






原文:《Python 数据分析与数据化运营》第3章:11条数据化运营不得不知道的数据预处理经验
所谓的不均衡指的是不同类别的样本量差异非常大。样本类别分布不均衡主要出现在分类相关的建模问题上。
样本分布不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律;即使得到分类模型,也容易产生过度依赖于有限的数据样本而导致过拟合的问题。如果不同分类间的样本量差异达到超过10倍需要引起警觉并考虑处理该问题,超过20倍就一定要解决了。
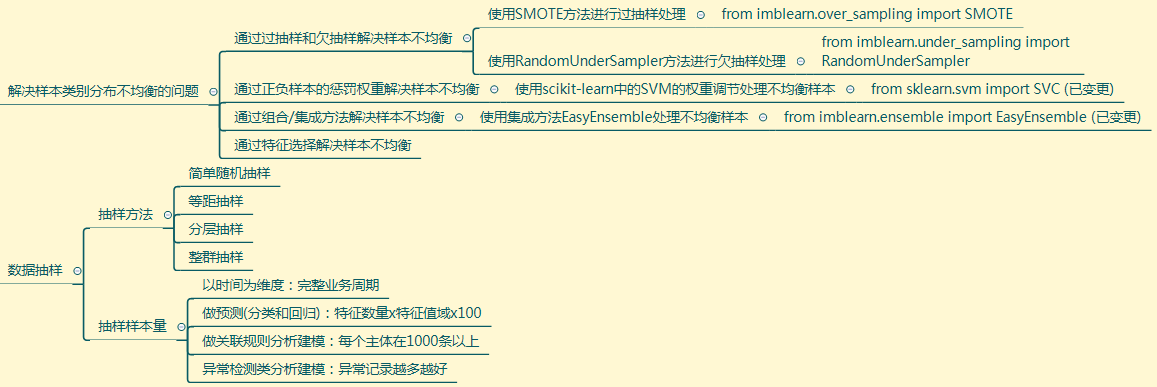
样本不均衡问题的解决方法:
- 过抽样和欠抽样
- 设置正负样本的惩罚权重
- 组合/集成方法:指的是在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型
- 特征选择
代码示例:
import pandas as pd
from imblearn.over_sampling import SMOTE #过抽样处理SMOTE
from imblearn.under_sampling import RandomUnderSampler #欠抽样处理库
from sklearn.svm import SVC #SVM中的分类算法SVC
from imblearn.ensemble import EasyEnsemble #简单集成方法EasyEnsemble
df = pd.read_table('F:/Data/3_data2.txt', sep=' ', names=['col1', 'col2', 'col3', 'col4', 'col5', 'label'])
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
groupby_data_orgianl = df.groupby('label').count() #对label做分类汇总
#print(df['label'].value_counts())
print(groupby_data_orgianl)
#使用SMOTE方法进行过抽样处理
model_smote = SMOTE()
x_smote_resampled, y_smote_resampled = model_smote.fit_sample(x, y) #输入数据进行抽样处理
x_smote_resampled = pd.DataFrame(x_smote_resampled, columns=['col1', 'col2', 'col3', 'col4', 'col5'])
y_smote_resampled = pd.DataFrame(y_smote_resampled, columns=['label'])
smote_resampled = pd.concat([x_smote_resampled, y_smote_resampled], axis=1) #按列合并数据
groupby_data_smote = smote_resampled.groupby('label').count()
print(groupby_data_smote)
#使用RandomUnderSample方法进行欠抽样处理
model_RandomUnderSampler = RandomUnderSampler()
x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled = model_RandomUnderSampler.fit_sample(x, y)
x_RandomUnderSampler_resampled = pd.DataFrame(x_RandomUnderSampler_resampled, columns=['col1', 'col2', 'col3', 'col4', 'col5'])
y_RandomUnderSampler_resampled = pd.DataFrame(y_RandomUnderSampler_resampled, columns=['label'])
RandomUnderSampler_resampled = pd.concat([x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled], axis=1)
groupby_data_RandomUnderSampler = RandomUnderSampler_resampled.groupby('label').count()
print(groupby_data_RandomUnderSampler)
#使用SVM的权重调节处理不均衡样本
model_svm = SVC(class_weight='balanced') #创建SVC模型对象并指定类别权重
model_svm.fit(x, y)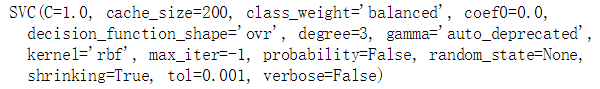
#使用集成方法 EasyEnsemble 处理不均衡样本
model_EasyEnsemble = EasyEnsemble()
x_EasyEnsemble_resampled, y_EasyEnsemble_resampled = model_EasyEnsemble.fit_sample(x, y)
print(x_EasyEnsemble_resampled.shape)
print(y_EasyEnsemble_resampled.shape)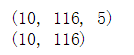
针对非标志列,形成了10个各116行5列的数据集,针对标志列形成了对应的10个各116行的数据集。
#抽取其中一份数据做审查
index_num = 1
x_EasyEnsemble_resampled_t = pd.DataFrame(x_EasyEnsemble_resampled[index_num], columns=['col1', 'col2', 'col3', 'col4', 'col5'])
y_EasyEnsemble_resampled_t = pd.DataFrame(y_EasyEnsemble_resampled[index_num], columns=['label'])
EasyEnsemble_resampled = pd.concat([x_EasyEnsemble_resampled_t, y_EasyEnsemble_resampled_t], axis=1)
groupby_data_EasyEnsemble = EasyEnsemble_resampled.groupby('label').count()
print(groupby_data_EasyEnsemble)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









