







Introduction
Google 又放出了一个大新闻:
就是如上的 Open Image 图像数据集,Google Research Blob 对这组数据集做了简单的介绍:Introducing the Open Images Dataset。
数据集的 Github 地址为:https://github.com/openimages/dataset
这约 900 万张的链接图像(基本来自 flickr),横跨了大约 6000 个类别,这些标签比 ImageNet(1000 类) 包含更多贴近实际生活的实体。这么大量的图像数据,足够保证从头训练一个深度网络模型。
这些图像数据遵从 Creative Commons Attribution license。但是 Google 在注释里注明,不保证每张图像都可以遵从这个规则去使用,需要你自己去验证:
While we tried to identify images that are licensed under a Creative Commons Attribution license, we make no representations or warranties regarding the license status of each image and you should verify the license for each image yourself.
图像的 labels 是 image-level,即 图像层级的,类似于 Google Cloud Vision API,即对于一张图像,分析出图像中包含的实体、场景、文字等,如下所示:
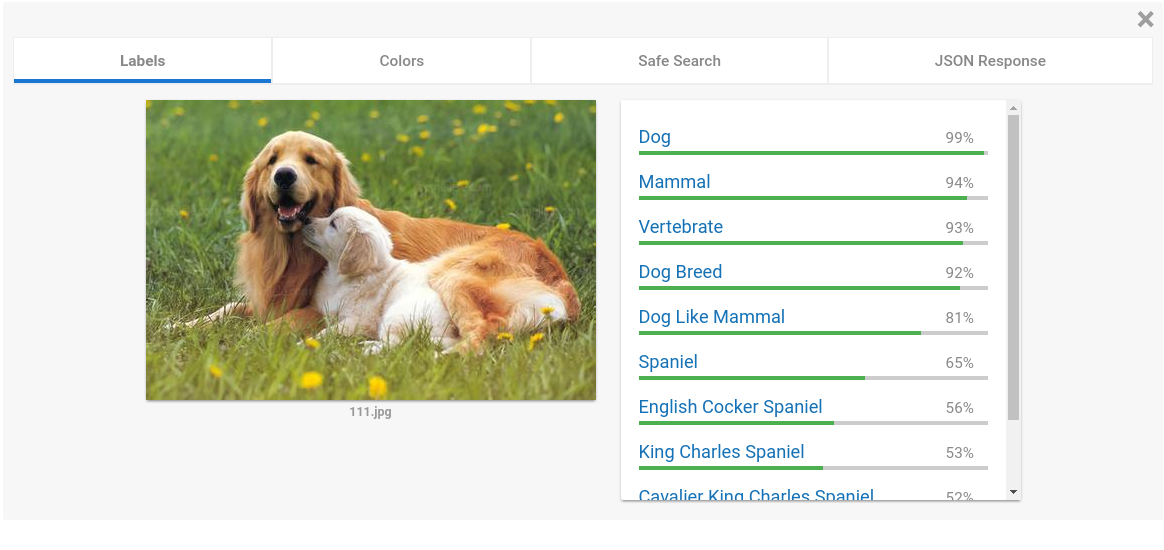
对于一张包含两只狗的图像而言,Google Cloud Vision API 分析出的 labels 包含:Dog(狗)、Mammal(哺乳动物)、Vertebrate(脊椎动物)等等。
这个 Google Cloud Vision API 非常强大,还可以检测自然场景文字检测:
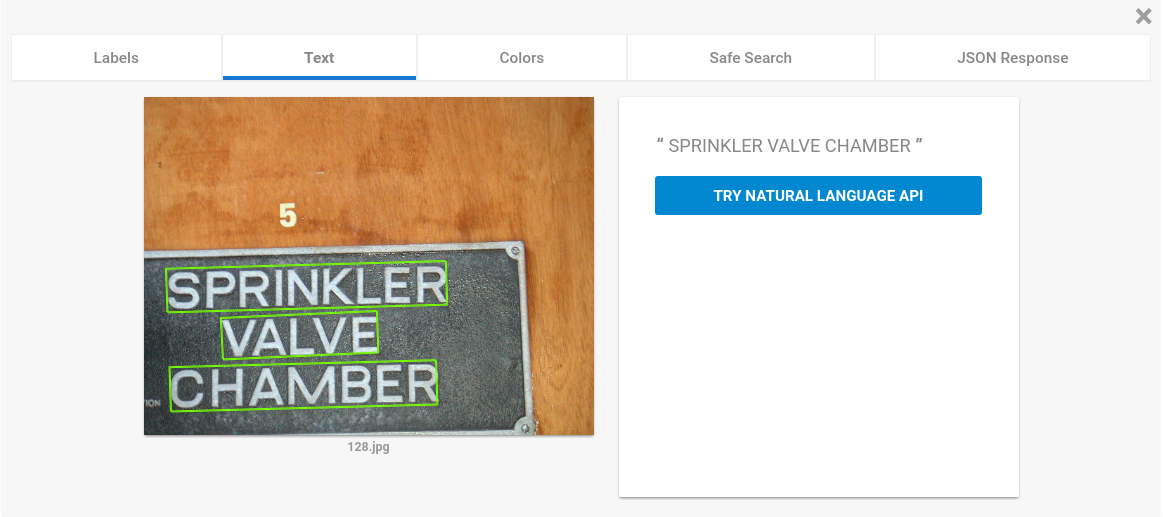
对于 Open Image dataset 中的 validation set,Google 对上面的这些 labels 进行了人工的检验,将错误的 labels 剔除掉了。每一张图像大约有 8 个 labels,示例如下:

Google 已经基于这个 Open Image 数据集训练了 Inception v3 model,这个 model 也可以用于去 fine-tuning 其他的任务,如 Deep Dream、artistic style transfer,在未来的几个月中,Google 还会继续提升 Open Image 的标注质量。
这个 Open Image 由 Google、CMU、Cornell 大学合作完成,这个 Open Image 数据集,以及最近放出的 Youtube-8M 对机器学习界又是一次助攻。
Data organization
每一张图像被赋予一个唯一的 64-bit 的标识码(ID),在 CSV 文件中,如 000060e3121c7305。
数据集被分为 training set,包含 9011219 张图像,validation set,包含 167057 张图像。每一张图像包含 0 个,1 个或者多个 image-level 的 labels。
数据集都是由机器标注的,其中,validation set 是经过人的检验的,但是在 Machine image-level annotations (train and validation sets) 中也包含了机器标注的 validation set。
images.csv 文件格式
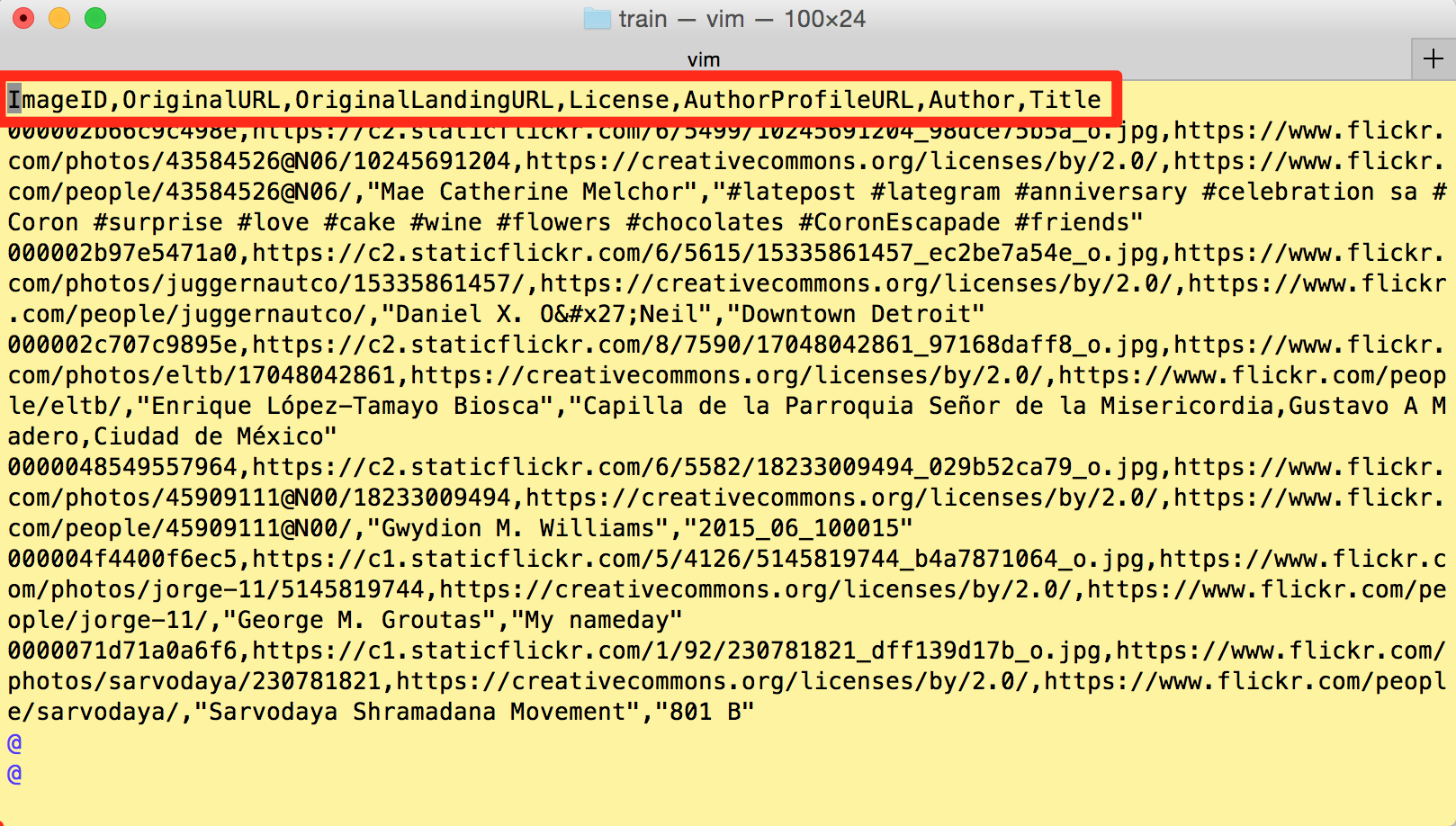
给的原图像地址文件格式,每一行包含了原图像 URL 地址,它们对应唯一的 ImageID、标题、作者,以及 license 信息:
ImageID,OriginalURL,OriginalLandingURL,License,AuthorProfileURL,Author,Title
…000060e3121c7305,”https://c1.staticflickr.com/5/4129/5215831864_46f356962f_o.jpg“,\
“https://www.flickr.com/photos/brokentaco/5215831864“,\
“https://creativecommons.org/licenses/by/2.0/“,\
“https://www.flickr.com/people/brokentaco/“,”David”,”28 Nov 2010 Our new house.”
打开看看,如下:
labels.csv 文件格式
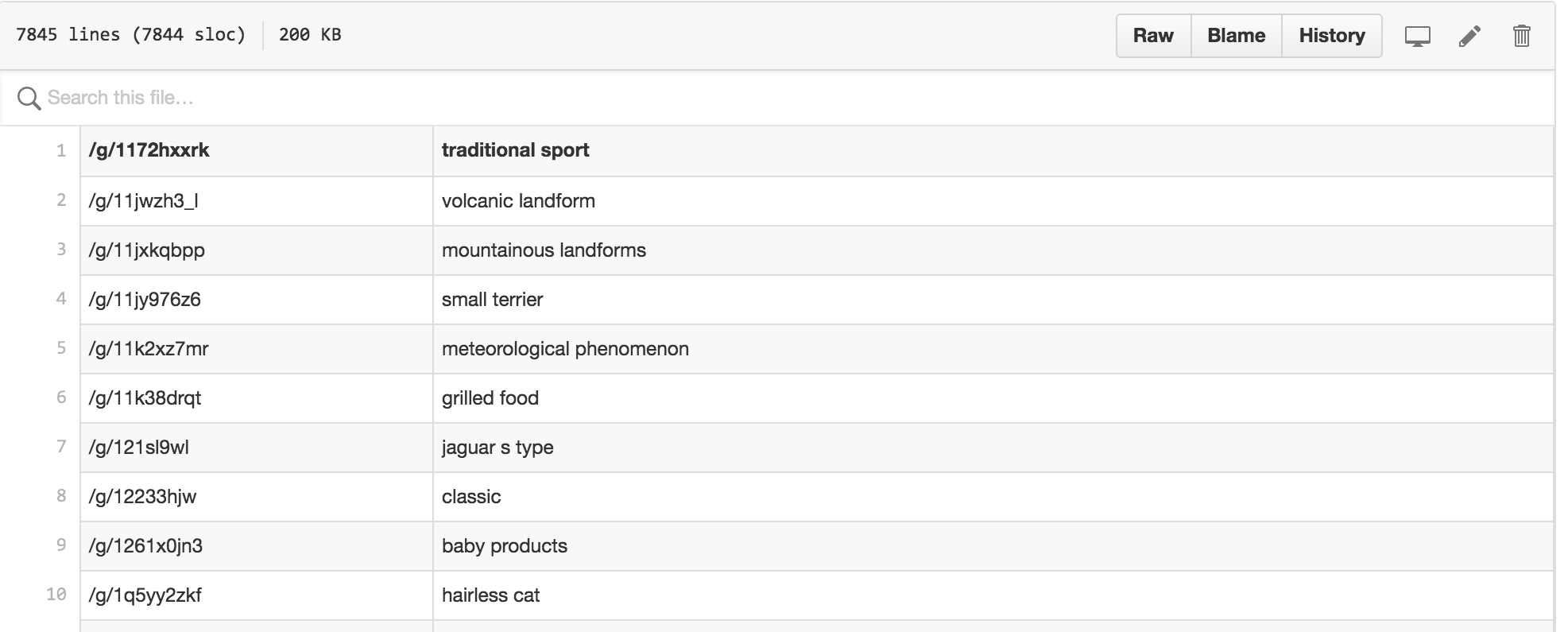
首先,labels 各自对应的单词含义,在 词典 dict.csv 里描述如下:
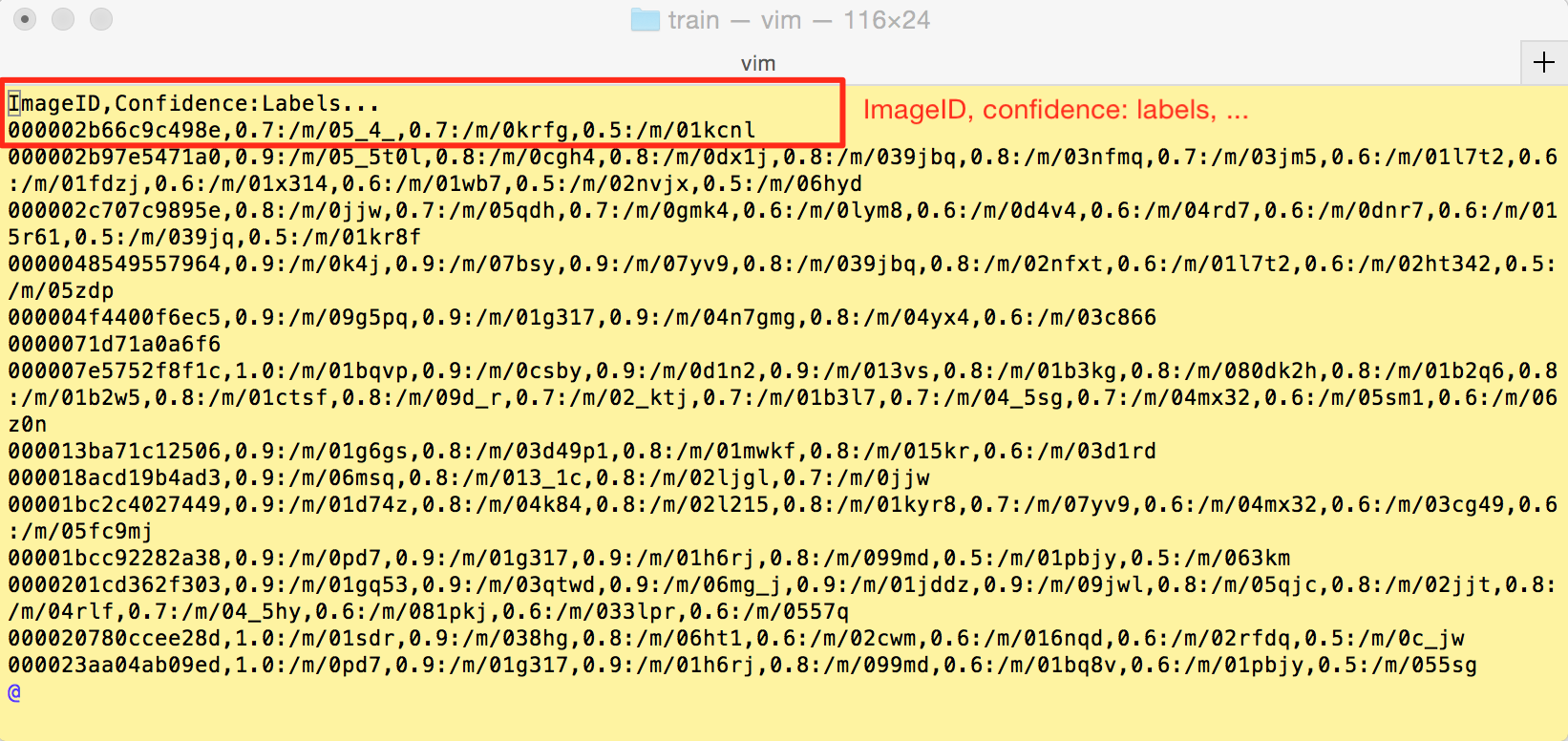
标注 annotation 的格式如下:ImageID, confidence: labels, confidence: labels, ……,下面分别是 train、validation 的 csv 文件:
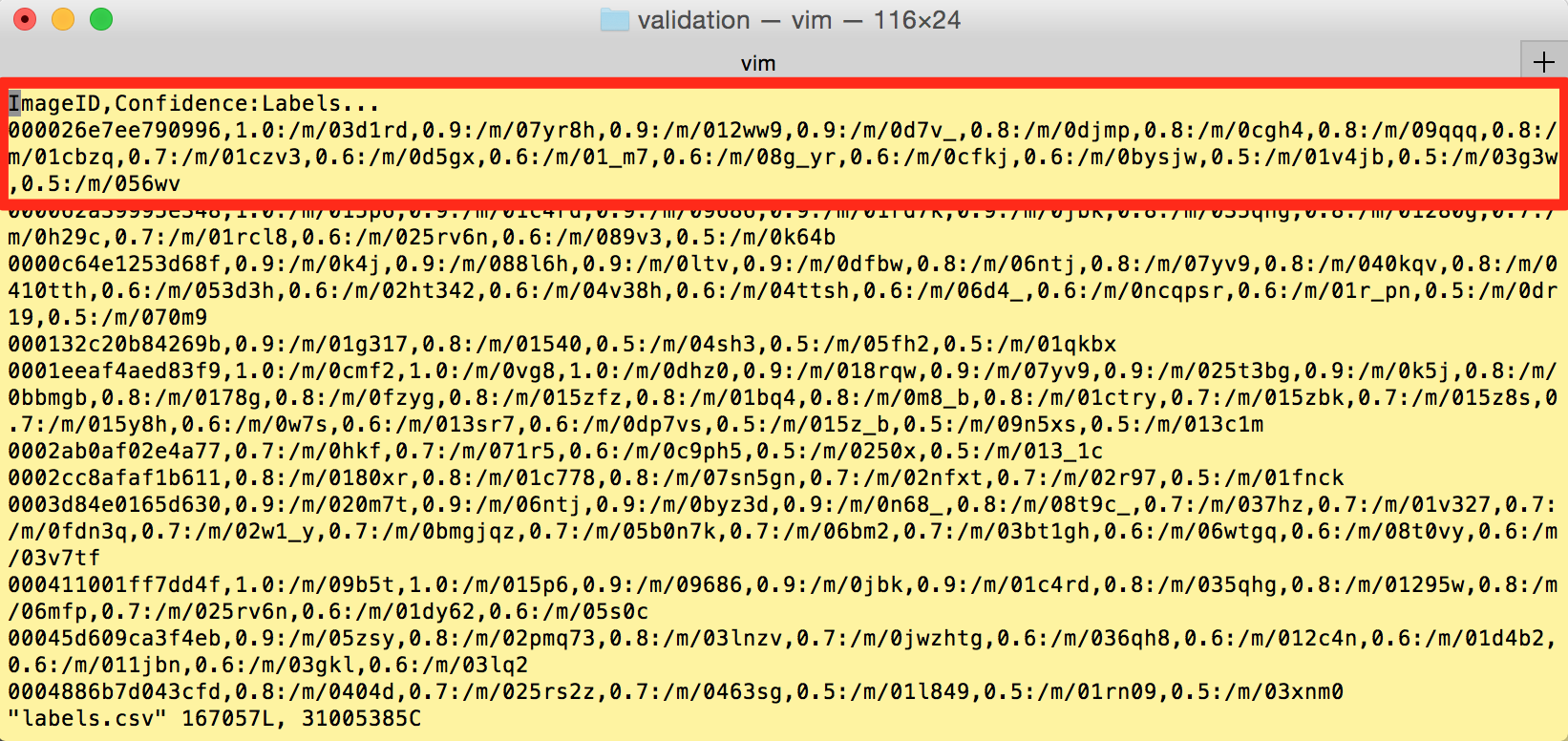
对于人工检验的 confidence 而言,其值只有两个取值:
1
、
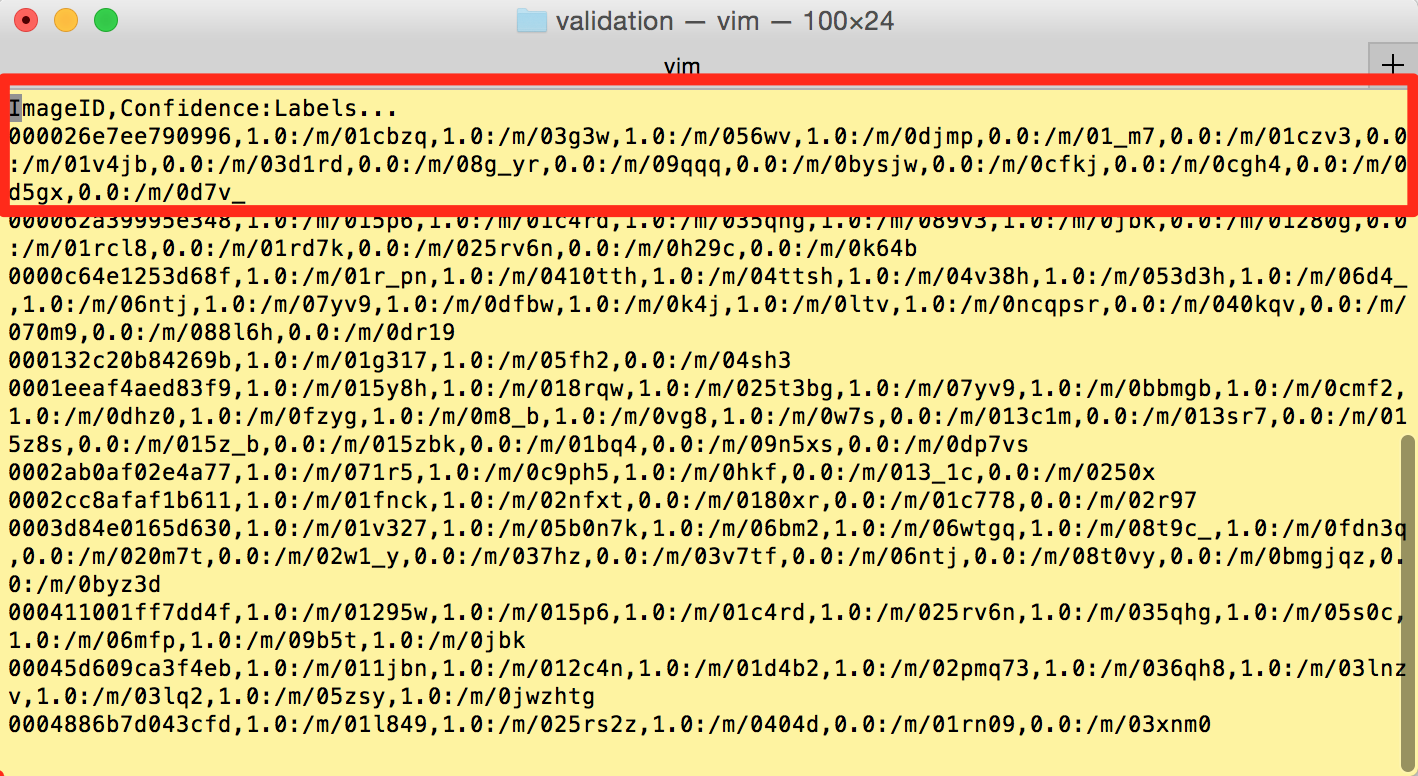
可以看到,人工验证过的中的 ImageID 与 机器标注中的 ImageID 一样,但是 confidence 只有
1
、
Stats and data quality
Open Image 数据中,各类是非常不均衡的。有些 label 对应着百万张图像,有些 label 只有几百、几十张图像:
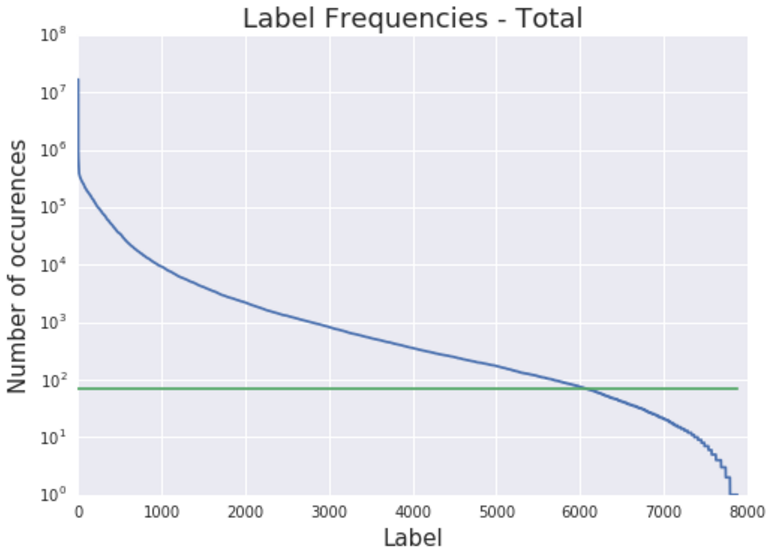
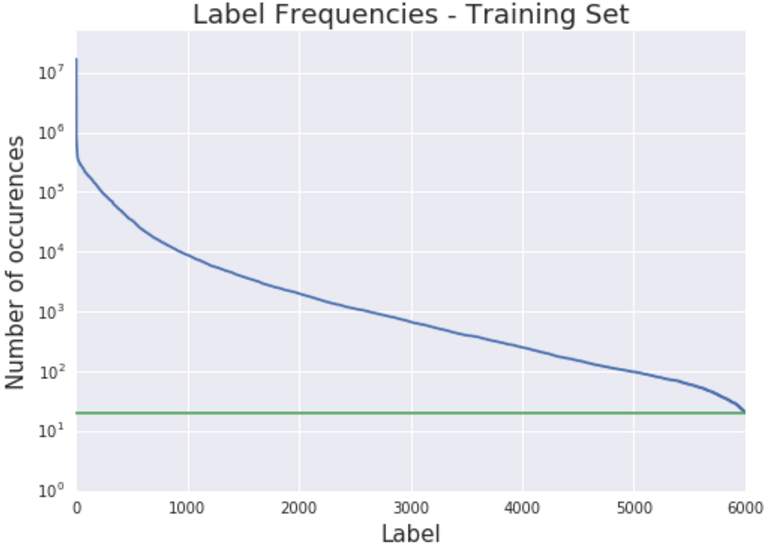
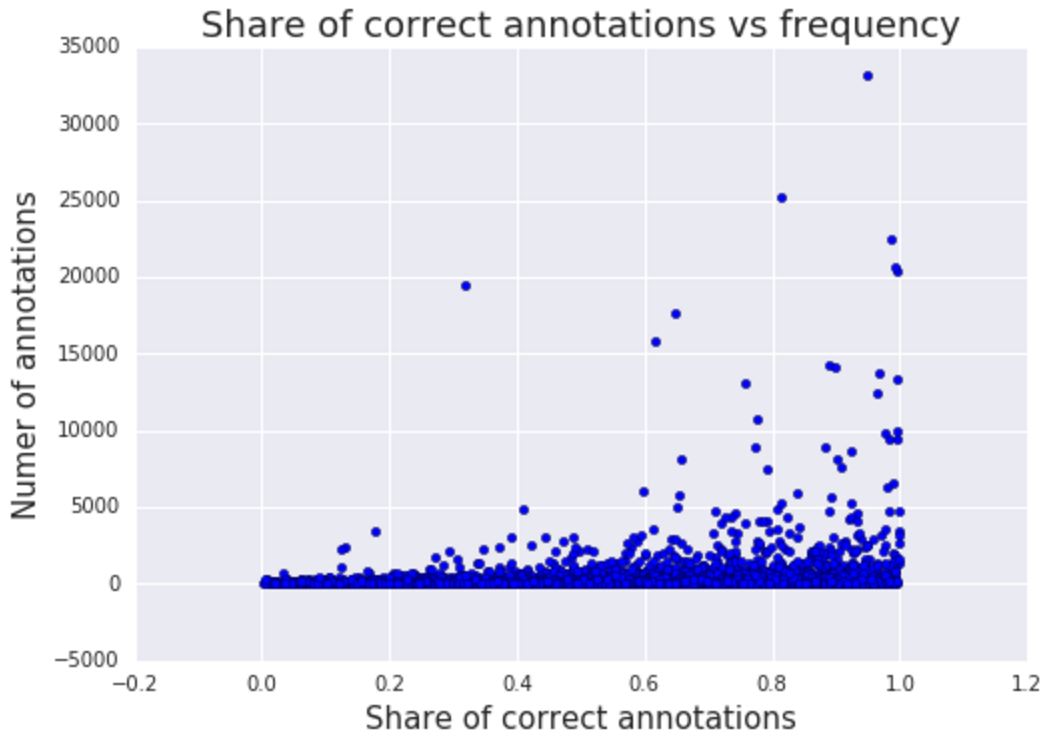
同时,机器标注中,也包含了一些噪声,通常来说,label 对应的图像越多,这个 label 越准确。

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}