







推文链接:【GNN】图注意力网络
GAT
GAT (Graph Attention Network) 是一种基于图结构数据的新型神经网络结构,利用隐藏的自我注意层来解决以前基于图卷积或其近似方法的缺点。通过叠加层,节点能够参与其邻域的特征,该方法允许 (隐式地) 为邻域的不同节点指定不同的权重,而不需要任何类型的昂贵的矩阵操作或依赖于预先了解图结构。通过这种方式,GAT 同时解决了基于频谱的图神经网络的几个关键挑战,并使模型易于适用于归纳和转导问题。

从图卷积网络 (GCN) 中,我们了解到,将局部图结构与节点级特征相结合,可以在节点分类任务中获得良好的性能。
h i ( l + 1 ) = σ ( ∑ j ∈ N ( i ) 1 c i j W ( l ) h j ( l ) ) c i j = ∣ N ( i ) ∣ ∣ N ( j ) ∣ \begin{aligned} h_i^{(l+1)}&=\sigma\left(\sum_{j\in \mathcal{N}(i)} {\frac{1}{c_{ij}} W^{(l)}h^{(l)}_j}\right) \\ c_{ij}&=\sqrt{|\mathcal{N}(i)|}\sqrt{|\mathcal{N}(j)|} \end{aligned} hi(l+1)cij=σ⎝⎛j∈N(i)∑cij1W(l)hj(l)⎠⎞=∣N(i)∣∣N(j)∣
然而,GCN 聚合消息的方式是依赖于结构的,这可能会损害其通用性。
GAT 引入注意机制来替代静态归一化卷积运算。下图清楚地说明了关键的区别。
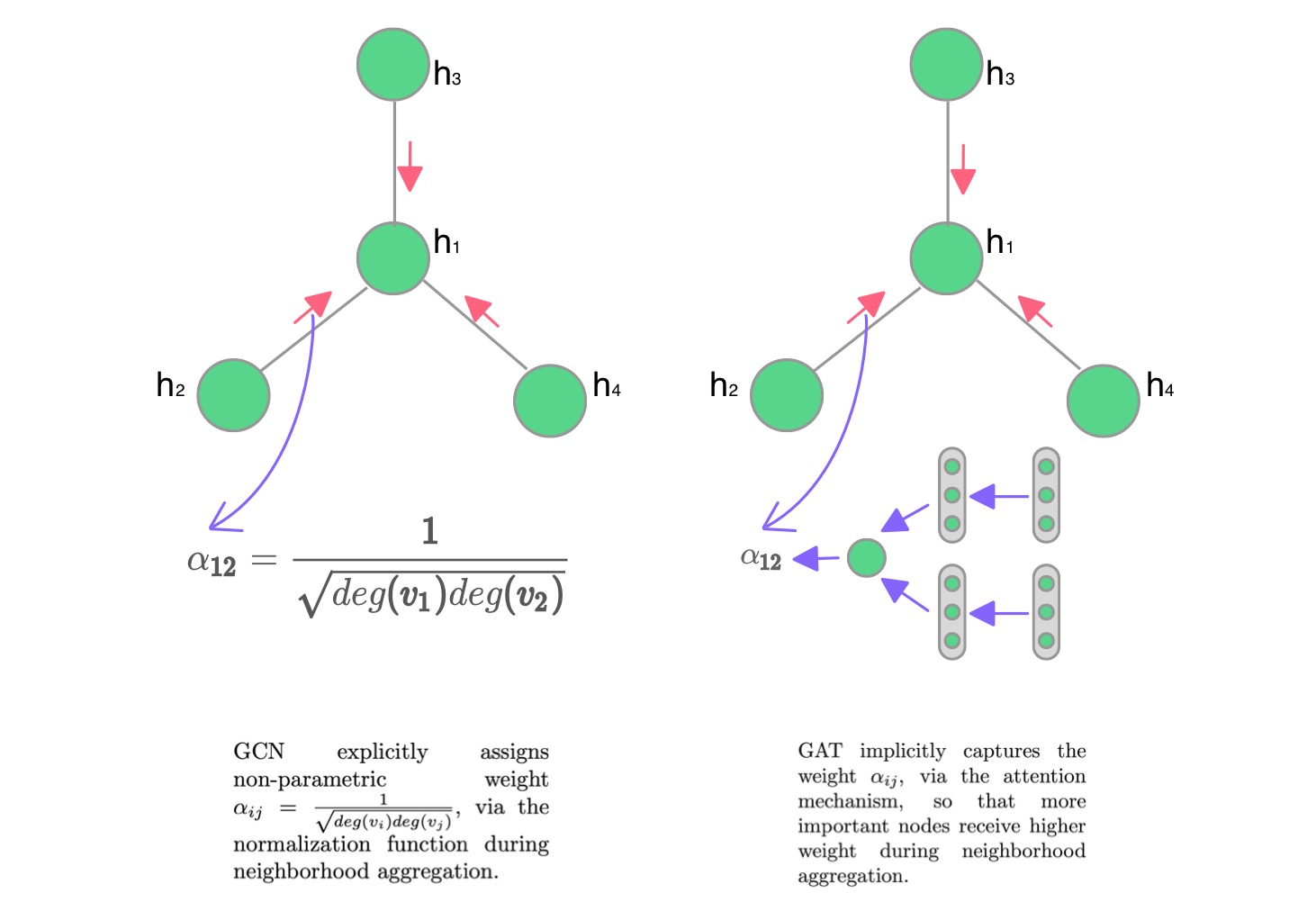
Attention layer
输入是一组节点特征
h = h ⃗ 1 , h ⃗ 2 , … , h ⃗ N , h ⃗ i ∈ R F \mathbf{h} = {\vec{h}_1,\vec{h}_2,…,\vec{h}_N}, \vec{h}_i ∈ \mathbb{R}^{F} h=h1,h2,…,hN,hi∈RF
产生一组新的节点特性
h = h ′ ⃗ 1 , h ′ ⃗ 2 , … , h ′ ⃗ N , h ′ ⃗ i ∈ R F ′ \mathbf{h} = {\vec{h'}_1,\vec{h'}_2,…,\vec{h'}_N}, \vec{h'}_i ∈ \mathbb{R}^{F'} h=h′1,h′2,…,h′N,h′i∈RF′
注意力层可以分为 4 个部分:
- Simple linear transformation

为了获得足够的表达能力将输入特征转换为高级特征,至少需要一个可学习的线性变换。为此,作为初始步骤,由一个权矩阵 W ∈ R F ′ × F W ∈ \mathbb{R}^{F′×F} W∈RF′×F 参数化的共享线性变换应用到每个节点。
z i ( l ) = W ( l ) h i ( l ) \begin{aligned} z_i^{(l)}&=W^{(l)}h_i^{(l)} \end{aligned} zi(l)=W(l)hi(l)
- Attention Coefficients
然后,我们计算两个邻居之间的成对未标准化注意得分。
e i j ( l ) = LeakyReLU ( a ⃗ ( l ) T ( z i ( l ) ∣ ∣ z j ( l ) ) ) \begin{aligned} e_{ij}^{(l)}&=\text{LeakyReLU}(\vec a^{(l)^T}(z_i^{(l)}||z_j^{(l)}))\ \end{aligned} eij(l)=LeakyReLU(a(l)T(zi(l)∣∣zj(l)))
∣ ∣ || ∣∣ 表示连接(concatenation)。这种形式的注意通常被称为加法注意,与变压器模型(Transformer)中使用的点积注意相反。此步骤允许每个节点参与其他节点进行计算,不考虑所有结构信息。
Softmax
这使得系数很容易在不同节点之间进行比较,我们使用 softmax 函数在
j
j
j 的所有选项中标准化它们
α i j ( l ) = exp ( e i j ( l ) ) ∑ k ∈ N ( i ) exp ( e i k ( l ) ) \begin{aligned} \alpha_{ij}^{(l)}&=\frac{\exp(e_{ij}^{(l)})}{\sum_{k\in \mathcal{N}(i)}^{}\exp(e_{ik}^{(l)})} \end{aligned} αij(l)=∑k∈N(i)exp(eik(l))exp(eij(l))
- Aggregation
这个步骤类似于GCN。来自邻居的嵌入被聚合在一起,按注意力分数进行缩放。
h i ( l + 1 ) = σ ( ∑ j ∈ N ( i ) α i j ( l ) z j ( l ) ) \begin{aligned} h_i^{(l+1)}&=\sigma\left(\sum_{j\in \mathcal{N}(i)} {\alpha^{(l)}_{ij} z^{(l)}_j }\right) \end{aligned} hi(l+1)=σ⎝⎛j∈N(i)∑αij(l)zj(l)⎠⎞
Multi-head Attention

一个结点 1 在其邻域上的多头注意力 ( K = 3 ) (K = 3) (K=3) 的图解如上图所示,不同的箭头样式和颜色表示独立的注意力计算。从每个头部聚合的特征被连接或平均得到 h ′ ⃗ 1 \vec{h'}_{1} h′1。
与卷积网络中的多通道类似,GAT 使用多头注意力来丰富模型能力并稳定学习过程。具体来说, K K K 个独立注意机制执行方程 4 的转换,根据使用的不同,它们的输出可以有两种组合方式:
- Concatenation
Concatenation : h i ( l + 1 ) = ∣ ∣ k = 1 K σ ( ∑ j ∈ N ( i ) α i j k W k h j ( l ) ) { \color{green} \text{Concatenation} }: h^{(l+1)}_{i}=||_{k=1}^{K}\sigma\left(\sum_{j\in \mathcal{N}(i)}\alpha_{ij}^{k}W^{k}h^{(l)}_{j}\right) Concatenation:hi(l+1)=∣∣k=1Kσ⎝⎛j∈N(i)∑αijkWkhj(l)⎠⎞
从这个设置中可以看到,最终返回的输出 $h ’ $ 将由每个节点的 $KF ’ $特性 (而不是 F ′ F ' F′) 组成。
- Averaging
Average : h i ( l + 1 ) = σ ( 1 K ∑ k = 1 K ∑ j ∈ N ( i ) α i j k W k h j ( l ) ) { \color{red}\text{Average} }: h_{i}^{(l+1)}=\sigma\left(\frac{1}{K}\sum_{k=1}^{K}\sum_{j\in\mathcal{N}(i)}\alpha_{ij}^{k}W^{k}h^{(l)}_{j}\right) Average:hi(l+1)=σ⎝⎛K1k=1∑Kj∈N(i)∑αijkWkhj(l)⎠⎞
如果我们对网络的最终 (预测) 层进行多头关注,则连接不再敏感,而是采用平均,并应用最终非线性 (通常是softmax或 logistic sigmoid 用于分类问题)。
因此中间层使用了连接,最终层使用平均。
Implementation
下面是 GAT layer 的 pytoch 实现,tensorflow 版本见 Github。
class GATLayer(nn.Module):
"""
Simple PyTorch Implementation of the Graph Attention layer.
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GATLayer, self).__init__()
self.dropout = dropout # drop prob = 0.6
self.in_features = in_features #
self.out_features = out_features #
self.alpha = alpha # LeakyReLU with negative input slope, alpha = 0.2
self.concat = concat # conacat = True for all layers except the output layer.
# Xavier Initialization of Weights
# Alternatively use weights_init to apply weights of choice
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
# LeakyReLU
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, input, adj):
# Linear Transformation
h = torch.mm(input, self.W)
N = h.size()[0]
# Attention Mechanism
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# Masked Attention
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, h)
if self.concat:
return F.elu(h_prime)
else:
return h_prime















 3624
3624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









