






Spark有哪些组件,组件之间是怎么相互配合实现Spark程序的功能的。
Spark的核心组件主要有5个:
Driver
Master
Worker
Executor
Task
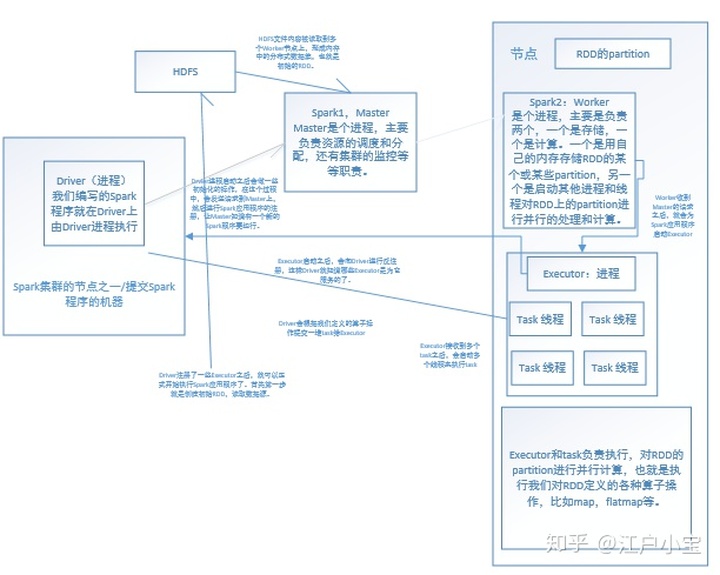
Driver是Spark集群的节点之一或者你提交Spark的那台机器,根据spark的部署和执行模式。Driver是个进程,我们编写的Spark程序就在Driver上,由Driver进程执行。
Master,Master和Worker节点通过Spark配置文件指定。在Spark-en.sh中配置了Spark的Master的节点所在位置,在slaves文件中配置的是Spark的Worker节点。Master和Worker都是个进程,在启动之后通过jps命令可以查看。
Worker也是个进程,主要是负责两个,一个是存储,一个是计算。一个是用自己的内存存储RDD的某个或某些partition,另一个是启动其他进程和线程对RDD上的partition进行并行的处理和计算。
Executor也是一个进程,Executor上会启好几个task线程。
Worker会给某个Spark程序启动一些Executor进程,Executor会为Spark程序启动多个task线程。
Executor和task负责执行,对RDD的partition进行并行计算,也就是执行我们对RDD定义的各种算子操作,比如map,flatmap等。
以上就是基本的架构,下面把各组件串起来。
我们编写Spark程序,提交之后就会起一个Driver进程,Drvier进程启动之后会做一些初始化的操作,在这个过程中,会发送请求到Master上,然后进行Spark应用程序的注册,让Master知道有一个新的Spark程序要运行。
Master在接收到Spark应用程序的注册申请之后会发送请求到Worker,进行资源的调度和分配。资源分配就是Executor的分配。应用程序一开始是没有Executor为它服务的。Master在接收到Spark的注册申请之后,就要告诉Worker,要为Spark应用程序启动几个Executor,涉及到资源调度算法,是Spark中核心算法。
Worker收到Master的请求之后,就会为Spark应用程序启动Executor。
Executor启动之后,会向Driver进行反注册,这样Driver就知道哪些Executor是为它服务的了。
Driver注册了一些Executor之后,就可以正式开始执行Spark应用程序了。首先第一步就是创建初始RDD,读取数据源。HDFS文件内容被读取到多个Worker节点上,形成内存中的分布式数据集,也就是初始的RDD。
Driver会根据我们定义的算子操作提交一堆task给Executor,Executor接收到多个task之后,会启动多个线程来执行task。
在task中会针对本节点的数据(parition)执行算子操作,形成新的partition,会针对新的partition执行新的算子,Driver又会提交一批task到Executor上,再去针对新的RDD的partition执行操作,直到所有的算子操作完成。整个过程和基本工作原理就是这样。















 4689
4689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









