





一、安装
1.以管理员身份启动cmd
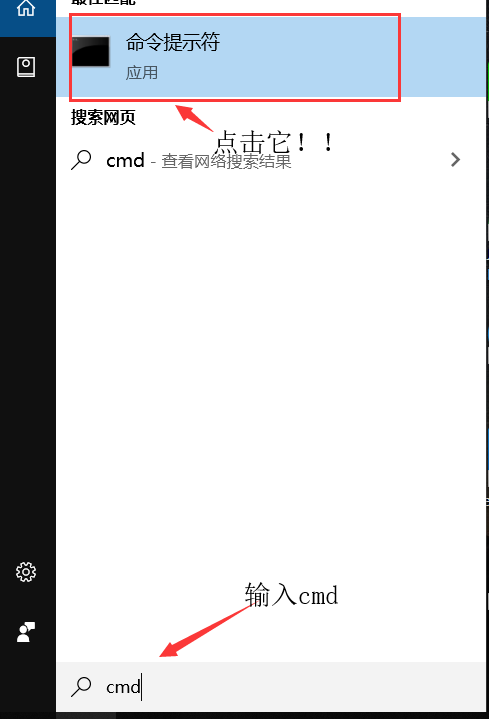
2.输入口令:python -m pip install beautifulsoup4 敲回车 我在这给大家提个醒,配置环境真的很费时间,中间会出现各种问题,一定不要心急,
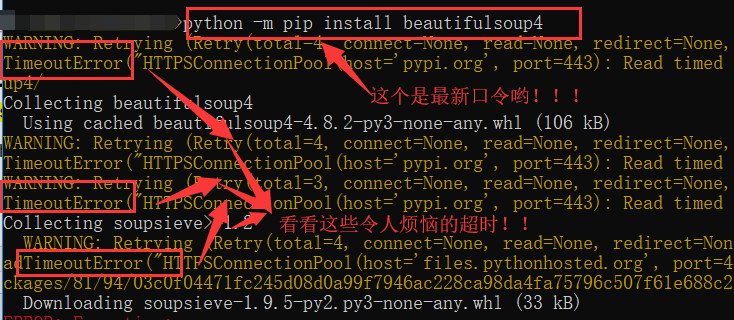
心急吃不了热豆腐呀~但是python库安装我认为遇到的问题都是一样的,就是超时,我是一直不断地让它安装,反反复复7/8次,不着急,超时就让它超时,
能安装一点是一点,到最后肯定能安装好~ 给大家上图我不断超时、最后终于成功的截图!

3.在安装成功后,大家可以测试一下是否安装成功。
演示HTML页面地址:http://python123.io/ws/demo.html
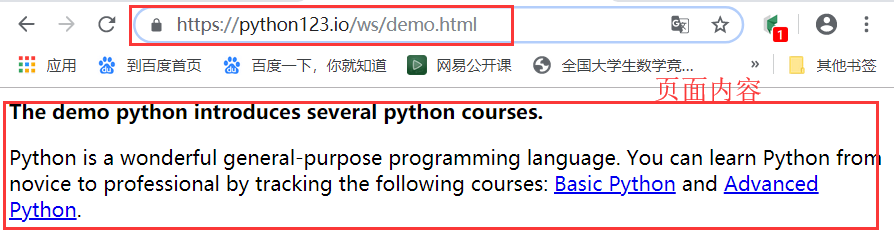
可以单击右键鼠标选择查看网页源代码,看不懂不要紧哦,就理解程成是许许多多的标签,构成了页面,一个排版规则

原理就是:我们先用requests库get()方法爬取网页所有内容,然后定义demo为整个文本内容,然后让beautifulsoup(类)来熬制这个汤熬成
它能理解的HTML5。注意哦,我们虽然导入的是beautifulsoup4库,但是我们在写的时候写成了缩写bs4,并且只用一个BeautifulSoup类,
注意B、S是大写
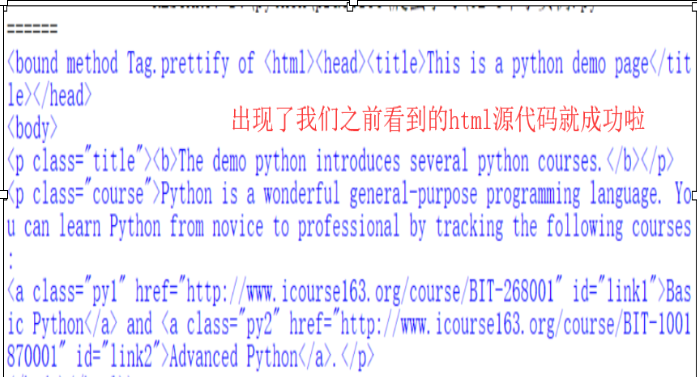
1 importrequests2 r = requests.get("https://python123.io/ws/demo.html")3 demo =r.text4 from bs4 importBeautifulSoup5 soup = BeautifulSoup(demo,"html.parser") #熬制html类型的解释的汤6 print(soup.prettify)
这就是今天的第三方库的安装和检测的学习,是不是历程艰辛但是也是很有趣呢~贵在坚持啦😀😀😀😀😀😀
--------------------------下一期将带来BeautifulSoup4的简单学习!!加油,贵在坚持!------------------------------------------















 2506
2506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









