






CPU是我们系统重要的资源指标,它提供了最主要的计算功能,所以CPU的状态对整个服务器和应用来讲是最为重要的,那么我们如何使用Prometheus获取到需要监控CPU资源指标。
知识点回顾
CPU的使用率是如何计算的?
1)CPU相关概念
CPU利用率:CPU的使用情况。
用户时间(User time) :表示CPU执行用户进程的时间,包括nices时间。通常期望用户空间CPU越高越好。
系统时间(System time) :表示CPU在内核运行时间,包括IRQ和softirq时间。系统CPU占用率高,表明系统某部分存在瓶颈。通常值越低越好。
等待时间(Waiting time) :CPU在等待I/O操作完成所花费的时间。系统不应该花费大量时间来等待I/O操作,否则就说明I/O存在瓶颈。
空闲时间(Idle time) :系统处于空闲期,等待进程运行。
Nice时间(Nice time) :系统调整进程优先级所花费的时间。
硬中断处理时间(Hard Irq time) :系统处理硬中断所花费的时间。
软中断处理时间(SoftIrq time) :系统处理软中断中断所花费的时间。
丢失时间(Steal time) :被强制等待(involuntary wait)虚拟CPU的时间,此时hypervisor在为另一个虚拟处理器服务。
2)我们查看下一台安装了Prometheus node_exporter主机都采集了那些cpu相关数据
curl localhost:9100/metrics | grep cpu
node_cpu_seconds_total{cpu="0",mode="idle"} 1.12742968e+06
node_cpu_seconds_total{cpu="0",mode="iowait"} 15314.29
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 2851.94
node_cpu_seconds_total{cpu="0",mode="softirq"} 826.97
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 8983.57
node_cpu_seconds_total{cpu="0",mode="user"} 29765.21
后面的数字是cpu的使用时间
3)CPU的使用率是怎么计算的呢?
CPU占用率计算公式
CPU时间=user+system+nice+idle+iowait+irq+softirq+Stl +guest
%us=(User time + Nice time)/CPU时间*100%
%sy=(System time + Hard Irq time +SoftIRQ time)/CPU时间*100%
%id=(Idle time)/CPU时间*100%
%ni=(Nice time)/CPU时间*100% %wa=(Waiting time)/CPU时间*100%
%hi=(Hard Irq time)/CPU时间*100%
%si=(SoftIRQ time)/CPU时间*100%
%st=(Steal time)/CPU时间*100%
Prometheus的演示
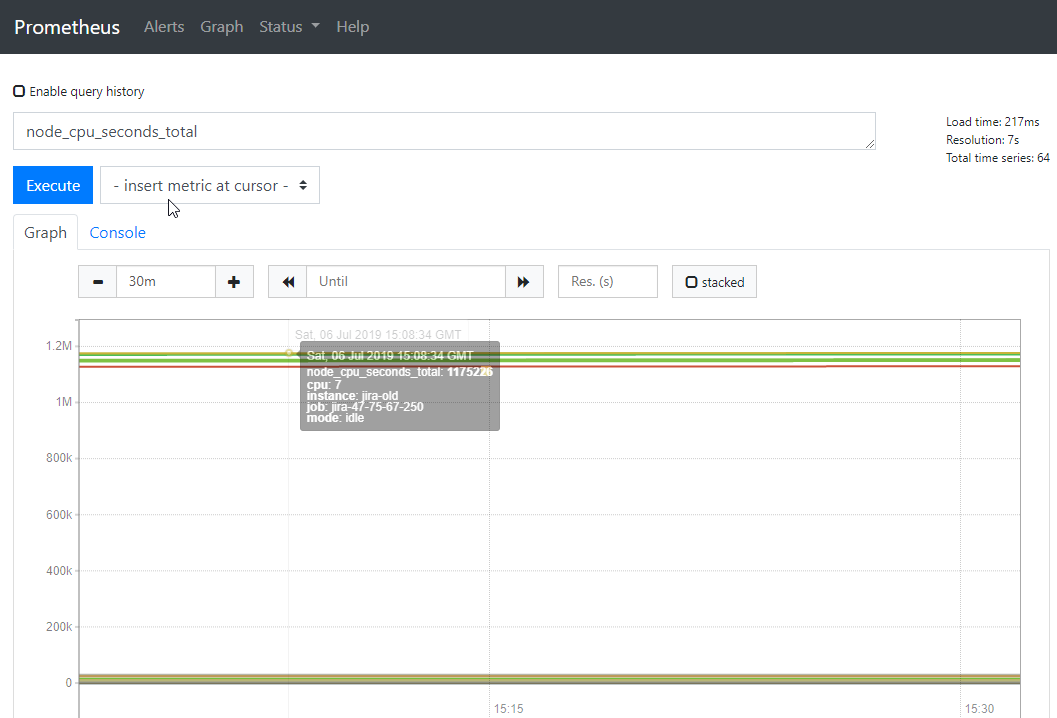
通过 curl localhost:9100/metrics 我们可以看到cpu的总量在prometheus中的key是node_cpu_seconds_total
1)node_cpu_seconds_total 视图
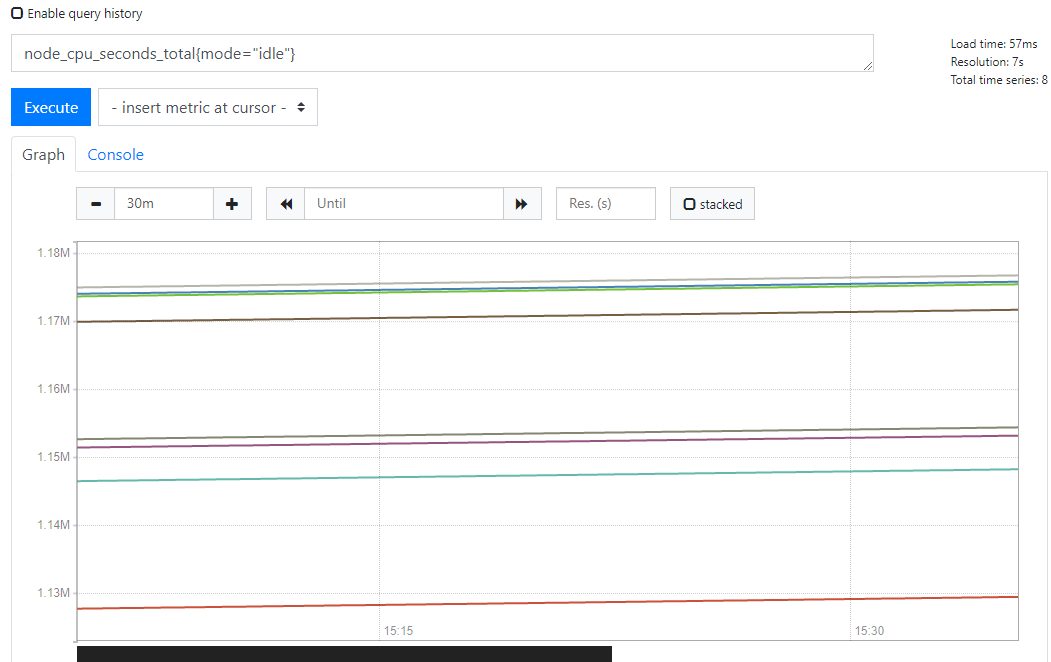
2)如何获取cpu众多值中的一个?例如idle(空闲cpu)
表达式 (key的过滤是通过 { } 实现的 )
node_cpu_seconds_total{mode="idle"}
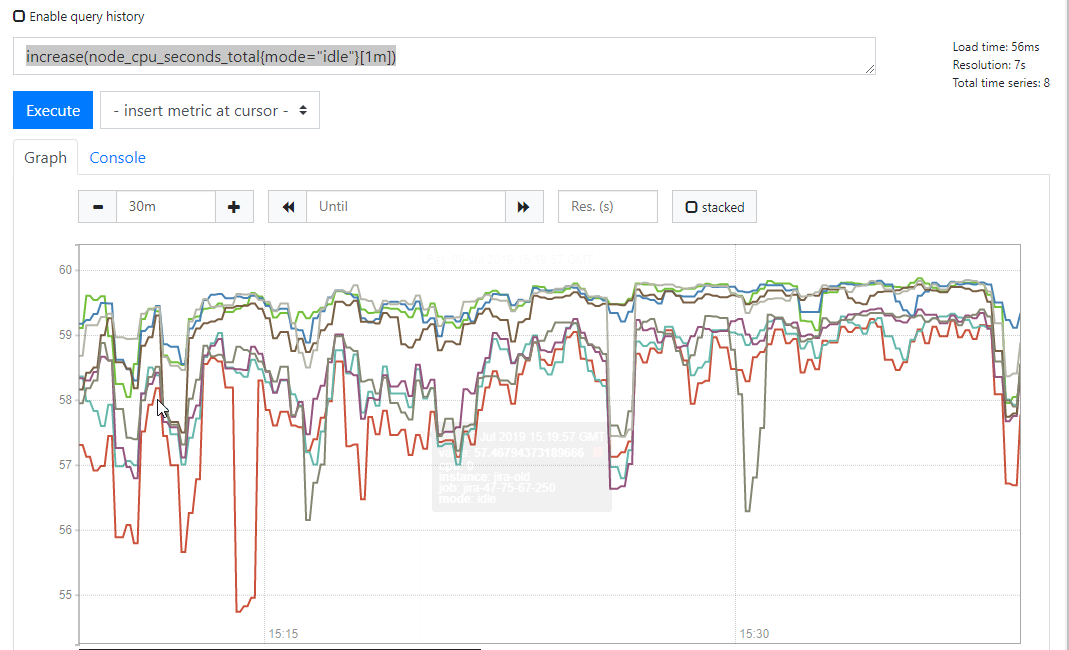
3)获取1m中内的数据变化通过increase()
表达式
increase(node_cpu_seconds_total{mode="idle"}[1m])
4) 获取1m中内的数据变化和
表达式
sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))
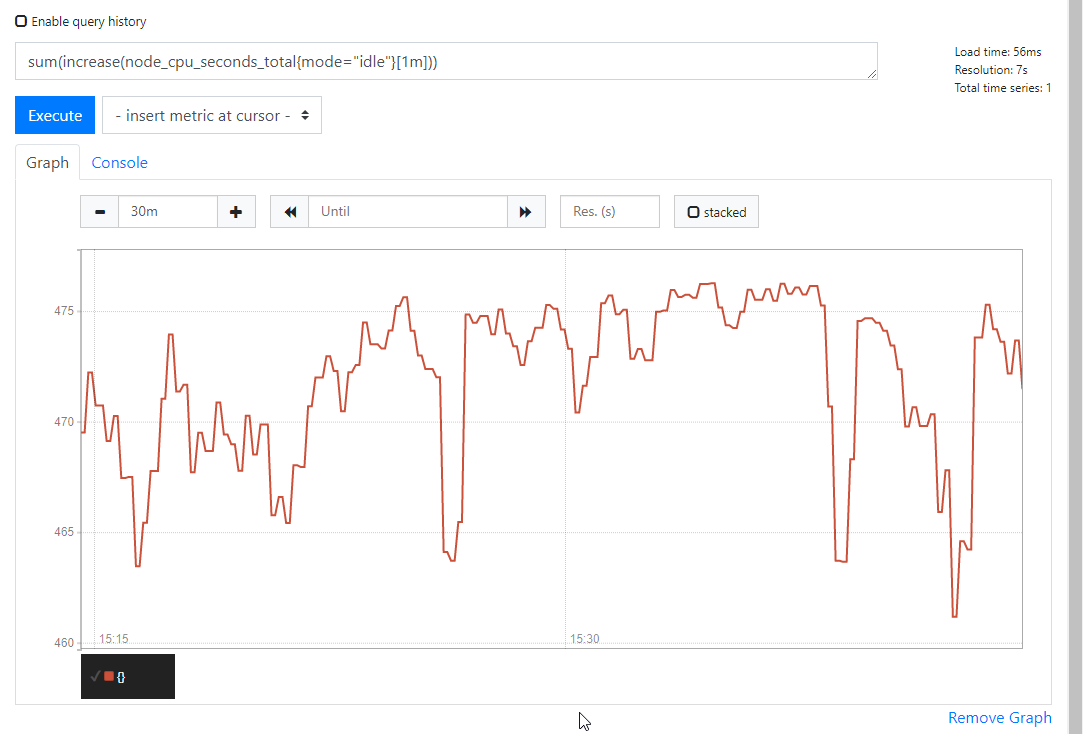
当然这里有个问题,当你使用了sum像是上面的方式,我们求的和是包含了所有服务器的所有cpu的平均值和。意思就是说假如监控上面监控了100服务器其中各个服务器的cpu数量都不尽相同,那么我们的求和就是将这100服务器中的所有cpu求和求平均。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









