






本文中的数据和例子来自于Chuong B Do和Serafim Batzoglou的论文《What is the expectation maximization algorithm ?》 原文链接如下
https://www.nature.com/articles/nbt1406www.nature.com两硬币模型:
##数据集##
labels = ['B', 'A', 'A', 'B', 'A']
flip_seqs = ['HTHHHTTHHHHTHHHTTHHHHHTHHHHH',
'HHTHHHHHTTTTTTTHHTT',
'HTHHHHTTHHTTTTTTTHTTTTHHTTT',
'HTHTTHHTTHHHHHTHHHHHHHTHHHHHTHHHHHHTTHHHHH',
'THHHTHHHTHTTTTTTTTTT']
##极大似然求解##
def estimate_theta(H, T):
return H / (H + T)
from collections import Counter, defaultdict
count_dict = defaultdict(Counter)
for label, seq in zip(labels, flip_seqs):
count_dict[label] += Counter(seq)
print('Coin A: there were {H} heads and {T} tails across the flip sequences'.format(**count_dict['A']))
print('Coin B: there were {H} heads and {T} tails across the flip sequences'.format(**count_dict['B']))打印结果如下:
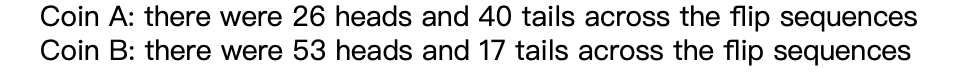
##参数估计
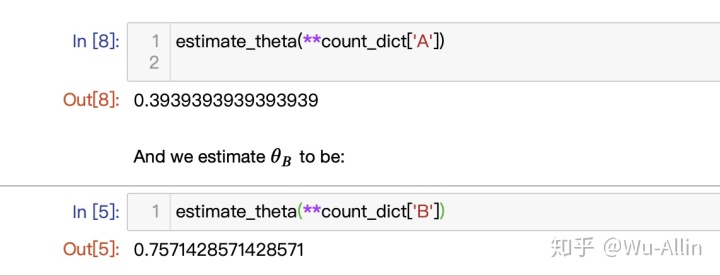
estimate_theta(**count_dict['A'])
estimate_theta(**count_dict['B'])结果如下:
似然函数的解析式:
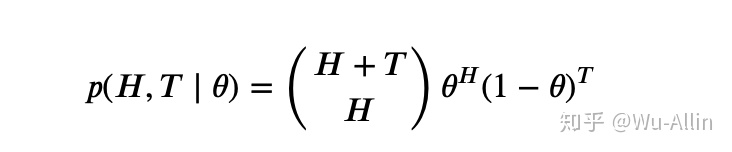
##似然函数
def likelihood_of_theta(theta, H, T):
return theta**H * (1 - theta)**T做一些可视化处理:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
counts = count_dict['A']
H = counts['H']
T = counts['T']
theta = np.linspace(0, 1, 300)
theta_likelihood = likelihood_of_theta(theta, H, T)
# compute maximum likelihood estimate
m = estimate_theta(H, T)
m_likelihood = likelihood_of_theta(m, H, T)
# plot
plt.rcParams['figure.figsize'] = (15, 5)
plt.plot(theta, theta_likelihood, color='b');
plt.vlines(m, 0, m_likelihood, 'b', '--');
plt.title(r'Likelihood of $theta$ given {} heads and {} tails'.format(H, T), fontsize=17);
plt.ylabel(r'$L(theta mid H,T)$', fontsize=15);
plt.xlabel(r'$theta$', fontsize=15);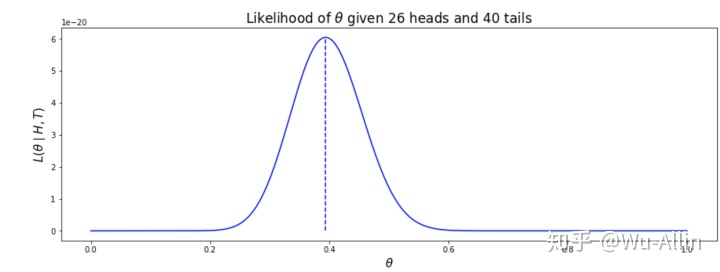
以上即为极大似然求解过程,下面引入隐变量,利用EM算法求解。
步骤:
1.初始化参数
2.E步,期望最大化
3.M步迭代
4.重复2-3直至收敛
代码如下:
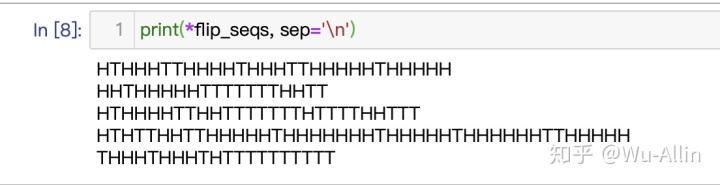
上面观测序列存在有 隐变量。
E步:求期望
def expected_counts(counter, weight):
"""
Adjust the counts in the counter dictionary
by multiplying them by a weight value.
N.B. counts may not be integer values after
weighting is applied.
"""
return Counter({k: v*weight for k, v in counter.items()})EM算法代码主要部分:
# count the number of heads and tails in each sequence of coin flips
counts_for_seqs = [Counter(seq) for seq in flip_seqs]
# 1. Make initial estimates for each parameter
theta_A = 0.35
theta_B = 0.60
ITER = 10 # number of iterations to run EM for
for index in range(0, ITER+1):
print('{}ttheta_A: {:.5f}ttheta_B: {:.5f}'.format(index, theta_A, theta_B))
## Expectation step
## ----------------
# 2. How likely are the current estimates of theta to produce H heads and T tails for each sequence?
l_A = [likelihood_of_theta(theta_A, **counts) for counts in counts_for_seqs]
l_B = [likelihood_of_theta(theta_B, **counts) for counts in counts_for_seqs]
# 3. Normalise these likelihoods so that they sum to 1, call them 'weights'
weight_A = [a / (a+b) for a, b in zip(l_A, l_B)]
weight_B = [b / (a+b) for a, b in zip(l_A, l_B)]
# expected counts of heads/tails for sequences of coin flips given weights
exp_counts_A = [expected_counts(counts, w) for counts, w in zip(counts_for_seqs, weight_A)]
exp_counts_B = [expected_counts(counts, w) for counts, w in zip(counts_for_seqs, weight_B)]
## Maximisation step
## -----------------
# 4. Find total number of heads/tails across the sequences of coin flips
total_A = sum(exp_counts_A, Counter())
total_B = sum(exp_counts_B, Counter())
# compute new parameter estimates for theta
theta_A = estimate_theta(**total_A)
theta_B = estimate_theta(**total_B)结果如下:

下面对真实值和EM算法预测值,对比:
from IPython.display import Markdown
actual_A = estimate_theta(**count_dict['A'])
actual_B = estimate_theta(**count_dict['B'])
md = r"""
| | Actual | EM estimate |
| ---------- |:---------------| :------------ |
| $theta_A$ | {actual_A:.5f} | {em_A:.5f} |
| $theta_B$ | {actual_B:.5f} | {em_B:.5f} |
"""
Markdown(
md.format(
actual_A=actual_A,
actual_B=actual_B,
em_A=theta_A,
em_B=theta_B,
)
)对比结果如下:
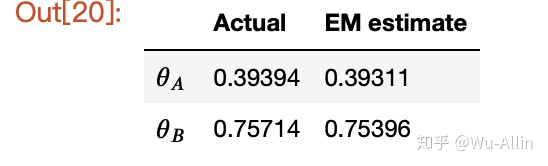
当然你也可以,选择不同
这里给出5组初始化值以供参考和调试:
参考文献:
1.《统计学习方法》 李航;
2.Do C B , Batzoglou S . What is the expectation maximization algorithm?[J]. Nature Biotechnology, 2008, 26(8):897-899.















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









