








导读:本文内容较长,较为详细的阐述了进行时间序列预测的步骤,有些内容可能暂时用不到或者看不懂,但不要紧,知道有这么一个概念,后续碰到的时候,继续深入学习以及使用就可以。
作者:Leandro Rabelo
译者:李洁
整理:Lemonbit
来源:Python数据之道(ID:PyDataRoad)
 ▲Photo by Adrian Schwarz on Unsplash
▲Photo by Adrian Schwarz on Unsplash
我们被随处可见的模式所包围,人们可以注意到四季与天气的关系模式,以交通量计算的交通高峰期的模式,你的心跳或者是股票市场和某些产品的销售周期。
分析时间序列数据对于发现这些模式和预测未来非常有用。有几种方法可以创建这类预测,在本文中,我将介绍最基本且最传统的方法概念。
所有代码都是用 Python 编写的,并且在 GitHub 上可以看到所有的信息。
https://nbviewer.jupyter.org/github/leandrovrabelo/tsmodels/blob/master/notebooks/english/Basic Principles for Time Series Forecasting.ipynb
那么让我们开始谈谈分析时间序列的初始条件:
01 平稳序列
平稳时间序列是指统计特性,如均值、方差和自相关系数,随时间相对恒定的序列。因此,非平稳序列是统计特性随时间变化的序列。在开始任何预测建模之前,都有必要验证这些统计属性是否是常量,我将一一解释下面的每个点:
常数均值
常数方差
自相关
1. 常数均值
一个平稳序列在时间上具有一个相对稳定的均值,这个值没有减少或者增加的趋势。围绕常数均值的小的变化,使我们更容易推测未来。在某些情况下,相对于平均值的变量比较小,使用它可以很好地预测未来。下图显示了变量与该常数平均值相对于时间变化的关系:
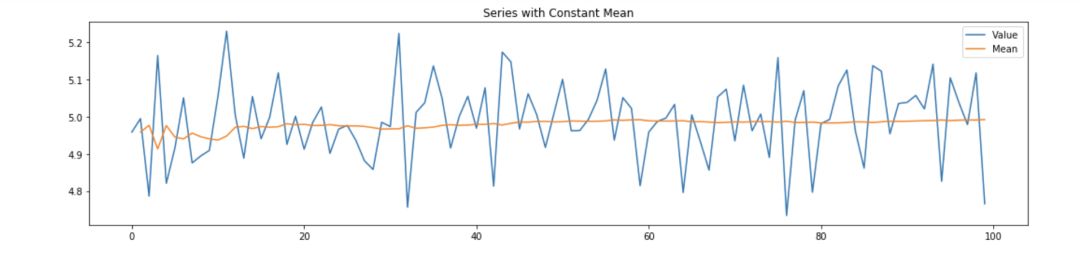
在这种情况下,如果序列不是平稳的,对未来的预测将是无效的,因为平均值周围的变量会显著偏离,如下图所示:
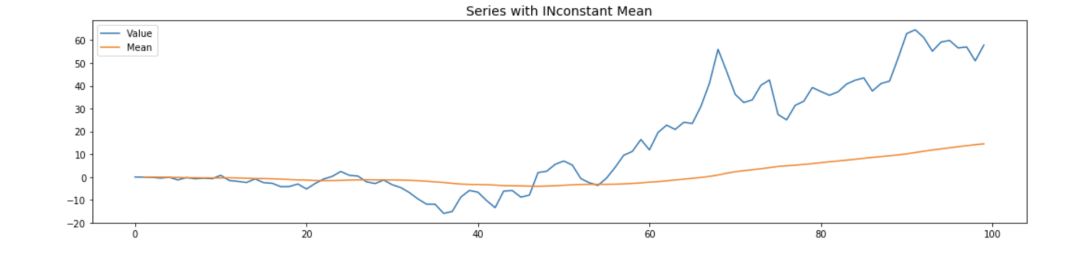
在上图中,我们可以明显看到上升的趋势,均值正在逐渐上升。在这种情况下,如果使用均值进行未来值的预测,误差将非常大,因为预测价格会总是低于实际价格。
2. 常数方差
当序列的方差为常数时,我们知道均值和标准差之间存在一种关系。当方差不为常数时(如下图所示),预测在某些时期可能会有较大的误差,而这些时期是不可预测的。可以预测到,随着时间的推移直到未来,方差会保持不稳定。
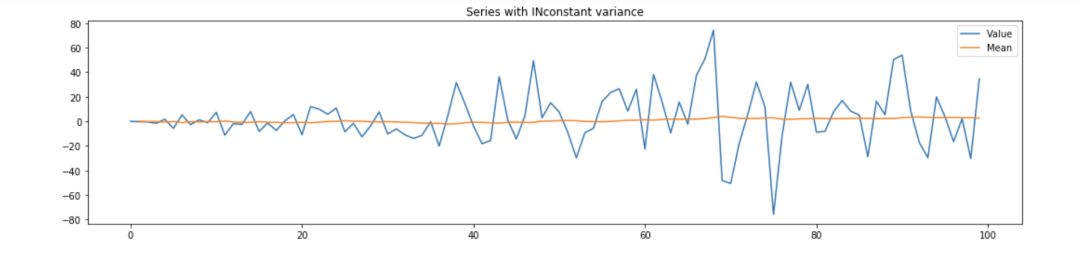
为了减小方差效应,可以采用对数变换。在本例中,也可以使用指数变换,如 Box-Cox 方法,或者使用膨胀率调整。
3. 自相关序列
当两个变量在时间上的标准差有相似的变化时,你可以说这些变量是相关的。例如,体重会随着心脏疾病而增加,体重越大,心脏问题的发生率就越大。在这种情况下,相关性是正的,图形应该是这样的:
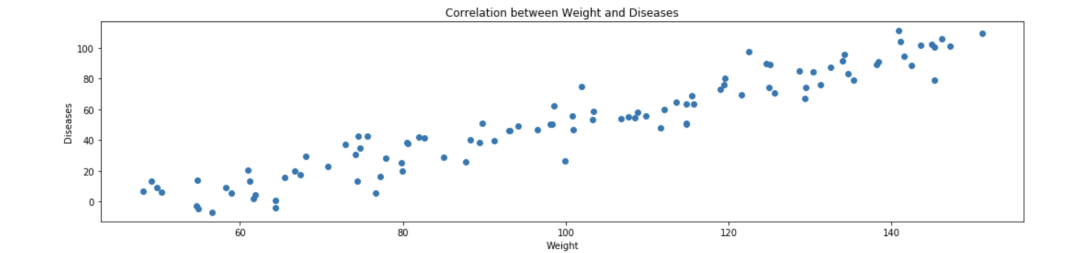
负相关的情况类似于这样:对工作安全措施的投入越多,工作相关的事故数量就越少。下面是几个相关级别的散点图的例子:
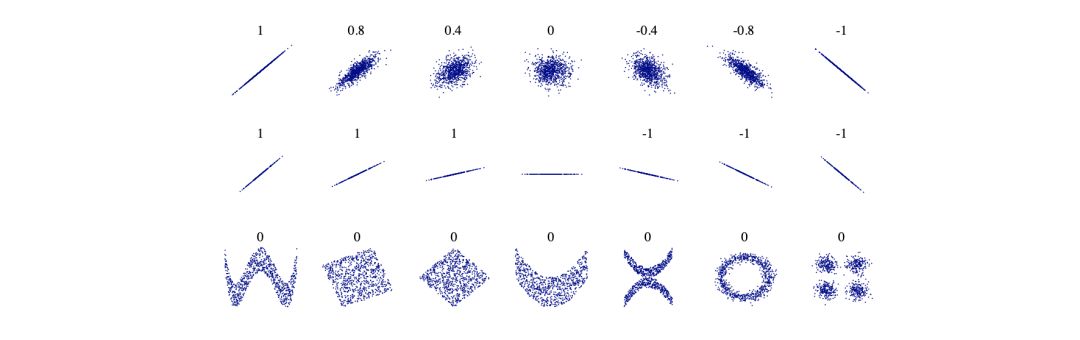
当谈到自相关时,意思是某些先前时期与当前时期存在相关性,这种相关性是滞后的。例如,在以小时为单位的测量值序列中,今天 12:00 的温度与 24 小时前的 12:00 的温度非常相似。如果你比较 24 小时内的温度变化,就会存在自相关,在本例中,我们将与第 24 小时前的时间存在自相关关系。
自相关是使用单个变量创建预测的一种情况,因为如果没有相关性,就不能使用过去的值来预测未来;当有多个变量时,则可以验证因变量和独立变量的滞后之间是否存在相关性。
如果一个序列不存在自相关关系,那么它就是随机且不可预测的,做预测的最佳方法通常是使用前一天的值。我将在下面使用更详细的图表来解释。
从这里开始我将分析 Esalq 上的每周含水乙醇价格(这是巴西谈判含水乙醇的价格参考),数据可以在这里下载:
https://www.cepea.esalq.usp.br/br/indicador/etanol.aspx
价格单位是巴西雷亚尔每立方米(BRL/m3)。在开始任何分析之前,要将数据划分为训练集和测试集。
4. 划分训练集和测试集数据
当我们要创建时序预测模型时,将数据划分为两部分至关重要:
训练集:这些数据将是定义模型系数/参数的主要依据;
测试集:这些数据将被分离且对模型不可见,用于测试模型是否有效(通常将这些值与模型结果进行比较,最后测量平均误差)。
测试集的大小通常约为总样本的20%,尽管这个百分比取决于你拥有的样本大小以及你希望提前多少时间进行预测。理想情况下,测试集应至少与所需预测的最大范围相同。
与其他如分类和回归等不受时间影响的预测方法不同,在时间序列中,不可以将训练和测试数据从数据中随机抽样取出,我们必须遵循序列的时间标准,训练数据应该始终是在测试数据之前。
在本例中,我们有Esalq 含水乙醇的 856 周的价格数据,使用前 700 周的数据作为训练集,后 156 周(3年,18%)的数据用作测试集:
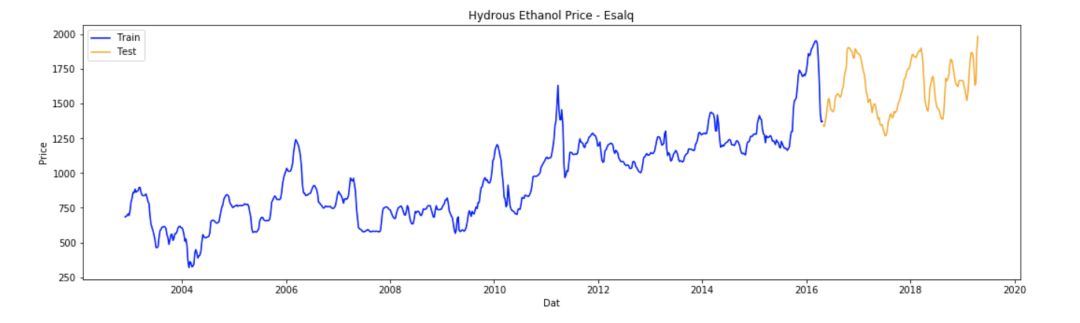
从现在开始,我们只使用训练集来做研究,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









