





0 前言
大致了解 “&” 和 “*”操作符:
int a = 16;cout << &a << endl; // 输出整型变量a 的地址;效果与c中 printf("%p\n", &a); 等同无需纠结 &a 返回的什么类型(一说指针类型),在不同的编译器(32位4字节,64位8字节)返回值长短不同,总之记着“&变量”形式是获取变量的内存地址就行了。
而“*”主要通过 *指针名 来获取指针指向的内存区域保存的值,后面有详细叙述,问题不大!
1 引用的简单使用
1.1 函数内部使用:
int main(){ int a = 10; int &a_ref = a; cout << &a << endl; // 0x61fe04 cout << &a_ref << endl; // 0x61fe04 a = 12; cout << a_ref << endl; // 12 a_ref = 16; cout << a << endl; // 16 return 0;}由输出所示,无论修改a_ref 的值还是 a 的值,都会引起另一个值的相应变化;
输出两者的地址相同;也就是说,引用一个变量相当于给变量起一个别名,对这个别名对象操作和对源对象操作无异。
1.2 函数参数使用引用
// 注意函数参数类型 void valueRef(int &a) { cout << &a << endl; // a 地址为 0x61fe1c a = 1024;}int main(){ int a = 10; cout << &a << endl; // 主函数中 a 地址 0x61fe1c valueRef(a); // 注意调用方式 cout <endl; return 0;}相较于一般函数:
void valueNoRef(int a) { cout <endl; a = 1024;}int main(){ int a = 10; cout << &a << endl; // 主函数中 a 地址 0x61fe1c valueNoRef(a); cout << a << endl; // 10, 值未修改(能修改才怪) return 0;}通过地址可以看出,没用使用引用时,子函数创建相应的新的函数参数变量(与传入的变量不同),并复制传入变量的值;无论子函数内部对变量做何修改,也只是针对子函数创建的新变量而言,而此变量也会随着子函数运行结束而被销毁。
但子函数使用引用,函数参数变量和主函数变量是同一个对象,子函数中对引用的变量做修改和对原变量做的修改等同。
2 指针的简单使用
2.1 形式
int a = 16; // 声明 int 变量, 名为 a, 内容是int类型数int *p; // 声明 int* 变量,名为 p, 内容是int变量的内存地址,即指向int变量p = &a; // 将p 指向 a 所在的内存区域\; 通过 *p 获取该内存变量值简而言之就是通过变量内存地址修改变量内容,如下例所示:
int main(){ int a = 16; int* a_ptr = &a; // a_ptr 指向变量 a 所在内存块 printf("%d\n", *a_ptr); // 16;通过 * 获取指针(持有的内存地址)指向内存区域保存的值 printf("%p\n", a_ptr); // 000000000061fe1c;获取指针内容,即指向的地址,也即 a 内存地址 printf("%p\n", &a_ptr); // 000000000061fe10;获取存放指针的地址(本人环境下是64b) *a_ptr = 32; // 将 a_ptr 指向内容变更为 32 printf("%d\n", a); // 输出 a 的值为 32 return 0;}逻辑形式大致为:
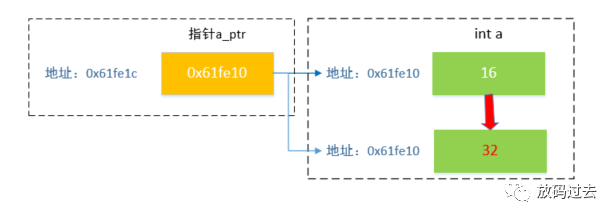
2.2 双指针形式(C语言)
int a1 = 16;int a2 = 32;int* a_p = &a1;int** a_p_p = &a_p;printf("&a1 = %p, &a2 = %p \n", &a1, &a2); // &a1 = 000000000061fdec, &a2 = 000000000061fde8printf("a_p = %p \n", a_p); // a_p = 000000000061fdec 指向 a1printf("a_p_p = %p, &a_p = %p \n", a_p_p, &a_p); // a_p_p = 000000000061fde0, &a_p = 000000000061fde0printf("&a_p_p = %p \n", &a_p_p); // &a_p_p = 000000000061fdd8printf("**a_p_p = %d\n", **a_p_p); // 16*a_p_p = &a2;printf("&a_p_p = %p, a_p_p = %p, *a_p = %p\n", &a_p_p, a_p_p, *a_p_p); // &a_p_p = 000000000061fdd8, a_p_p = 000000000061fde0, *a_p = 000000000061fde8printf("**a_p_p = %d \n", **a_p_p); // 32int **a_p_p 为指向指针的指针,指针通过持有变量的地址来读写变量内容;但是指针也是数据,也需要内存空间来保存,当然也会有内存地址;
因此可以使用指向指针的指针类型,来持有指针的内存地址,逻辑模型如下:
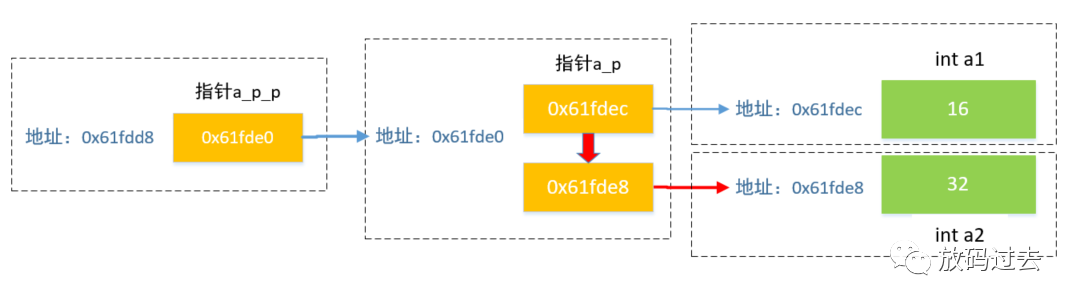
其中*a_p_p = &a2; 就是将a_p_p指向的内容,也就是a_p内容修改成 a2的地址,于是*(*a_p_p) = *(a_p) = 32。变化如上图红色标识。
2.3 指针与数组:
2.3.1 一维数组(C语言):
int arr[3] = {1,2,3};printf("%p, %p \n", arr, arr + 1); // 000000000061FDE4, 000000000061FDE8 两者相差4printf("*(arr) = %d, arr[0] = %d\n", *(arr), arr[0]); // 获取首元素printf("*(arr + 1) = %d, arr[1] = %d\n", *(arr + 1), arr[1]); // 获取次元素其中arr不仅是数组的地址,也是数组首个元素的地址,因此可以使用*(arr)来获取首个元素的值。需要注意的是,arr + 1并不是简单地将地址值加1, 而是根据指向变量的类型决定,如:
char s[3] = {'c', 'j', 'm'};printf("%p, %p\n", s, s + 1); // 000000000061FDE1, 000000000061FDE2 两者相差1(char占一个字节)还有一个比较特别的一维数组,形式为 int *p[n]:
其中p是名字无所谓,甚至是wuGui都无所谓,剩下 int * []。int* 如上文所述,是个指向int的指针指针类型,[] 表示数组的意思。于是int *p[n]可以表示成长度为n、数组元素类型为 int* 的数组。
简单用法:(详细请见2.3.2 部分)
int a1 = 16, a2 = 32;int *p[2];p[0] = &a1;p[1] = &a2;2.3.2 二维数组(C++):
行 row 个元素, 列 col 个元素的二维数组有以下形式
1':int arr[row][col],这个很常规;分配内存使用new int[row][col]即可;
2':int **p,具体使用如下:
// c++中使用 newp = new int*[row];for (int i = 0; i < row; i++) { p [i] = new int[col];}// c中使用malloc(int **) malloc(2 * sizeof(int *));for (int i = 0; i < row; i++) { p [i] = (int *)malloc(sizeof(int) * col);}3':int *p[row],适用于提前得之行数,第二维(列数)初始未确定情况:
int *p[row];// 使用 mallocfor (int i = 0; i < row; i++) { p[row] = (int *) malloc (sizeof(int) * col);}// 使用 new for (int i = 0; i < row; i++){ p[row] = new int[col];}4':int (*p)[col],适用于提前得知列数,第一维(行数)初始未确定的情况:
int (*p)[col],其中 (*p) 表示p为指针类型,int [col] 表示 数组类型,
int (*p)[col] 表示指向数组的指针类型;
int (*p) [col];p = new int[row][col];// c++中,new int[row][col] 返回类型为 int (*)int **p1 = new int[row][col]; // 错误int *p2[row] = new int[row][col]; // 错误int p3[row][col] = new int[row][col]; // 正确int (*p4)[col] = new int[row][col]; // 正确p4 = p3; // 正确2.4 相关细节:
2.4.1 int **p 与 int *p[row] 逻辑相似。以 int *p[row] 为例:
int *p[2];p[0] = (int *) malloc (sizeof(int) * 3);p[1] = (int *) malloc (sizeof(int) * 3);cout <"p = " <" p + 1 = " <1 <endl; cout <"*p = " <" p[0] = " <0] <endl; cout <"*(p + 1) = " <1) <" p[1] = " <1] <endl; cout <"&p[0][0] = " <0][cout <"&p[1][0] = " <1][逻辑模型如图所示:
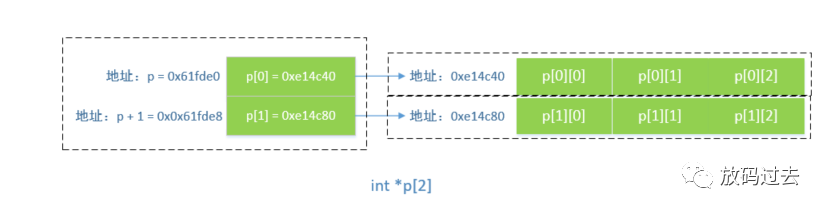
其本质就是含有2个(int *)型元素的数组指针,分别为p[0] (也可写成 *p) 和 p[1](也可写成 *(p+1)),因此他们的地址0x61fde0 和 0x0x61fde8 相差8 = sizeof(int *);
每个数组指针指向含有3个int 型元素的数组。
需要注意的是,p[0][2] 和 p[1][0] 不是连续的,因为 p[0] 内存段和 p[1] 内存段 是分别申请的。若想保证数组的内存地址均连续,可做如下操作:
int *p[row];p[0] = new int[col * row];for (int i = 1; i < row; i++) { p[i] = p[i - 1] + col;}int **p细节大致如 int *p[row] 所言。
2.4.2 int (*p)[col] 与 int p[row][col]
两者本质上是相同的(简而言之:int (*p)[col] = int p[row][col] = new int[row][col]),以 int (*p)[col]为例:
int (*p)[3];p = new int[2][3];cout <"p = " <" p + 1 = " <1 <endl; cout <"*p = " <" p[0] = " <0] <endl; cout <"*(p + 1) = " <1) <" p[1] = " <1] <endl; cout <"&p[0][0] = " <0][cout <"&p[1][0] = " <1][注意,数组地址亦是数组首元素地址,以下可以理解为:
p:指向 一个以 p[0][0] 为首元素的二维数组,通过p[i][j] 或者 *(*(p + i) + j) 来定位到指定元素;
(p + 1): 指向一个以 p[1][0] 为首元素的二维数组,通过 (p+1)[0][0] 来获取到其相对的首元素,即整体的 p[1][0];
*p:指向一个以p[0][0] 为首元素的一维数组,通过 *p[j] 来定位到指定元素,与p[0]等同;
*(p + 1): 指向一个以p[1][0]为首元素的一维数组,通过*(p+1)[j]来定位到指定元素,与p[1]等同。
2.5 综上
简而言之:
声明时,通过 “变量类型 *” 来声明相应的指针类型,通过 “变量类型&” 来声明相应的引用(别名);
操作时,通过 “&变量” 来获取变量地址,通过 “*指针名” 来获取指针指向内存区域的内容;
函数参数中 func_name (类型& 引用名), 表示函数内部对引用名的操作是通过引用机制进行的,调用时直接传入值即可;
函数参数中 func_name (类型* 指针名), 表示需要传入指针类型。
“引用”只是使用了别名来对同一变量修改,而指针则是通过变量的地址来对变量所在的内存就行修改。
还有很多使用细节,比如使用sizeof对指针操作结果一般恒定(根据编译器,有4字节和8字节);而sizeof操作引用变量,获取结果大小则是根据原变量而定,比如int -> 4,double -> 8 。其他细节比如引用需要初始化之类的注意事项可自行总结,平时注意即可。
2.6 实例分析:
数据结构中初始化列表操作:
typedef int ElemType;// 声明 (ListNode* 列表名) 与 (LinkList 列表名) 等同,下面还会重复告诉你哦~typedef struct LNode { ElemType data; LNode * next;}ListNode, *LinkList;void initList(ListNode *L) { // initList(LinkList L) cout <"L = " <endl; cout <"&L = " <endl; L = (ListNode *)malloc(sizeof(ListNode)); L -> next = NULL; cout <"L = " <endl; }int main() { LinkList header; // 节点指针; 等同于 ListNode* header; cout <"header = " <endl; cout <"&header = " <endl; initList(header); cout << "\nafter initList is: " << endl; cout <"header = " <endl; cout <"&header = " <endl; }君试看以上例子,上面的初始化列表的操作显然错误,其逻辑如下:
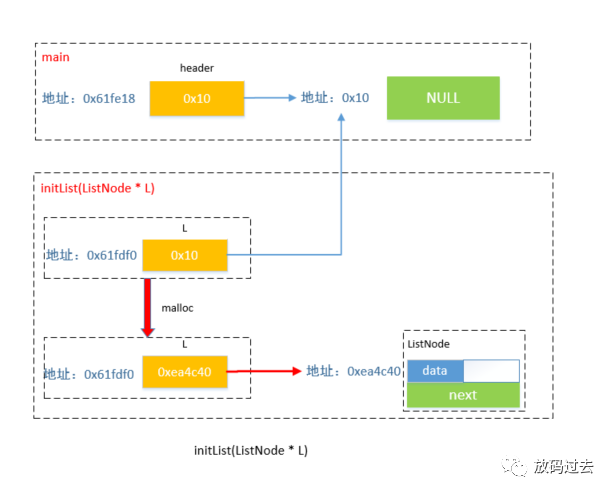
如图后红色标识指针内容变化。起始时,函数体通过函数参数创建新指针,内容与传入参数相同,即指向相同内存区域。但是在子函数initList(ListNode *L) 函数中,通过malloc操作,使得子函数中的指针指向新的内存区域,而这个内存区域随着子函数的执行完毕而销毁,最终main函数中的LinkList 指向区域毫无修改。
因此在子函数创建列表的方法一般是以下三种:
// 方法一:通过返回值创建,比较好理解ListNode* initListReturn() { ListNode* L; // 即为 LinkList L = new ListNode; // L = (ListNode *) malloc(sizeof(ListNode)); L -> next = NULL; return L;}// 方法二:通过双指针;双指针请参见上文中 2.2 所示void initListP(ListNode **L) { // 效果与 initLis tP(LinkList *L) 同 (*L) = new ListNode; // (*L) = (ListNode *) malloc(sizeof(ListNode)); (*L) -> next = NULL;}// 方法三:通过引用void initListRefer(ListNode *&L) { // 效果与 initListRefer(LinkList &L) 同 L = new ListNode; // L = (ListNode *)malloc(sizeof(ListNode)); L -> next = NULL;}方法三中出现的 “*&”可能有些许迷惑性,实际上也就是指针的引用而已,跟其他类型的引用实质没有区别(int类型可以引用,bool、 double等都可以引用,凭啥指针类型的不行哦~上流)。
篇幅所限,基本内容大致如此,害。若有错误,欢迎正当批评和猛烈指正。















 2738
2738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









