







之前学习了将图谱引入推荐的RippleNet模型[1],今天再为大家准备一道大餐:融合了user-item交互信息以及KG信息的推荐模型KGAT。
一
简介
协同过滤CF算法利用用户的行为信息进行偏好预测,该方法在推荐系统里有较好的应用。但是CF算法不能对其他信息(比如商品的属性、用户信息、上文下)进行建模,而且在用户-商品交互信息较少的数据上表现较差。 为了能把其他信息利用起来,学术界常用的做法是:将用户跟商品都用embedded向量进行表示,然后将他们输入监督学习的模型里训练,将用户表示与商品表示的相关性作为训练目标。这里相关工作有:factorization machine (FM) [7], NFM (neural FM) [6], Wide&Deep [5], DCN[4],and xDeepFM [3]等。 扩展一下(加点小菜): FM: 在线性回归的基础上加入二阶线性特征。 ,优点:考虑二阶特征之间的相互作用。缺点:仅仅考虑线性特征,没有加入非线性特征。
NFM: 融合了FM提取二阶线性特征与神经网络提取高阶非线性特征的两者优点。
,优点:考虑二阶特征之间的相互作用。缺点:仅仅考虑线性特征,没有加入非线性特征。
NFM: 融合了FM提取二阶线性特征与神经网络提取高阶非线性特征的两者优点。
 ,其中f(x)是用神经网络对输入特征x进行特征抽取建模。
Wide&Deep: 模型包括两个部分,分别为Wide部分和Deep部分,Wide部分如图1的左图所示,Deep部分如下图中的右图所示。Wide模型就是一个广义线性模型,Wide模型是前馈神经网络。两种模型进行联合训练,将两个模型的结果加权求和作为最终的预测结果。
,其中f(x)是用神经网络对输入特征x进行特征抽取建模。
Wide&Deep: 模型包括两个部分,分别为Wide部分和Deep部分,Wide部分如图1的左图所示,Deep部分如下图中的右图所示。Wide模型就是一个广义线性模型,Wide模型是前馈神经网络。两种模型进行联合训练,将两个模型的结果加权求和作为最终的预测结果。
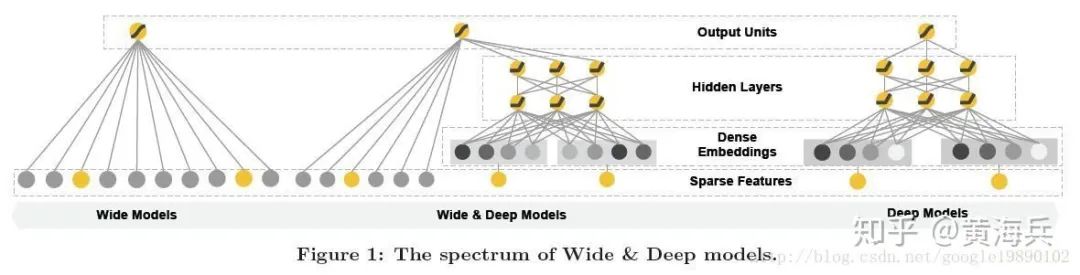 图1:Wide&Deep模型结构图
图1:Wide&Deep模型结构图
DeepFM: 速览 DeepFM: 使用 FM 取代 Wide & Deep 中的 LR (https://zhuanlan.zhihu.com/p/57158486) ,
xDeepFM: 名副其实的 ”Deep” Factorization Machine (https://zhuanlan.zhihu.com/p/57162373) 虽然这些模型都能取得不错的效果,但是这些模型有个缺点:将训练数据里(用户交互数据)的特征进行独立建模,没有考虑到交互数据之间的关系。这使得这些模型不足以从用户的行为中提取出基于属性的协同信息。 比如下图2中,用户
 看了电影
看了电影
 ,这个电影是
,这个电影是
 导演的,传统的CF方法会着重去找那些也看了电影
的用户,比如
导演的,传统的CF方法会着重去找那些也看了电影
的用户,比如
 跟
跟
 。而监督学习方法会重点关注那些有相同属性
。而监督学习方法会重点关注那些有相同属性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









