







在无监督的视觉表示学习的各种最新模型中,孪生(暹罗)网络已经成为一种常见的结构。

近日,何恺明组发表了名为《Exploring Simple Siamese Representation Learning》的新论文,论文中提到这些模型在避免某些方案崩溃的某些条件下,可以最大化提高了同一图像的两个增强图像之间的相似性。论文报告了令人惊讶的经验结果,即简单孪生罗网络可以学习有意义的表示,即使不使用以下任何一项:(i)负样本对,(ii)大批量,(iii)动量编码器。
实验表明,对于损失和结构确实存在「崩溃解」,但是stop-gradient操作在防止崩溃中起着至关重要的作用。研究人员提供了关于stop-gradient思想的假设,并进一步显示了验证它的概念验证实验。“ SimSiam”方法在ImageNet和下游任务上取得了竞争性结果。作者希望这个简单的基准能够激励人们重新思考暹罗架构在无监督表示学习中的作用。
1、什么是Siamese network 孪生神经网络
Siamese和Chinese有点像。Siam是古时候泰国的称呼,中文译作暹罗。Siamese也就是“暹罗”人或“泰国”人。Siamese在英语中是“孪生”、“连体”的意思。
简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
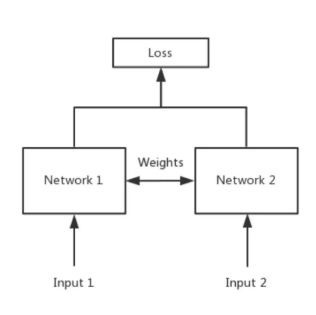
2、结果展示
论文从ImageNet以及迁移学习的角度对比一下所提方法与其他SOTA方法。
2.1 ImageNet
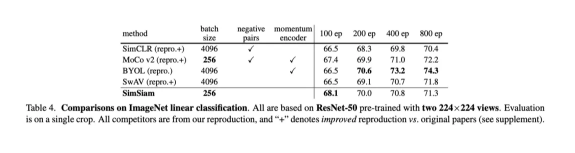
作者将与表中ImageNet线性评估的最新框架进行比较。上表显示了SimSiam的batch size为256,既不使用负样本也不使用动量编码器。尽管简单,SimSiam还是取得了竞争性成绩。在100epoch预训练下,它在所有方法中具有最高的准确性,但更长的训练所得收益反而变小。
2.2 迁移学习
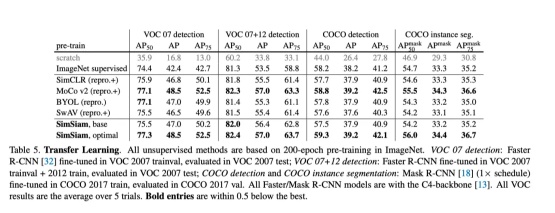
作者通过将它们迁移到其他任务(包括VOC 对象检测和COCO对象检测以及实例分割)来比较表示质量。在目标数据集中端到端微调了预训练的模型。
所有这些方法对于转移学习都是非常成功的。在结果表中,它们在所有任务中都可以超过ImageNet监督的预训练对口,或与之相提并论。尽管存在许多设计差异,但这些方法的常见结构是孪生网络。这种比较表明,连体结构是其总体成功的核心因素。
参考论文:https://arxiv.org/pdf/2011.10566.pdf














 6998
6998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









