







在数据科学中,不平衡的机器学习数据集并不奇怪。如果用于分类问题的数据集,如情绪分析、医学成像或其他与离散预测分析相关的问题(例如航班延误预测),对于不同的类,其实例(样本或数据点)的数量是不相等的,那么这些机器学习数据集就是不平衡的。这意味着数据集中的类之间存在不平衡,因为属于每个类的实例数量之间存在很大的差异。实例数相对较少的类称为少数类,样本数量相对较多的类称为多数类。不平衡数据集的例子如下:
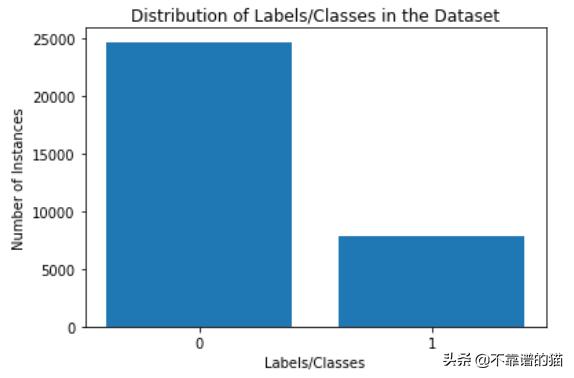
这里有两个类标签:0和1,是不平衡的
用这种不平衡的数据集训练机器学习模型,往往会导致模型对多数类产生一定的偏差,从而对少数类实例/数据点进行错误分类。
SMOTe是一种基于最近邻的技术,由欧几里德判断特征空间中的数据点之间的距离。过采样的百分比表示要创建的合成样本的数量,过采样的百分比参数始终是100的倍数。如果过采样的百分比是100,那么对于每个实例,新样本将被创建,因此,少数类实例的数量将增加一倍。同样,如果过采样的百分比是200,那么少数类样本的总数将增加到三倍。在SMOTe中,
- 对于每个少数类实例,找到k个最近邻,使得它们也属于同一个类,其中,
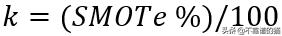
- 找到所考虑的实例的特征向量与k个最近邻的特征向量之间的差异。得到了k个不同向量。
- k个不同向量各自乘以0和1之间的随机数(不包括0和1)。
- 现在,向量在乘以随机数之后,在每次迭代时被添加到所考虑的实例(原始少数类实例)的特征向量中。
从头开始在Python中实现SMOTe如下 -
import numpy as npdef nearest_neighbour(X, x): euclidean = np.ones(X.shape[0]-1) additive = [None]*(1*X.shape[1]) additive = np.array(additive).reshape(1, X.shape[1]) k = 0 for j in range(0,X.shape[0]): if np.array_equal(X[j], x) == False: euclidean[k] = sqrt(sum((X[j]-x)**2)) k = k + 1 euclidean = np.sort(euclidean) weight = random.random() while(weight == 0): weight = random.random() additive = np.multiply(euclidean[:1],weight) return additive def SMOTE_100(X): new = [None]*(X.shape[0]*X.shape[1]) new = np.array(new).reshape(X.shape[0],X.shape[1]) k = 0 for i in range(0,X.shape[0]): additive = nearest_neighbour(X, X[i]) for j in range(0,1): new[k] = X[i] + additive[j] k = k + 1 return new # the synthetic samples created by SMOTe 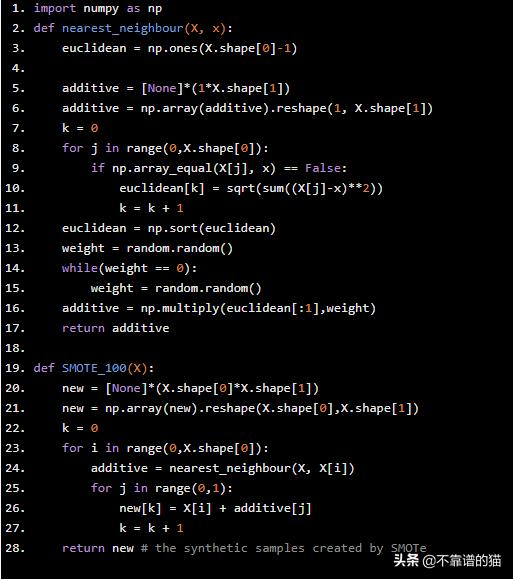
机器学习数据集
让我们考虑来自UCI(加州大学欧文分校)的Adult数据集(http://archive.ics.uci.edu/ml/datasets/Adult),其包含48,842个实例和14个属性/特征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









