





日志读取脚本
功能:用于读取某日志文件,可指定某个匹配条件,返回文本中匹配到的该行和前面的n行。此脚本可以接受3个参数,分别是文件对象、搜索的关键词、返回匹配的该行前面的行数。
#!/usr/local/python27/bin/python2.7
import sys
from collections import deque
def search(f,pattern,keep_num):
#定义一个队列,设置最大队列数,这个队列中的数据是可覆盖的,如果达到了最大队列数,则新加入的数据会覆盖前面的。
pre_lines = deque(maxlen=keep_num)
for line in f:
if pattern in line:
yield line,pre_lines
#这里的逻辑就是将从文件对象f中读取的每一行做模式匹配的判断,如果不匹配则放入pre_lines队列中去,继续查找下一行,只保存最大能允许的行数,这个有参数maxlen控制,多出的数据则覆盖前面的,直到匹配到了需要的关键字,则返回一个生成器,生成器中包括了匹配到的行,以及该行之前的n行,也就是之前保存在pre_lines队列中的行。
pre_lines.append(line)
if __name__ == '__main__':
log_file = sys.argv[1]
pattern = sys.argv[2]
keep_num = int(sys.argv[3])
with open(log_file) as f:
#这个循环就是从search函数返回的生成器中取数据,分别保存在变量中,再分别打印出来。
for line,pre_lines in search(f,pattern,keep_num):
for pline in pre_lines:
print pline
print line
print "-" * 20
键值对处理脚本
处理一个key -> value的配置文件,key可能出现多次,对应相同或者不同的value,要求返回每个key对应的所有不重复的value。
这里先讲下collections模块的defaultdict 和 dict
这里的defaultdict(function_factory)构建的是一个类似dictionary的对象,其中keys的值,自行确定赋值,但是values的类型,是function_factory的类实例,而且具有默认值。比如default(int)则创建一个类似dictionary对象,里面任何的values都是int的实例,而且就算是一个不存在的key,d[key]也有一个默认值,这个默认值是int()的默认值0.
笔者的理解:
defaultdict接受一个工厂函数作为参数,这个传入的工厂函数的类型,决定了该字典对象中keys的类型和值的类型。
比如 defaultdict(set)这里传入了一个set类型,这表示其中的keys为集合,要在key中加入数据则要使用集合的内置add方法,对应的value也会符合集合的特点,无序性,唯一性。
如果defaultdict(list) 这里传入了一个list类型,这表示其中的keys为列表,要在key中加入数据则要使用列表的内置方法append,对应的value也会符合列表的特点,有序性,可重复。
处理如下文件:
key1=111
key2=222
key1=111
key1=123
key3=333
key4=111
key5=555
key6=666
key2=222
key7=777
key8=111
要实现返回每个key对应的所有不重复的value,这里要使用set类型。
代码实例:!/usr/local/python27/bin/python2.7
import sys
from collections import defaultdict
conf = defaultdict(set)
for line in open(sys.argv[1]):
k,v = line.split('=')
#由于传入的工厂函数为set,所以这里的key就是集合,要用集合的add方法插入值。
conf[k.strip()].add(v.strip())
for k,v in conf.items():
print "%s => %s" % (k,v)
输出结果:
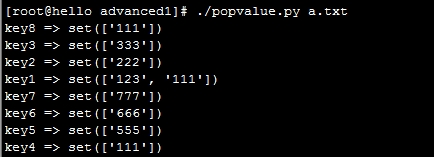
可以观察到文本中有多个重复的key1=111只输出了一次。
下面传入list类型做对比
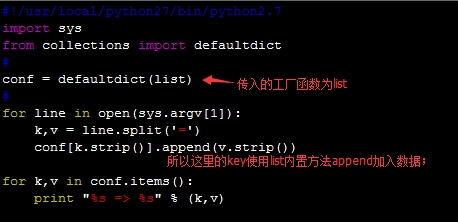
输出结果:
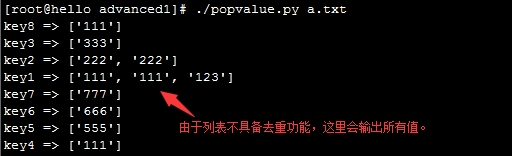
有一些任务,需要保存到字典中,key为名称,value为内容,但是在执行的时候,需要保持存储时的顺序。
方法(一)
使用字典保存数据,并附加一个list保存顺序#!/usr/local/python27/bin/python2.7
import sys
d1=dict()
l1=[]
for line in open(sys.argv[1]):
k,v = line.split('=')
l1.append(k)
d1[k] = v
print("%s => %s" % ( [ i for i in l1],[ d1[i] for i in l1 ]))
方法(二)
使用OrderedDict#!/usr/local/python27/bin/python2.7
import sys
from collections import OrderedDict
od = OrderedDict()
for line in open(sys.argv[1]):
k,v = line.split('=')
od[k.strip()] = v.strip()
for k,v in od.items():
print k,v
一般字典dict()是无序的,但是OrderedDict是有序字典,会按照插入的顺序保存数据。
从一篇英文文章中统计出频率出现最高的10个单词
代码实例:#!/usr/local/python27/bin/python2.7
import sys
import re
from collections import Counter
with open(sys.argv[1]) as f:
#匹配出所以单词,并且全部转换为小写,保存在一个列表中。
words = re.findall(r"\w+",f.read().lower())
#Counter方法可以从一个列表中统计每个元素出现的次数,.most_common(n)用于筛选出出现次数最多n项;
print Counter(words).most_common(10)
输出结果:
./counter.py english_article.txt
[('to', 16), ('his', 15), ('him', 12), ('in', 12), ('tyler', 9), ('she', 9), ('and', 9), ('that', 8), ('he', 8), ('i', 8)
使用命名元组分段处理一个csv的文件
文件样例:
name,gender,email,phone,sn
huairen,man,huai@adminblog.com,1899000001,17829
huairen,man,huai@adminblog.com,1899000001,17829
代码实例:#!/usr/local/python27/bin/python2.7
import sys
import csv
from collections import namedtuple
l1=[]
with open(sys.argv[1],'rb') as f:
reader = csv.reader(f)
nametup = namedtuple("tup",reader.next())
for line in reader:
l1.append(nametup(*line))
print(l1)
命名元组的使用实例:
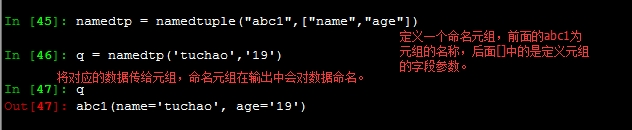
输出结果:
tup(name='huairen', gender='man', email='huai@adminblog.com', phone='1899000001', sn='17829')















 4576
4576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









