





发烧中写笔记,我爱学习...
一、【概念扫盲】
GNN图神经网络
这里的图指的是Graph,而非Image, 图论中的图,表达节点关系(想下拓扑图),而非图像表达像素值,图论中的图是可以有孤立节点的,但是在图神经网络中没见过,所以应该也非特别准确。图神经网络即基于图结构的神经网络(后文慢慢解释)。
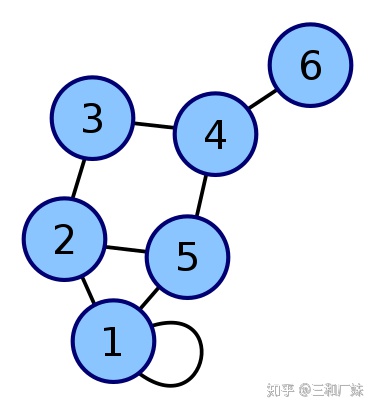
GCN 图卷积网络
我们数学化一点更好理解,图卷积网络(GCN)是一种在图上操作的神经网络。比如给定一个图G=(E,V), 一个GCN的输入如下:
- 一个N×F的输入特征矩阵X,其中N是图中的节点个数,F是每个节点的输入特征个数;
- 一个N×N的图结构表示矩阵,比如G的邻接矩阵A。 因此,GCN中的隐藏层可以写成
- 其中
为初始图状态,
是传播函数。每层
对应于
的特征矩阵。在每一层,这些特征被聚合后再用传播规则
形成下一层的特征。这样,特征在每一个连续的层上都变得越来越抽象。在这个框架中,GCN的变体仅在传播规则
的选择上有所不同。
ps: GNN 和GCN除了都是基于图,其他部分是两个很不同的东西。
二、【基础准备】
我好贴心啊。。
GNN中的不动点理论
对于一个不断循环堆叠的F, 不管初始点
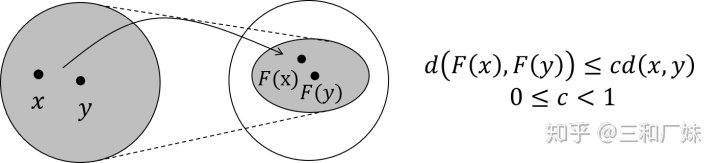
GNN 雅各比矩阵
怎么保证这种映射空间变小呢,只要满足F的雅各比矩阵小于1,那么它就满足不动点理论,回忆一下雅各比矩阵,在向量分析中,雅可比矩阵是函数的一阶偏导数以一定方式排列成的矩阵
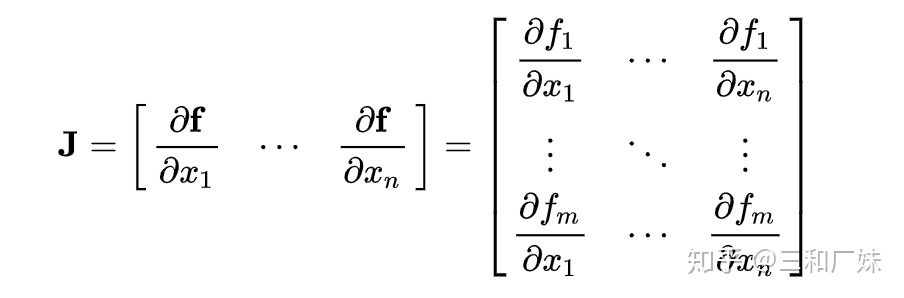
怎么导出来的?
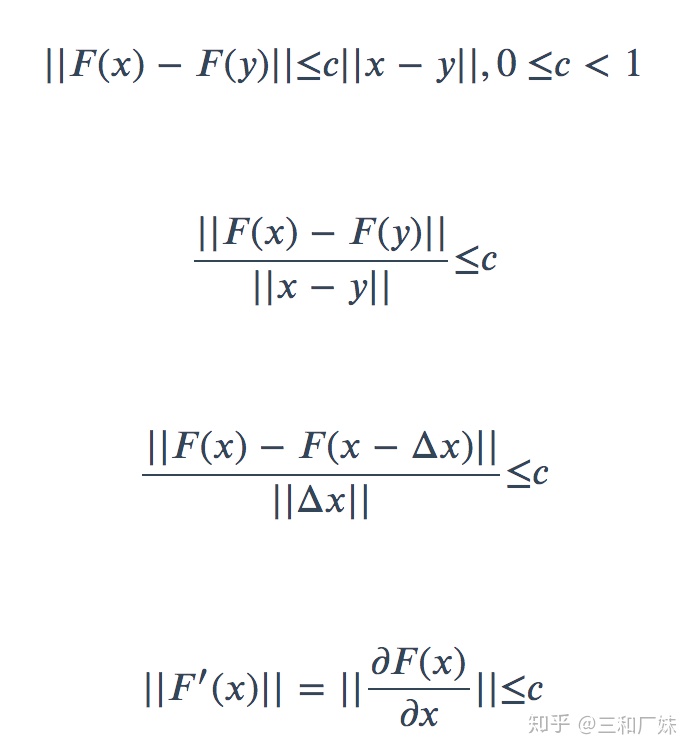
GNN的loss
能看到满足压缩映射其实与雅各比矩阵小于1等价,使用拉格朗日乘子,把条件写入loss中,那么GNN的loss如下
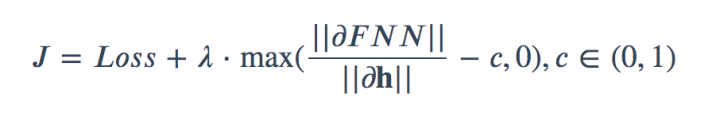
GCN 用到的傅里叶变换
傅里叶变换简单来讲是同一种东西在不同领域的变换与表达,知乎上有一篇特别形象的讲傅里叶变换原理的文章看这里,GCN用到傅里叶变换是为了便于频域卷积求解,后面我们会推导,以几式概之
简单来看就是两个函数的相乘,等于对这分别做了第二个式子变换的两个函数点积相乘然后在做逆变化 ,这种变换是为了方便求解
GCN用到的拉普拉斯算子
首先,假设度矩阵D,邻接矩阵为A,为什么拉普拉斯矩阵是D-A=L,D-A 是能同时表达出图的度信息和邻接信息
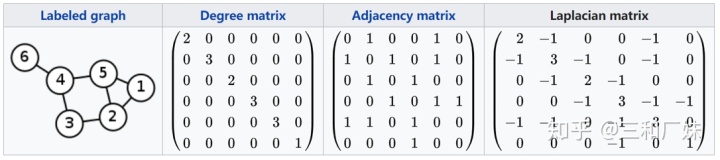
比如对于上图节点,如果作用在每个节点上的函数是f的话 ,以1节点为例
它其实表达的是 离散点的差分,拉普拉斯算子在连续函数上是二阶导,而在离散函数上,导数是用差分来表示,连续函数的拉普拉斯等式
离散的拉普拉斯等式
基础就到这里啦,还不清楚的话回去学习。
三、模型原理
GNN
我们已经知道了GNN基于不动点原理一定会收敛,他的每个节点带着隐藏信息和参数,那么这些最优参数的求解过程就很类似与EM算法,
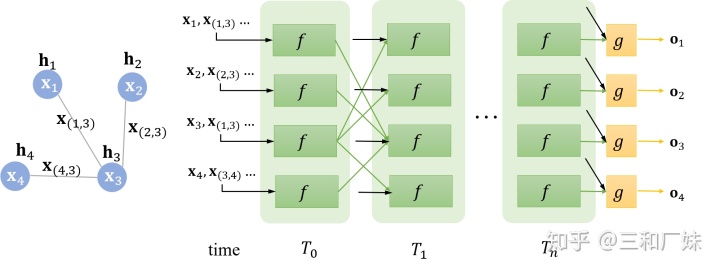
如上图一个GNN,它这里所谓的time时间步就是迭代的次数,并且信息只用输入一次,结构也都是一样,并不会在不同的时间步有什么变换,调整的都是同样的参数,真的就是普通迭代求解一点也不神经网络,也就只有根据loss误差回传能让人觉得跟神经网络有点相关了。
GNN的局限
- 整个就和EM算法类似,只不过提前构造了特征和属性
- 因为基于不动点的收敛会导致结点之间的隐藏状态间存在较多信息共享(整个是连通的,每一个点都能或多或多共享到其他点的信息),从而导致结点的状态太过光滑,并且属于结点自身的特征信息匮乏
- 客服这些问题GNN也有一些变种,比如GGNN,
即将f 变为了GRU,同时多了个边的权值
GCN原理
接基础部分,拉普拉斯矩阵是对称矩阵分解为特征矩阵和特征向量
特征向量为
特征值为
拉普拉斯等式
仿照傅里叶变换将
那图领域的离散拉普拉斯变换,
根据卷积的傅里叶公式
将
我们调整卷积,就只需要调整
【一些应用】
SRL语义角色标注
语义角色标注是以句子的谓词为中心,分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。传统的语义角色标注建立在句法分析之上,通常是先建立一棵句法树,从句法树上识别出谓词与论元,然后通过候选论元的减枝,选出真正的论元,最后对选出的论元进行分类,来得到语义角色标签,如:“小明昨天在公园遇见了小红”,经过标注后,“遇到”是谓词,“小明”是实施者,“小红”是受事者。
在[1]中,作者提出来一种基于GCN的语义角色标注方法,具体就是在lstm的后面一层接一层GCN,因为作者任务,lstm前面节点的信息必须一个一个流动到后面节点,会有较多信息损失,捕获不到长句(论元中间隔着的词较多,距离比较远)的关系,而这又恰恰是SRL的难点,加一层GCN时,两个相距较远的词能直接通过图的关系连接。然后作者的GCN是加在[2]的lstm+crf之上,这篇是在在输入上做了点动作,将普通的输入扩展了一下,具体是标注除了谓词还有谓词区,并且标注包含了BIO,在我理解这种扩展谓词做法就是手工特征,标注顺便标了BIO就是感觉是在做了多任务。
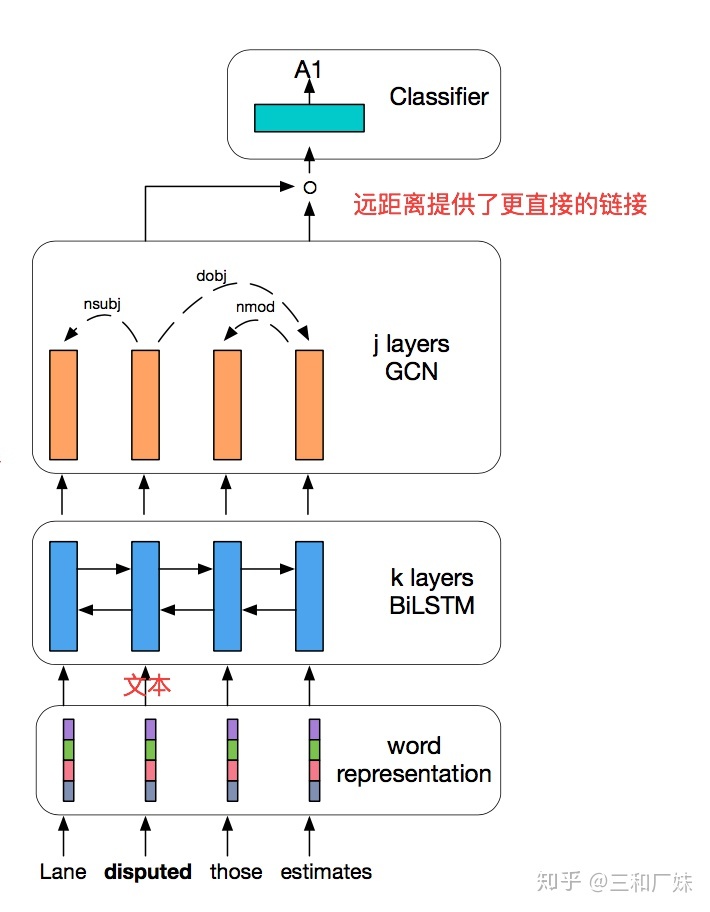
GGNN语义解析
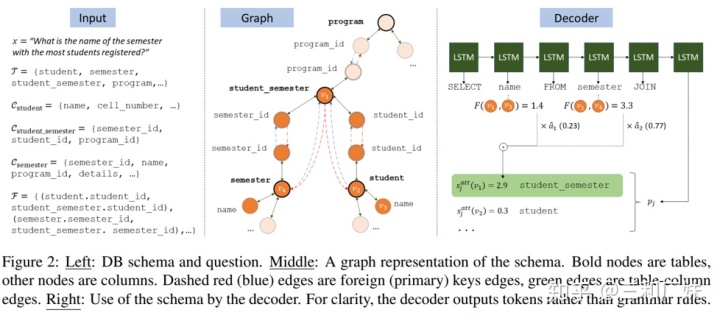
[3]在普通的seq2seq上加GGNN来做自然语言到SQL语言的翻译处理,motivation我觉得首先数据库的结构和约束用图来表示就是比较方便的,其次原理跟上面一样,图能穿越单词建立直接的联系,而非让单词的信息一个个流动。
具体这篇论文来说:
数据是:
图的结构:通过表格建立对应的Graph。一个表和其中的列组成了一颗树,然后不同树里相同的列(外键)连接起来构成图
具体做法:
在encoder端
就是普通的lstm encoder加一个手动算出的关系矩阵
在decoder端
- 手动计算出一个
矩阵(就是一些简单特征提取),表示了每个word和schema的简单关系。
- 对于那些word和schema 独立的地方,在最后一层直接 attention和前层的output 全连接计算
- 对于word和schema不独立的地方,用attention*slink得到一个权重
- 对独立和不独立部分分配不同权重

可以看到这类任务还是比较艰难的
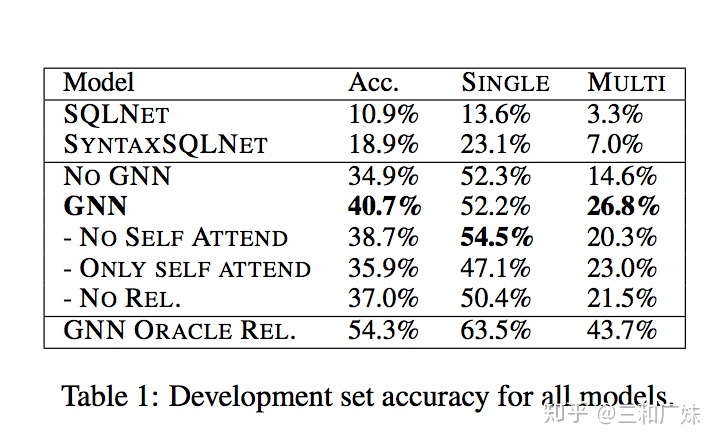
其他应用待更新...
参考
- ^End-to-end learning of semantic role labeling using recurrent neural net- works
- ^Encoding Sentences with Graph Convolutional Networks for Semantic Role Labelin
- ^Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









