







目录
首先 看篇文章我的目的是为了找到一种方法可以适用于单目标的多维特征数据的时间预测 。
1 文章来源链接
https://arxiv.org/pdf/2001.08317.pdf
2 Abstract
In this paper, we present a new approach to time series forecasting. Time series data are preva- lent in many scientific and engineering disciplines. Time series forecasting is a crucial task in mod- eling time series data, and is an important area of machine learning. In this work we developed a novel method that employs Transformer-based machine learning models to forecast time series data. This approach works by leveraging self- attention mechanisms to learn complex patterns and dynamics from time series data. Moreover, it is a generic framework and can be applied to univariate and multivariate time series data, as well as time series embeddings. Using influenza- like illness (ILI) forecasting as a case study, we show that the forecasting results produced by our approach are favorably comparable to the state- of-the-art.
在这篇文章中,我们提出了时间序列预测的新方法。时间序列数据在许多科学和工程学科中都是流行的。时间序列预测是模组时间系列数据中的一项重要任务,是机器学习的重要领域。在这项研究中,我们开发了一种新方法,它采用基于transformer的机器学习模型来预测时间序列数据。此方法通过利用self-attention 机制从时间系列数据中学习复杂的模式和动态来工作。此外,它是一个通用的框架,可以应用于单变体和多变量时间系列数据,以及时间系列嵌入。以流感样疾病 (ILI) 预测为案例研究,我们表明,我们的方法产生的预测结果与最先进的预测结果非常相似。
这里我想要了解两个问题 第一个问题是deep transformer的结构, 第二个问题是这篇文章说和sota模型预测结果相似,它是对比了哪种sota模型
3 Introduction
这里主要看一下作者总结的关于这篇文章的贡献。
influenza- like illness (ILI)
Our contributions are the following:
• We developed a general Transformer-based model for time series forecasting.
• We showed that our approach is complementary to state space models. It can model observed data. Using embeddings as a proxy, our approach can also model state variables and phase space of the systems.
• Using ILI forecasting as a case study, we demonstrated that our Transformer-based model is able to accurately forecast ILI prevalence using a variety of features.
• We showed that in the ILI case our Transformer-based model achieves state-of-the-art forecasting results.
我们的贡献如下:
我们为时间序列预测开发了一个基于transformer的通用模型。
我们展示了我们的方法是对状态空间模型的补充,它可以对观测到的数据建模。使用嵌入作为代理,我们的方法还可以对系统的状态变量和相位空间进行建模。
我们使用 ILI 预测作为案例研究,证明基于变形金刚的模型能够使用多种功能准确预测 ILI 流行率。
我们展示了在 ILI 案例中,基于transformers 的模型实现了最先进的预测结果。
4 Dataset
We utilized country- and state-level historical ILI data from 2010 to 2018 from the CDC (CDC).
数据来源:我們利用了 CDC (CDC) 2010 年至 2018 年的國家和州級歷史 ILI 數據。
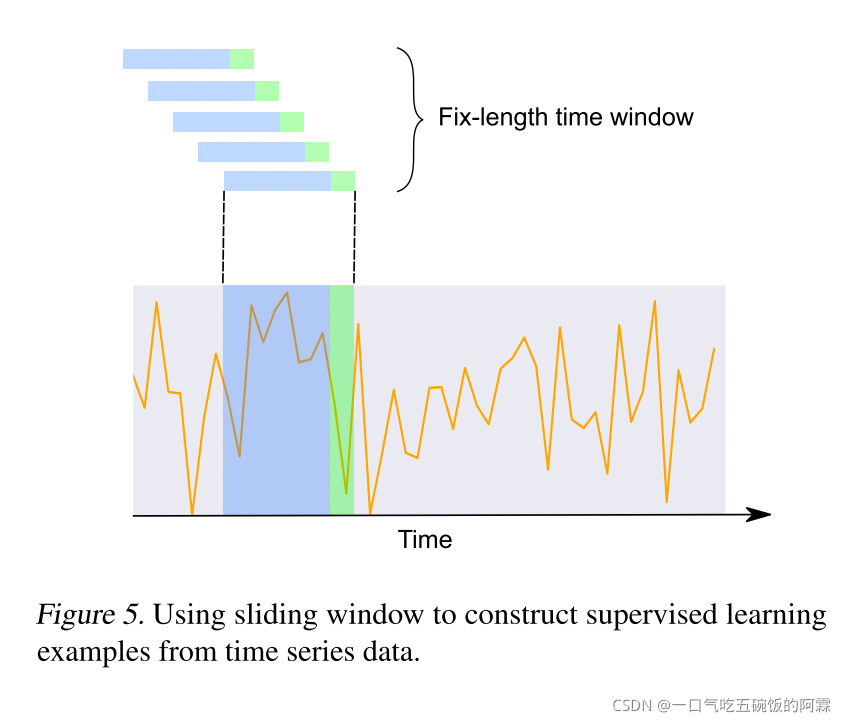
To produce a labeled dataset, we used a fixed-length sliding time window approach (Figure 5) to construct X, Y pairs for model training and evaluation. Before applying the sliding window to get features and labels, we perform min-max scaling on all the data with the maximum and minimum val- ues of training dataset. We then run a sliding window on the scaled training set to get training samples with features and labels, which are the previous N and next M observations respectively. Test samples are also constructed in the same manner for model evaluation. The train and test split ratio is 2:1. Training data from different states are concatenated to form the training set for the global model.
首先 对数据进行 (min-max normalization)离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:其中max为样本数据的最大值,min为样本数据的最小值。
然后构造数据集。数据集构造是通过一个固定的时间窗口用相同的步长获取数据,拿其中一个样本举例子,假设数据样本为s1,s2.数据样本是 t1,t2,t3,t4,t5,t6,t7,....。那么s1的特征就是 t1,t2,t3,t4,t5堆叠起来,然后用于预测t6的y。s2 就是 t2,t3,t4,t5,t6堆叠起来,然后用于预测t7的y,以此类推。
最后提一句 数据集的训练集和测试集的比例是 2:1 。
5 Model
Transformers
编码器(Encoder)
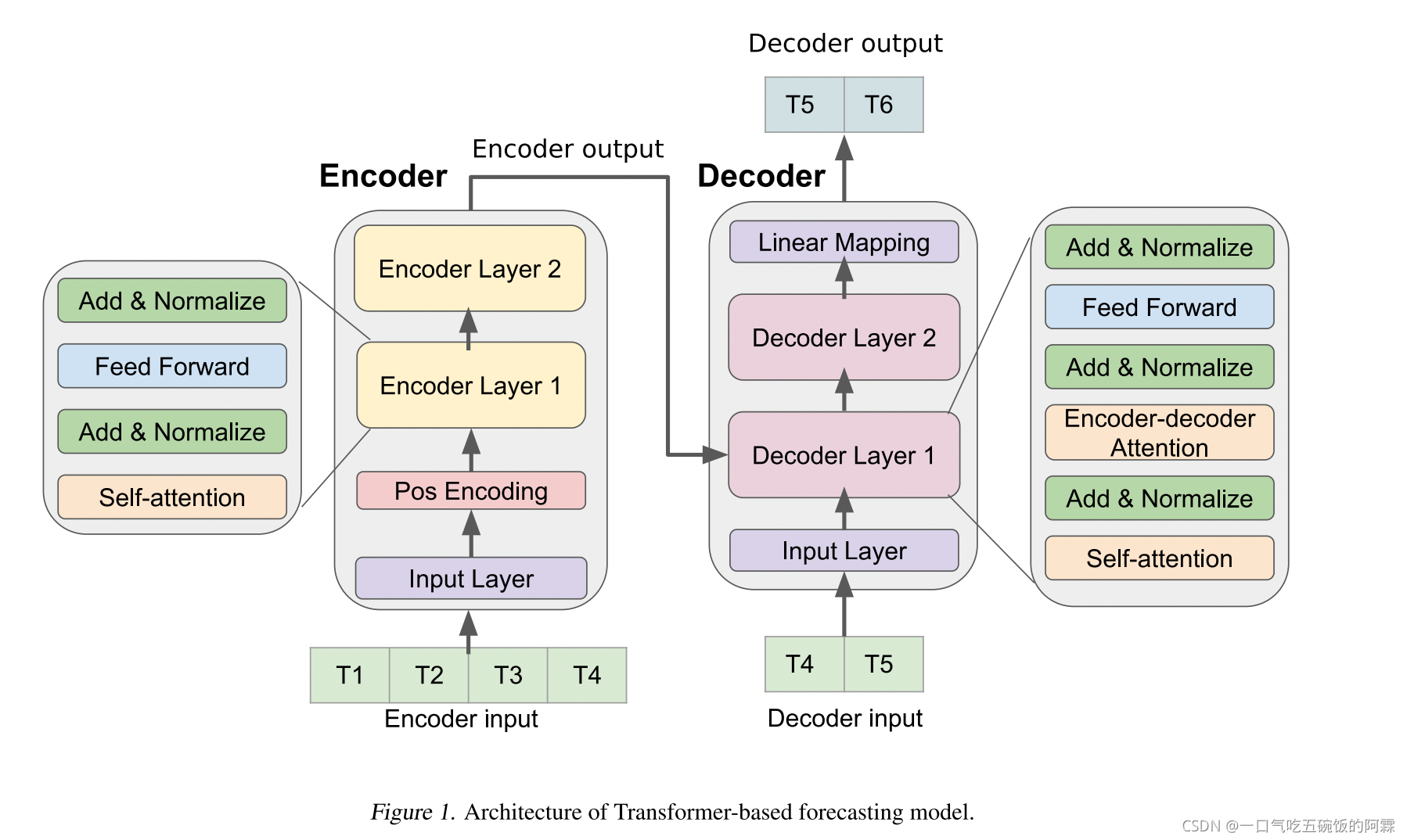
Encoder The encoder is composed of an input layer, a po- sitional encoding layer, and a stack of four identical encoder layers. The input layer maps the input time series data to a vector of dimension dmodel through a fully-connected net- work. This step is essential for the model to employ a multi- head attention mechanism. Positional encoding with sine and cosine functions is used to encode sequential informa- tion in the time series data by element-wise addition of the input vector with a positional encoding vector. The resulting vector is fed into four encoder layers. Each encoder layer consists of two sub-layers: a self-attention sub-layer and a fully-connected feed-forward sub-layer. Each sub-layer is followed by a normalization layer. The encoder produces a dmodel-dimensional vector to feed to the decoder.
编码器由输入层、Pos Encoding 层和四个相同的编码层组成。输入层通过全连接层的工作将输入时间序列数据映射到维度模组的载体中。这一步骤对于模型采用多头关注机制至关重要。具有正弦和 cosine 功能的位置编码用于通过添加具有位置编码载体的输入载体的元素来编码时间序列数据中的顺序信息。由此产生的向量被输入到四个编码器层中。每个编码器层由两个子层组成:一个self-attention 层和一个全连接的馈送子层。每个子层后面跟着一个Normalize 层。编码器产生一个模型向量送到解码器。
解码器(Decoder )
We employ a decoder design that is similar to the original Transformer architecture (Vaswani et al., 2017). The decoder is also composed of the input layer, four identi- cal decoder layers, and an output layer. The decoder input begins with the last data point of the encoder input. The input layer maps the decoder input to a dmodel-dimensional vector. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer to apply self- attention mechanisms over the encoder output. Finally, there is an output layer that maps the output of last decoder layer to the target time sequence. We employ look-ahead masking and one-position offset between the decoder input and tar- get output in the decoder to ensure that prediction of a time series data point will only depend on previous data points.
我们采用的解码器设计类似于原来的transformer架构(https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf)(很经典的文章 截止这篇博客已经有28689的引用了)。解码器由输入层、四个同位解码器层和一个输出层组成。解码器输入从编码器输入的最后数据点开始。输入层将解码器输入映射到模样维矢量。除了每个编码器层中的两个子层外,解码器还插入第三个子层,以便在编码器输出上应用自我注意机制。最后,有一个输出层,将最后解码器层的输出映射到目标时间序列。我们在解码器中的解码器输入和焦油输出之间采用向前看的遮盖和单位偏移,以确保时间系列数据点的预测仅取决于以前的数据点。
seq2seq-Attention
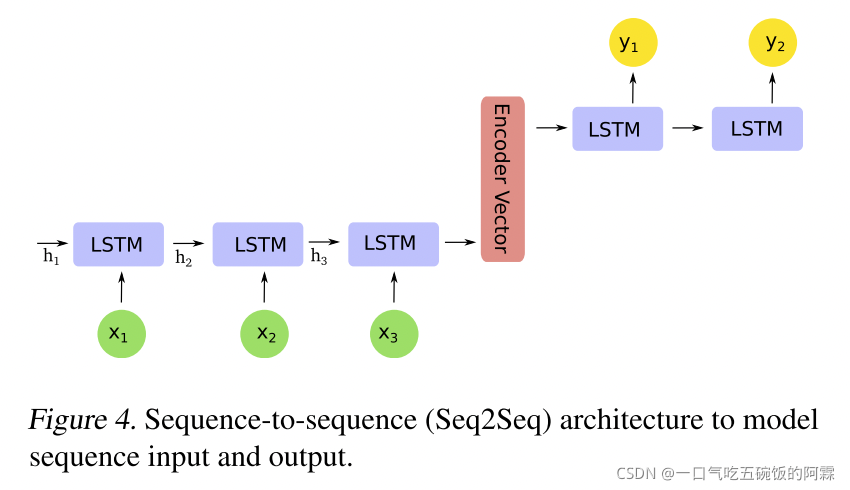
Seq2Seq Sequence-to-sequence (Seq2Seq) architecture is developed for machine learning tasks where both input and output are sequences. A Seq2Seq model is comprised of three components including an encoder, an intermediate vector, and a decoder. Encoder is a stack of LSTM or other recurrent units. Each unit accepts a single element from the input sequence. The final hidden state of the encoder is called the encoder vector or context vector, which encodes all of the information from the input data. The decoder is also made of a stack of recurrent units and takes the encoder vector as its first hidden state. Each recurrent unit computes its own hidden state and produces an output element. Figure 3.3 illustrates the Seq2Seq architecture.
Seq2Seq。
序列到序列 (Seq2Seq) 架构是为机器学习任务开发的,其中输入和输出都是序列。Seq2Seq 模型由三个组件组成,包括编码器、中间载体和解码器。编码器是 LSTM 或其他经常性单位的堆栈。每个单元接受输入序列中的单个元素。编码器的最终隐藏状态称为编码器向量或上下文向量,它对输入数据中的所有信息进行编码。解码器也由一叠经常性单位组成,并将编码器矢量作为其第一个隐藏状态。每个经常性单位计算自己的隐藏状态并生成输出元件。图 3.3 说明了 Seq2Seq 架构。
对于单步预测来说输入是序列 输出只是一个数字,所以运用的时候可能需要更改一下输出层。简单的加权可能是比较快速的方法?
6 Conclusions
In this work, we presented a Transformer-based approach to forecasting time series data. Compared to other sequence- aligned deep learning methods, our approach leverages self- attention mechanisms to model sequence data, and therefore it can learn complex dependencies of various lengths from time series data.
Moreover, this Transformer-based approach is a generic framework for modeling various non-linear dynamical sys- tems. As manifested in the ILI case, this approach can model observed time series data as well as phase space of state variables through time delay embeddings. It is also extensible and can be adpated to model both univariate and multivariate time series data with minimum modifications to model implementations.
Finally, although the current case study focuses on time series data, we hypothesize that our approach can be further extended to model spatio-temporal data indexed by both time and location coordinates. Self-attention mechanisms can be generalized to learn relations between two arbitrary points in spatio-temporal space. This is a direction we plan to explore in the future.
References
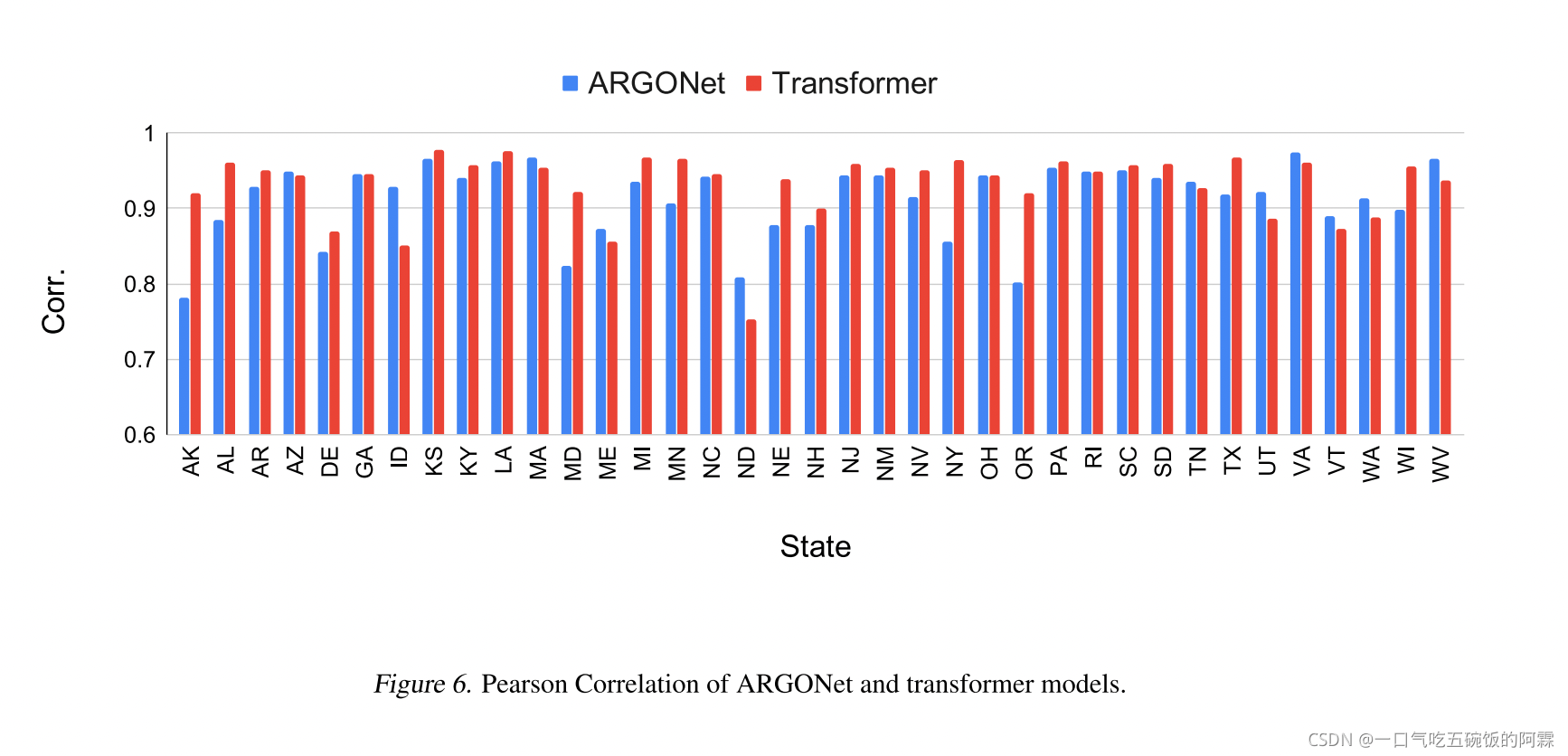
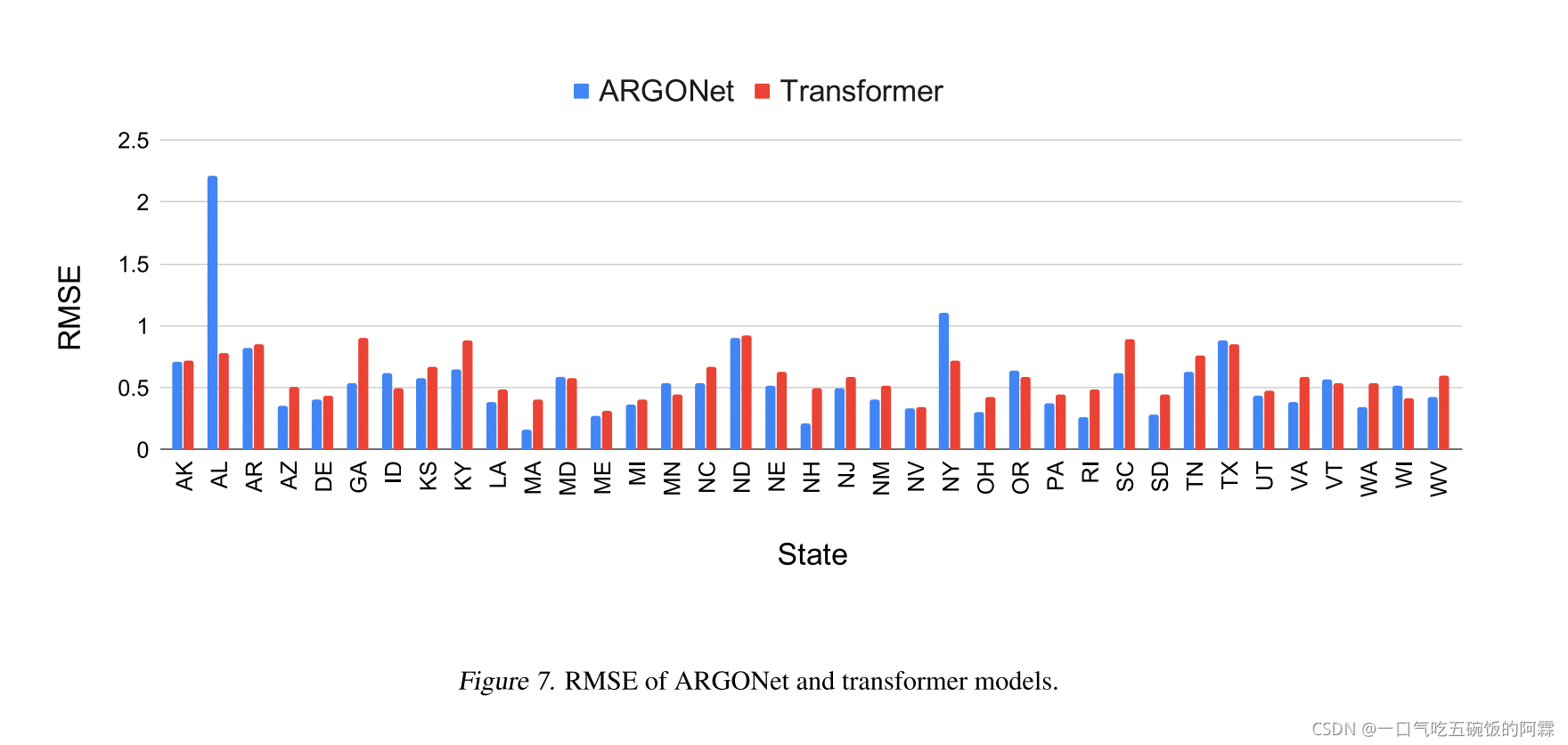
下面的图为transformer 和 ARGONet 的评估指标对比
We compared our results with the ILI forecasting data by ARGONet (Lu et al., 2019), a state-of-the-art ILI forecast- ing model in the literature. Figure 6 and figure 7 show the correlation and RMSE values of ARGONet and our transformer results. Overall, the Transformer-based model performs equally with ARGONet, with the mean correlation slightly improved (ARGONet: 0.912, Transformer: 0.931), and mean RMSE value slightly degraded (ARGONet: 0.550, Transformer: 0.593).
我们将结果与 ARGONet(https://www.nature.com/articles/s41467-018-08082-0.pdf)的 ILI 预测数据进行了比较,ARGONet 是文献中最先进的 ILI 预测模型。图 6 和图 7 显示了 ARGONet 和Transformer结果的相关性和 RMSE 值。总体而言,基于Transformer的模型与 ARGONet 性能相同,平均相关性略有提高(ARGONet: 0.912,变形金刚:0.931),平均 RMSE 值略有下降(ARGONet: 0.550,变形金刚:0.593)。

















 2289
2289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









