










记录一下从数据获取到做出符合需求的2d检测模型的全过程,记录一共分为四个章节.其中
- 第一个章节讲如何通过fiftyone工具获取到常用的计算机视觉数据集;
- 第二个章节讲如何对图片进行格式转换
- 第三个章节讲yolov5的简单训练
- 第四个章节yolov5 训练经验记录
使用的数据集是Open images v6,如果使用不同的数据集可能在第二章节需要用其他代码对数据进行转换。coco 和 voc数据可以直接使用data中的yolo.yaml 和coco.yaml进行训练
fiftyone
简介
fiftyone是一款用于构建高质量数据集和计算机视觉模型的开源工具.这款工具不仅仅可以用来加载数据,还能用来评估模型性能,查找注释错误等等
想要了解更多关于fiftyone可以点击这里
安装
创建一个虚拟环境并安装 fiftyone
mkdir Fiftyone_Yolov5
cd Fiftyone_Yolov5
conda create -n Fiftyone_Yolov5 python=3.8
conda activate Fiftyone_Yolov5
conda install jupyter notebook
pip install fiftyone # 安装数据集的API
选择需要下载的数据集
首先导入 fiftyone 中的数据zoo。
import fiftyone as fo
import fiftyone.zoo as foz
help(foz)
需要根据你需要的实际需求设置数据的下载参数。
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="train",
classes=["Table","Human hand","Human head","Person"],
max_samples=100000,
shuffle=True,
only_matching=True,
label_types=["detections"], # 指定下载目标检测的类型,detections,
dataset_dir="./OpenImageV6_20220921",# 保存的路径
num_workers=4, # 指定工作进程数
)
foz.load_zoo_dataset 参数简介
- 填写你需要数据集的名称(字符串类型)
- split 指定要加载的分段。支持的值是’ (“train”, “test”, “validation”) '(字符串类型)
- classes 选择你需要的检测的对象的类别。(字符串或list类型)
NOTE: 类别字符串一定要与数据集的类别名称一致,如果不确定可以自行百度或者google一下数据集的类别。注意大小写。 - max_samples 要加载的样本的最大数量。(int类型)
- only_matching 是否只加载与您提供的’ classes ‘或’ attrs '需求匹配的标签(True),还是加载与需求匹配的样本的所有标签(False)
- num_workers 使用的进程数,默认使用multiprocessing.cpu_count()返回的cpu数量
- shuffle 是否打乱下载数据的顺序
- include_id 是否加载标签中包含某个样本的标签
- image_ids 指定需要加载的图像的id
- seed 随机种子
- attrs 指定需要加载的关系属性的字符串或字符串列表。此参数仅适用于“label_type”包含“relationships”的情况。
foz.load_zoo_dataset 参数官方文档
API参数可以参考这个文档进行自定义。
文档右边可以选择你需要的数据集进行下载。往下拉可以看到所有可以选择的参数。
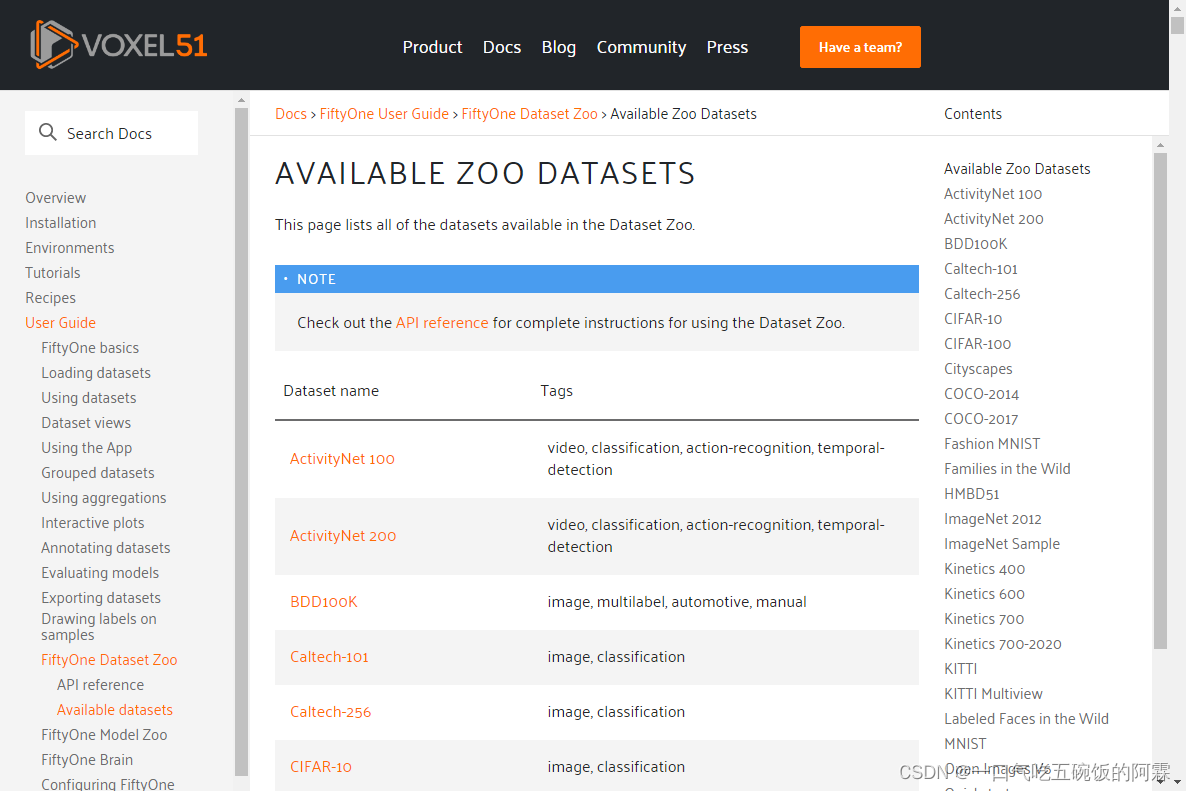
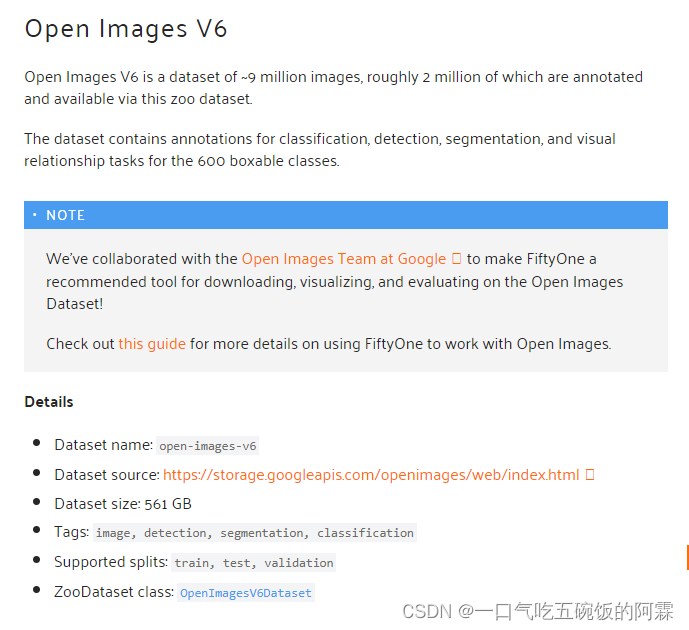

图片注释格式转换
经过第一章节,我们已经拿到了我们需要的数据集,但是由于注释格式的不同我们无法直接输入yolov5进行使用,这一章节我们通过open images v6 的数据进行演示,如何将OIDv6的数据格式转换成yolo txt的数据格式。
转换分为两步: oidv6格式到voc ; voc 到 yolo txt 。
OIDv6 >> voc
这一步骤使用了这个python工具包–(oidv6-to-voc)
安装 oidv6-to-voc
pip install oidv6-to-voc
使用 oidv6-to-voc 工具进行转换
oidv6-to-voc <annotation-file(s).csv>
-d <class-names-file.csv>
--imgd <directory/to/your/images>
--outd <your/output/diretory>
其中annotation-file(s).csv 可以在数据保存路径下的labels/文件夹中找到 detections.csv

class-names-file.csv 可以在下一小节中下载
<directory/to/your/images> 数据集的图片路径
<your/output/diretory> 转换成voc之后的注释保存路径
下载需要的标注文件
点击进入这个网页https://storage.googleapis.com/openimages/web/download.html

其中 红色框内的表示annotation-file(s).csv文件,open images 将其数据分割成了 train validation test
绿色框内的表示 class-names-file.csv 下载完直接使用即可
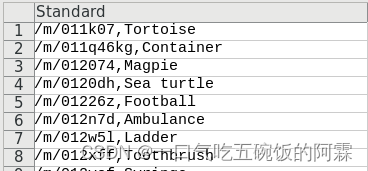
NOTE:
其中第1列代表的是open images 的类别id(这个不是给一般人看的),第2列代表的是类别id所对应的英文名字(你可以在其中找一下有没有你需要的类别)
VOC >> YOLO TXT
使用python实现格式转换
以下代码主要参考了这篇博客
首先导入我们所需要的数据包
import xml.etree.ElementTree as ET
import glob
import os
import json
导入两个函数
def xml_to_yolo_bbox(bbox, w, h):
# xmin, ymin, xmax, ymax
x_center = ((bbox[2] + bbox[0]) / 2) / w
y_center = ((bbox[3] + bbox[1]) / 2) / h
width = (bbox[2] - bbox[0]) / w
height = (bbox[3] - bbox[1]) / h
return [x_center, y_center, width, height]
def yolo_to_xml_bbox(bbox, w, h):
# x_center, y_center width heigth
w_half_len = (bbox[2] * w) / 2
h_half_len = (bbox[3] * h) / 2
xmin = int((bbox[0] * w) - w_half_len)
ymin = int((bbox[1] * h) - h_half_len)
xmax = int((bbox[0] * w) + w_half_len)
ymax = int((bbox[1] * h) + h_half_len)
return [xmin, ymin, xmax, ymax]
依次填入类别名称、VOC格式的注释文件所在目录,你想要输出YOLO TXT格式的注释文件所在目录、图片目录
classes = []
input_dir = "annotations/"
output_dir = "labels/"
image_dir = "images/"
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
这是注释格式转换的主要代码
files = glob.glob(os.path.join(input_dir, '*.xml'))
for fil in files:
basename = os.path.basename(fil)
filename = os.path.splitext(basename)[0]
if not os.path.exists(os.path.join(image_dir, f"{filename}.jpg")):
print(f"{filename} image does not exist!")
continue
files = glob.glob(os.path.join(input_dir, '*.xml'))
result = []
tree = ET.parse(fil)
root = tree.getroot()
width = int(root.find("size").find("width").text)
height = int(root.find("size").find("height").text)
for obj in root.findall('object'):
label = obj.find("name").text
if label not in classes:
classes.append(label)
index = classes.index(label)
pil_bbox = [int(x.text) for x in obj.find("bndbox")]
yolo_bbox = xml_to_yolo_bbox(pil_bbox, width, height)
bbox_string = " ".join([str(x) for x in yolo_bbox])
result.append(f"{index} {bbox_string}")
if result:
with open(os.path.join(output_dir, f"{filename}.txt"), "w", encoding="utf-8") as f:
f.write("\n".join(result))
记录一下类别
with open('classes.txt', 'w', encoding='utf8') as f:
f.write(json.dumps(classes))
Yolov5的训练
yolov5 训练前的准备工作
下载yolov5项目代码并安装需要的运行环境(最好在虚拟环境下运行)
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
移动数据集到指定位置
在yolov5的目录下创建一个datasets文件夹用以装载训练和测试数据

其中 images 装载图片训练和验证的数据分别装在train和val文件夹下
labels同理装载注释数据的txt文件
修改model的配置文件(yaml)
在data目录下创建一个关于自己数据的yaml文件 比如customerData.yaml
train: ./datasets/images/train # 在这里写上训练路径
val: ./datasets/images/val # 在这里写上测试路径
nc: 3 # 写上你的种类数量
names: ["car","person","human face"]
修改data的配置文件(yaml)
进入models文件夹 选择你想要的yolov5模型,我们以yolov5l.yaml 为例,将文件中的nc: 80 改为你的类别数目。比如 如果你需要检测car、person、cycline三类 就写一个3。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov5 的训练参数
改好之后就可以开始训练了
python3 train.py --img-size 640 \ # 图片的size大小 需要注意的是必须要是32的倍数,常用的有640 1280 1440
--batch-size 16 \
--epochs 300 \
--data ./data/customerData.yaml \ # 数据配置文件
--cfg ./models/yolov5l.yaml \ # 模型配置文件
--weights weights/yolov5l.pt \ # yolo 会自动下载不用管
--device 0,1 # 使用电脑的GPU下标
其他可选参数简介:
- –evolve {num} 使用yolo自带的进化算法调整模型超参数(num为训练的代数3)
- –multi-scale 随机调整 imgsz的大小 调整范围为 “±50%”
- –workers {num} 多进程设置(num 为需要设定的进程数)
- –cache 将数据提前加载到内存
- –hyp xxx.yaml 手动调整模型和数据增强的超参数
- –optimizer 模型优化器选择,默认 SGD,可从这三个里面进行选择[‘SGD’, ‘Adam’, ‘AdamW’]
- –image-weights 测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
可参考一下链接,如果有参数名称找不到,需要自行查看一下train.py文件中的keyword ,名字可能有所改动。(列如:–cache-images 更改为了 --cache)
NOTE: 当使用 --multi-scale 参数时 需要预留足够的GPU显存,不然会导致GPU内存溢出。
yolov5 训练经验记录
数据增强超参数调整:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Hyperparameters for high-augmentation COCO training from scratch
# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 90.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.5 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.2 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.3 # image mixup (probability)
copy_paste: 0.1 # segment copy-paste (probability)
数据集中出现图片注释不完善
这个问题应该是open image 这个数据集特有的,暂时没在其他数据集上发现。
问题如下,比如我需要检测 人脸 人眉毛和人这三类。但是有些图片中明明有人脸和人的眉毛,数据集却并没有该类的标记,而是仅仅只标记了人出来,这就会导致模型在训练的时候,明明图片中有一个人的眉毛并且模型可以将其识别出来,但是由于没有这个注释导致进行loss计算的正确答案是背景类(而不是眉毛类)。因此噪音多了就会让模型无法学习到真正的眉毛。
其他
yolov5 的模型检测命令
python detect.py --source
--weights
--imgsz 1280
--conf-thres 0.05
--iou-thres 0.05
--data ./data/customerData.yaml
--save-txt














 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









