpenVINO。如果你遇到了这个问题,请支持英特尔去解决它。无论是A选项还是B选项,都需要用到pre-configured .img脚本。
- NCS1并不支持本教程所提到的TinyYOLO模型。这有点不正常,因为一般情况下NCS2和NCS1是兼容的(NCS2只是速度更快)。
- 当我们发现其他警告时,会加到这份列表里。
项目结构
利用tree指令在控制台查看一下项目的结构:
$ tree --dirsfirst.├── config│ └── config.json├── intel│ ├── __init__.py│ ├── tinyyolo.py│ └── yoloparams.py├── pyimagesearch│ ├── utils│ │ ├── __init__.py│ │ └── conf.py│ └── __init__.py├── videos│ └── test_video.mp4├── yolo│ ├── coco.names│ ├── frozen_darknet_tinyyolov3_model.bin│ ├── frozen_darknet_tinyyolov3_model.mapping│ └── frozen_darknet_tinyyolov3_model.xml└── detect_realtime_tinyyolo_ncs.py6 directories, 13 files在COCO数据集下训练好的TinyYOLO模型放在yolo/文件夹下。
intel/文件夹包含由英特尔公司提供的两个类:
- TinyYOLOv3:一个用于解析、缩放和计算TinyYOLO结果IOU(交并比)的类。
- TinyYOLOV3Params:一个用于建一参数对象的类。
我们今天不会述评英特尔所提供的这两个脚本,鼓励你自己去检查一下这些文件。
我们的pyimagesearch 模块包含Conf 类,功能是用于解析config.json格式。
一段行人在一个公共场所行走的测试视频(从牛津大学官网爬取)用来检测TinyYOLO目标检测的性能。鼓励你把自己的视频也加入到 videos/文件夹下。
今天这篇教程的核心与detect_realtime_tinyyolo_ncs.py文件相关。这个脚本载有TinyYOLOv3模型,可以实时推理视频流的每一帧图像。这个脚本还会计算FPS评价标准,评估TinyYOLOv3是否可以在你的树莓派4B加NCS2上做近乎实时的推理。
我们的配置文件

图3:Intel’s OpenVINO Toolkit加上了OpenCV在英特尔设备(例如Movidius Neural Compute Stick)上进行深度学习推理的优化。我们将会利用OpenVINO来进行在树莓派和Movidius NCS 上的TinyYOLO物体检测
我们的配置变量封装在 config.json文件中,当你打开时会发现里面有以下内容:
{ // path to YOLO architecture definition XML file "xml_path": "yolo/frozen_darknet_tinyyolov3_model.xml", // path to the YOLO weights "bin_path": "yolo/frozen_darknet_tinyyolov3_model.bin", // path to the file containing COCO labels "labels_path": "yolo/coco.names",第3行定义了我们的TinyYOLOv3结构定义文件的路径,第6行指定了TinyYOLOv3在COCO训练集上预训练所生成的权重路径。
在第9行提供了COCO数据集标签名字的路径。
下面来看一下过滤检测物体时所用到的变量:
// probability threshold for detections filtering "prob_threshold": 0.2, // intersection over union threshold for filtering overlapping // detections "iou_threshold": 0.15}第12-16行定义了概率大小和IoU阈值,概率较低的检测物体可能会被我们的脚本过滤掉。如果你发现了太多误识别物体,你可能需要提高阈值。在一般规则下,我习惯于把阈值设置为0.5。
将YOLO和Tiny-YOLO物体检测脚本部署在Movidius NCS
现在我们已经准备好实现Tiny-YOLO 目标检测的脚本!
在你的文件目录中打开 detect_realtime_tinyyolo_ncs.py文件,并加入以下代码:
# import the necessary packagesfrom openvino.inference_engine import IENetworkfrom openvino.inference_engine import IEPluginfrom intel.yoloparams import TinyYOLOV3Paramsfrom intel.tinyyolo import TinyYOLOv3from imutils.video import VideoStreamfrom pyimagesearch.utils import Conffrom imutils.video import FPSimport numpy as npimport argparseimport imutilsimport timeimport cv2import os我们先了解下第2-14行,主要是引入必要的包;让我们解释下比较重要的几个包:
- Openvino:引入IENetwork 和IEPlugin 从而让我们的Movidius NCS可以利用TinyYOLOv3做推理。
- intel:TinyYOLOv3 和TinyYOLOV3Params 两个类是由英特尔公司提供的,可以协助我们转换TinyYOLOv3的结果。
- imutils:VideoStream 类用于匹配快速相机的帧图像捕获。FPS类用于提供一个框架来计算帧/每秒这一基准。
- Conf:这个类是用于转换JSON文件的注释。
- cv2: OpenVINO是修改版的OpenCV,更适用于英特尔设备。
在准备好所有的引用后,我们接下来加载配置文件:
# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument("-c", "--conf", required=True, help="Path to the input configuration file")ap.add_argument("-i", "--input", help="path to the input video file")args = vars(ap.parse_args())# load the configuration fileconf = Conf(args["conf"])这些命令的参数包括:
- --conf: 上一章节介绍的输入配置文件路径。
- --input: 一个可选择的输入视频文件。如果没有指定输入文件,脚本则会选择使用摄像头
根据我们指定的配置路径,第24行用于把我们的配置从硬盘中载入。
现在我们的配置已经载入内存了,接下来要载入COCO数据集的类别标签:
# load the COCO class labels our YOLO model was trained on and# initialize a list of colors to represent each possible class# labelLABELS = open(conf["labels_path"]).read().strip().split("")np.random.seed(42)COLORS = np.random.uniform(0, 255, size=(len(LABELS), 3))第29-31行,载入我们的COCO数据集类别标签,把每一个标签与不同的颜色相关联。后面我们会用到这些颜色来标注边界框和类别标签。
接下来,我们要在Movidius NCS上载入我们的TinyYOLOv3模型:
# initialize the plugin in for specified deviceplugin = IEPlugin(device="MYRIAD")# read the IR generated by the Model Optimizer (.xml and .bin files)print("[INFO] loading models...")net = IENetwork(model=conf["xml_path"], weights=conf["bin_path"])# prepare inputsprint("[INFO] preparing inputs...")inputBlob = next(iter(net.inputs))# set the default batch size as 1 and get the number of input blobs,# number of channels, the height, and width of the input blobnet.batch_size = 1(n, c, h, w) = net.inputs[inputBlob].shape我们第一次调用OpenVINO 的API是用于初始化NCS’s Myriad的处理器,从硬盘中加载TinyYOLOv3的预训练模型(第34到第38行)。
接下来要做的是:
- 准备我们的inputBlob (第42行);
- 将批次大小(batch size)设置为1,因为我们每次处理一帧图像(第46行);
- 确定输入的体积形状尺寸(第47行)。
初始化摄像头或是视频文件流:
# if a video path was not supplied, grab a reference to the webcamif args["input"] is None: print("[INFO] starting video stream...") # vs = VideoStream(src=0).start() vs = VideoStream(usePiCamera=True).start() time.sleep(2.0)# otherwise, grab a reference to the video fileelse: print("[INFO] opening video file...") vs = cv2.VideoCapture(os.path.abspath(args["input"]))# loading model to the plugin and start the frames per second# throughput estimatorprint("[INFO] loading model to the plugin...")execNet = plugin.load(network=net, num_requests=1)fps = FPS().start()我们要求用-input 参数来判定我们是从摄像头还是视频中来获取帧图像,并将其设置为适合的视频流(第50-59行)。
由于英特尔OpenCV-OpenVINO实现中存在一个bug,你在使用cv2.VideoCapture这个函数时必须指定绝对路径。否则的话它无法处理这个文件。
注释:如果 –input 这个参数没有提供,那么摄像头将会启用。默认情况下,使用的是你的PiCamera(第53行)。如果你更喜欢用USB摄像头,你只需要注释掉第53行,去掉第52行的注释。
下一次与OpenVINO API的交互是为了在Movidius NCS上载入TinyYOLOv3,(第64行),在第65行是为了开始测量FPS吞吐量。
至此,我们已经结束了设置步骤,可以开始去处理帧图像,并执行TinyYOLOv3检测:
# loop over the frames from the video streamwhile True: # grab the next frame and handle if we are reading from either # VideoCapture or VideoStream orig = vs.read() orig = orig[1] if args["input"] is not None else orig # if we are viewing a video and we did not grab a frame then we # have reached the end of the video if args["input"] is not None and orig is None: break # resize original frame to have a maximum width of 500 pixel and # input_frame to network size orig = imutils.resize(orig, width=500) frame = cv2.resize(orig, (w, h)) # change data layout from HxWxC to CxHxW frame = frame.transpose((2, 0, 1)) frame = frame.reshape((n, c, h, w)) # start inference and initialize list to collect object detection # results output = execNet.infer({inputBlob: frame}) objects = []从68行开始我们的实时TinyYOLOv3物体检测循环。
首先,我们获取并截取第一帧图像(第71-86行)。
接着,我们进行物体检测推理(第90行)。
第91行 初始化一个接下来我们要移入objects 的列表。
# loop over the output items for (layerName, outBlob) in output.items(): # create a new object which contains the required tinyYOLOv3 # parameters layerParams = TinyYOLOV3Params(net.layers[layerName].params, outBlob.shape[2]) # parse the output region objects += TinyYOLOv3.parse_yolo_region(outBlob, frame.shape[2:], orig.shape[:-1], layerParams, conf["prob_threshold"])为了构成物体列表,我们需要遍历output ,创造出我们的layerParams,解析输出范围(第94-103行)。请注意我们要用英特尔提供的代码来协助我们解析YOLO输出。
YOLO和TinyYOLO都倾向产出一定的误识别物体。为了防止这一现象,接下来我们设计两个弱检测过滤器:
# loop over each of the objects for i in range(len(objects)): # check if the confidence of the detected object is zero, if # it is, then skip this iteration, indicating that the object # should be ignored if objects[i]["confidence"] == 0: continue # loop over remaining objects for j in range(i + 1, len(objects)): # check if the IoU of both the objects exceeds a # threshold, if it does, then set the confidence of that # object to zero if TinyYOLOv3.intersection_over_union(objects[i], objects[j]) > conf["iou_threshold"]: objects[j]["confidence"] = 0 # filter objects by using the probability threshold -- if a an # object is below the threshold, ignore it objects = [obj for obj in objects if obj['confidence'] >= conf["prob_threshold"]]第106开始遍历解析过滤器中的物体:
- 我们只允许置信度不等于0的物体存入列表(第110行和111行)。
- 任何无法通过IoU阈值的物体,我们都要修改它的置信度成0(114-120行)。
- 实际上,所有低IoU的物体都将被忽略。
第124和125行是针对我们的第二个过滤器,仔细检查这两行代码:
- 重写我们的物体列表;
- 实际上,我们过滤掉了那些没有达到检测概率阈值的物体。
现在,这些物体只剩下那些我们所关心的了,我们将用边界框和类别标签给要输出的帧图像进行标注:
# store the height and width of the original frame (endY, endX) = orig.shape[:-1] # loop through all the remaining objects for obj in objects: # validate the bounding box of the detected object, ensuring # we don't have any invalid bounding boxes if obj["xmax"] > endX or obj["ymax"] > endY or obj["xmin"] < 0 or obj["ymin"] < 0: continue # build a label consisting of the predicted class and # associated probability label = "{}: {:.2f}%".format(LABELS[obj["class_id"]], obj["confidence"] * 100) # calculate the y-coordinate used to write the label on the # frame depending on the bounding box coordinate y = obj["ymin"] - 15 if obj["ymin"] - 15 > 15 else obj["ymin"] + 15 # draw a bounding box rectangle and label on the frame cv2.rectangle(orig, (obj["xmin"], obj["ymin"]), (obj["xmax"], obj["ymax"]), COLORS[obj["class_id"]], 2) cv2.putText(orig, label, (obj["xmin"], y), cv2.FONT_HERSHEY_SIMPLEX, 1, COLORS[obj["class_id"]], 3)第128行提取了原帧图像的高和宽。我们需要这些信息来进行标注。
接下来遍历那些过滤后的物体,遍历是从131行开始的,我们需要:
- 检查一下检测物体的横纵坐标是否超出了原图的大小,如果是这样的话,我们就抛弃这个识别结果(第134-136行);
- 创建我们的边界框标签,加上物体的class_id和confidence(置信度);
- 利用COLORS (来自于31行)在输出帧图像上标注边界框和标签(第145到152行)。如果边界框的上端距离帧图像的上端太近,那么就像第145和146行写得一样将标签下移15个像素值。
最终我们将显示输出帧图像,计算统计结果,并清理窗口:
# display the current frame to the screen and record if a user # presses a key cv2.imshow("TinyYOLOv3", orig) key = cv2.waitKey(1) & 0xFF # if the `q` key was pressed, break from the loop if key == ord("q"): break # update the FPS counter fps.update()# stop the timer and display FPS informationfps.stop()print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))# stop the video stream and close any open windows1vs.stop() if args["input"] is None else vs.release()cv2.destroyAllWindows()总结,显示输出帧图像,然后在按下键盘q键时我们将会退出循环(第156-161行)。
164行更新我们的FPS计算器。
无论是视频文件没有需要再处理的帧了,还是用户按下了q键,循环都将退出。第167-169行会在你的终端打印出FPS统计。第172和173行会停止视频流并清除所有的GUI窗口。
YOLO和Tiny-YOLO在树莓派和Movidius NCS上的物体检测结果
为了在树莓派和Movidius NCS上使用Tiny-YOLO模型,请确保:
- 根据“Configuring your Raspberry Pi + OpenVINO environment”中的指令来配置你的开发环境;
- 本教程提供的源代码和预训练模型权重。
在解压源代码和模型权重之后,你可以打开终端并执行以下指令:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json --input videos/test_video.mp4[INFO] loading models...[INFO] preparing inputs...[INFO] opening video file...[INFO] loading model to the plugin...[INFO] elapsed time: 199.86[INFO] approx. FPS: 2.66
视频图片出处:牛津大学
在这里我们提供了一个输入视频文件的路径。
树莓派、Movidius NCS和Tiny-YOLO组合的物体检测速率是2.66FPS。
现在让我们尝试一下使用摄像头而不是载入视频文件,只需要忽视-input这个参数就可以:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json[INFO] loading models...[INFO] preparing inputs...[INFO] starting video stream...[INFO] loading model to the plugin...[INFO] elapsed time: 804.18[INFO] approx. FPS: 4.28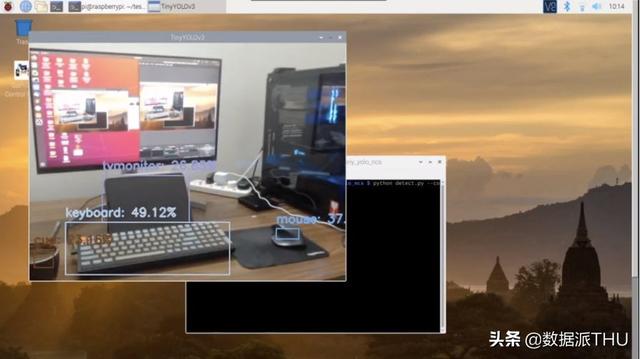
我们可以注意到用摄像头获得的FPS要高一些(约为4.28,高于之前的2.66):
为什么使用摄像头进行物体检测要比对视频的速度更快呢?
理由很简单,相比从摄像头流中获取帧图像,在视频中获取帧图像使得CPU要更多的周期去解码。
视频一般都会通过一定程度的压缩来减小文件大小。
尽管减小了输出文件的大小,但帧图像在读取时依旧需要解压缩——CPU需要去完成这项操作。
相反,CPU在通过webcam格式、USB摄像头或树莓派摄像头模块来获取帧图像时,所做的工作会更少,所以你的脚本会跑得更快。
你用树莓派摄像头模块的话,速度会更快,但这没有任何意义。当你利用树莓派摄像头模块来展示和GPU流处理时(并不是GPU深度学习),树莓派会去读取和处理帧图像,而CPU并不会被涉及。
至于比较USB摄像头和树莓派摄像模块的速度,就留给你们去做实验吧。
注意:所有的FPS统计都是基于树莓派4B 4GB,NCS2(通过USB3.0连接),并通过VNC连接树莓派桌面和OpenCV GUI窗口。如果你跑一个无头算法(例如没有GUI),你的FPS结果可能要高0.5以上,因为将帧图像展示到屏幕上还需要几个CPU周期。请你在对比结果时记住这一点。
Tiny-YOLO的缺陷和限制
尽管Tiny-YOLO在树莓派上的运行速度很快,但是我们会发现他在准确度上还是存在很大的问题。较小的模型意味着它同时也不够准确。
以供参考,Tiny-YOLO在COCO数据集上所达到的mAP值仅为23.7%,而更大的YOLO模型能够达到的值为51-57%。
对于测试Tiny-YOLO,我发现对于某些视频或图片来说结果不错,也有另外一些完全无法使用。
如果Tiny-YOLO的结果没有达到你的预期,请不要泄气,只是这个模型不适合你特定应用而已。
相反,你可以尝试更多更准确的物体检测,包括:
- Larger, more accurate YOLO models
- Single Shot Detectors (SSDs)
- Faster R-CNNs
- RetinaNet
对于植入像树莓派这样的设备,我一直建议你以MobileNet为基础的Single Shot Detectors (SSDs),这些模型在训练(例如优化超参数)时会出现困难,可一旦你获得了一个稳定的模型,会发现这种速度和准确率的折衷是非常值得的。
总结
在这篇教程中,你学到了如何利用Tiny-YOLO在树莓派和Movidius NCS上完成近实时的物体检测。
考虑到Tiny-YOLO小于50MB,推理速度非常快(在GPU上约为244 FPS),这个模型非常适合部署在像树莓派、Google Coral和NVIDIA Jetson Nano上使用。
在树莓派和Movidius NCS上,我们的结果差不多是4.28FPS。
关注头条号《数据派THU》后台回复“200229”获取本文项目代码下载链接
我建议你们将教程中的代码和预训练模型来作为你个人项目的一个起点,再根据你的需求去扩展它们。
原文标题:
YOLO and Tiny-YOLO object detection on the Raspberry Pi and Movidius NCS
原文链接:
https://www.pyimagesearch.com/2020/01/27/yolo-and-tiny-yolo-object-detection-on-the-raspberry-pi-and-movidius-ncs/
如您想与我们保持交流探讨、持续获得数据科学领域相关动态,包括大数据技术类、行业前沿应用、讲座论坛活动信息、各种活动福利等内容,敬请扫码加入数据派THU粉丝交流群,红数点恭候各位。
编辑:黄继彦
校对:林亦霖
译者简介

吴振东,法国洛林大学计算机与决策专业硕士。现从事人工智能和大数据相关工作,以成为数据科学家为终生奋斗目标。来自山东济南,不会开挖掘机,但写得了Java、Python和PPT。
—完—
关注清华-青岛数据科学研究院官方微信公众平台“ THU数据派 ”及姊妹号“ 数据派THU ”获取更多讲座福利及优质内容。















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









