





Tips◎作者系 极市原 创作者计划 特约作者Happy 欢迎大家联系极市小编(微信ID:fengcall19)加入极市原创作者行列加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

paper:https://arxiv.org/abs/2004.06965
UDVD一文是
联发科的研究员写的一篇适用于可变降质类型的通用图像超分。UDVD可以视为SRMD中的训练数据生成方案与动态滤波器卷积在图像超分领域的组合应用。目前该文尚未开放源代码与预训练模型,故而实际性能如何尚未可知。但从论文的效果来看,该文是一篇高质量的工作。本人对动态滤波器比较感兴趣,在这方面有一些心得,也曾在对该部分内容撰文并提供实现code,故而花了点时间进行了简单的分析与编码尝试。
Abstract
对图像超分方法有一定了解的小伙伴想必会发现:大多超分方法往往采用固定模式(双线性下采样,而且采用的是matlab中的实现,因为它具有抗锯齿功能,而opencv中的resize则不具有哦)训练数据生成,这也导致了所训练的模型适用范围极为有限,在真实世界数据的应用效果差强人意。真实世界的降质模型要比双线性下采样降质复杂的多,故而具有更通用性的图像超分的研究更为有价值。
作者参考SRMD中的训练数据生成方式、动态滤波器卷积的权值自适应特征提出一种通用的图像超分方案。SRMD的训练数据生成使其可以学习更广义而复杂的降质模型,而动态滤波器卷积则可以根据内容自适应学习最佳的卷积权值,两者的组合将图像超分的性能又一次向前踏了一步。
Method
这里主要从数据制作、网络架构、动态滤波器卷积以及损失函数四个维度进行简单分析与介绍。
Datasets
首先,对降质模型进行了简单分析与介绍。超分的降质模型可以描述为:
其中,分别表示低分辨率与高分辨率图像,分别表示降质模糊核与加性噪声,分别表示卷积与下采样操作。
在训练数据生成过程中,作者参考SRMD仅考虑各项同性高斯模糊核,这也是一类广泛应用的模糊核;在加性噪声方面,选用加性高斯白噪声;在下采样方面,选用双三次下采样。通过控制降质模型中的各个因素的参数可以得到用于训练的LR-HR数据对。
Framework
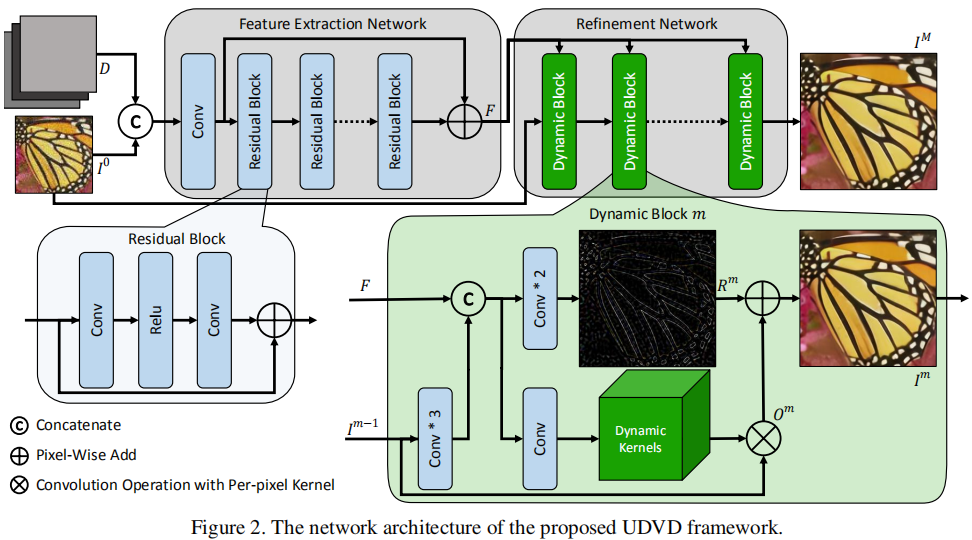 上图给出了作者所涉及的UDVD网络结构示意图。很明显,该方案由三部分构成:(1) 输入部分,它由待超分图像以及降质模型信息构成,这块与SRMD基本相同;(2) 特征提取部分,这块与EDSR网络基本相同;(3) 提纯复原部分,这部分是该文所独有的,它主要由动态滤波器卷积构成,它有两个目的:上采样复原+细节增强。
上图给出了作者所涉及的UDVD网络结构示意图。很明显,该方案由三部分构成:(1) 输入部分,它由待超分图像以及降质模型信息构成,这块与SRMD基本相同;(2) 特征提取部分,这块与EDSR网络基本相同;(3) 提纯复原部分,这部分是该文所独有的,它主要由动态滤波器卷积构成,它有两个目的:上采样复原+细节增强。
- 输入部分:为更好的处理不同降质类型问题,作者参考SRMD中的输入部分。该不仅包含待处理图像,与此同时还包含关于降质模型的先验信息,这部分先验信息包含:(1) 降质模糊核的主成分信息;(2) 噪声强度。为尽可能的降低输入的通道数,SRMD的作者将降质模糊核先验采用PCA进行降维,降维至15维,即。所以这里的输入合计为。
- 特征提取部分。在图像超分网络中,特征提取模块必不可少,它也是区别不同方法的关键区别所在,目前大多数超分也主要聚焦于这块。UDVD在这部分直接选用了EDSR的特征提取模块,即堆叠残差模块+全局跳过连接。
- 提纯复原部分。该部分是全文的关键创新点所在,它以动态滤波器卷积为出发点进行设计。详细性的介绍见后续小节部分,这里仅介绍一下该部分的作用。该部分包含三个动态滤波器卷积模块,每个模块以待处理图像、前一步提取的特征作为输入。首先,对待处理图通过三个卷积进一步提取特征;然后,将其与特征提取部分的特征
Concat;其次,将前述特征分别进行残差图测试与动态滤波器卷积核预测;最后将签署预测动态滤波器卷积核与待处理图像进行逐点卷积计算并预测残差图相加得到输出。
Dynamic Convolution
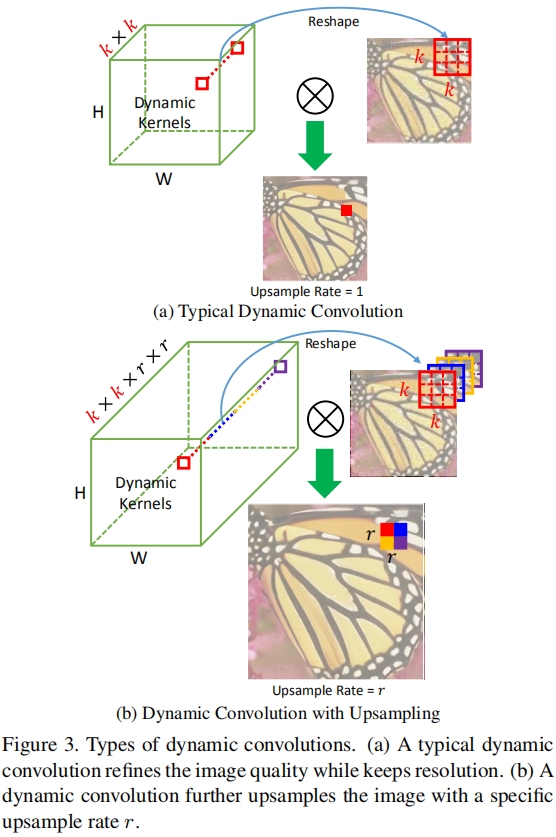
上图给出了两种类型的动态滤波器卷积,前者不涉及分辨率上采样,我们暂且称之为常规动态滤波器卷积,后者涉及分辨率上采样,我们暂且称之为上采样动态滤波器卷积。
对于常规动态滤波器卷积,其计算公式定义如下:
其中,表示位置处的卷积核。这也是它与常规卷积的不同之处,常规卷积的卷积核全局共享,而动态滤波器卷积中的卷积核则是逐点不同。与此同时,卷积核又可以根据计算方式的不同而有不同的配置方式(比如标准卷积模式、DepthwiseConv模式,作者默认选用DepthwiseConv)。
对于上采样动态滤波器卷积,其计算公式定义如下:
Loss
在损失函数方面,类似LapSRN与ProSR,作者采用采用的多阶段损失,即每个动态卷积模块的输出均需要计算损失。损失函数定义如下:
其中,损失函数可以选择或者感知损失、SSIM等。作者在这里选用了损失。
NOTE:从上述公式,我们其实可以确认:提纯复原部分的三个动态滤波器卷积模块的第一个为上采样动态滤波器卷积,后两个为常规动态滤波器卷积。
Experiments
Datasets
前面也提到了作者希望所提方案能够处理可变降质问题,所以数据的制作就需要具有多样性,传统的双三次下采样是肯定不行的咯。那么具体是如何处理的呢?注:深入研究过SRMD一文的小伙伴可以略过该部分。
类似SRMD,作者在训练数据对制作时考虑各向同性高斯核,核范围设为,高斯核的尺寸固定为,采用均匀采样方式生成所有的降质核。加性高斯白噪声的额噪声水平范围选择为。关于SRMD的相关数据制作代码可以参考链接https://github.com/cszn/KAIR/blob/master/utils/utils_sisr.py。
Note:一点点提示,各位小伙伴在训练SRMD或者UDVD请务必先制作数据并保存为lmdb或者其他格式,直接采用KAIR中的SRMD在线数据制作方式真的真的非常非常慢!(请一定一定要采用离线数据制作哦)
# NOTE: code from https://github.com/cszn/KAIR/blob/master/utils/utils_sisr.pyimport scipy.stats as ssimport numpy as npdef anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6): v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.])) V = np.array([[v[0], v[1]], [v[1], -v[0]]]) D = np.array([[l1, 0], [0, l2]]) Sigma = np.dot(np.dot(V, D), np.linalg.inv(V)) k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize) return kdef gm_blur_kernel(mean, cov, size=15): center = size / 2.0 + 0.5 k = np.zeros([size, size]) for y in range(size): for x in range(size): cy = y - center + 1 cx = x - center + 1 k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov) k = k / np.sum(k) return kdef get_pca_matrix(x, dim_pca=15): C = np.dot(x, x.T) w, v = scipy.linalg.eigh(C) pca_matrix = v[:, -dim_pca:].T return pca_matrixdef cal_pca_matrix(path='PCA_matrix.mat', ksize=15, l_max=12.0, dim_pca=15, num_samples=500): kernels = np.zeros([ksize*ksize, num_samples], dtype=np.float32) for i in range(num_samples): theta = np.pi*np.random.rand(1) l1 = 0.1+l_max*np.random.rand(1) l2 = 0.1+(l1-0.1)*np.random.rand(1) k = anisotropic_Gaussian(ksize=ksize, theta=theta[0], l1=l1[0], l2=l2[0]) kernels[:, i] = np.reshape(k, (-1), order="F") pca_matrix = get_pca_matrix(kernels, dim_pca=dim_pca) io.savemat(path, {'p': pca_matrix}) return pca_matrix在训练过程中,训练数据的HR源自DIV2K与Flickr2K,固定LR的输入大小为,那么不同尺度超分对应的HR的输出大小分别为。与此同时,还进行了随机水平镜像、随机垂直镜像、90旋转等数据增广。
UDVD Configurations
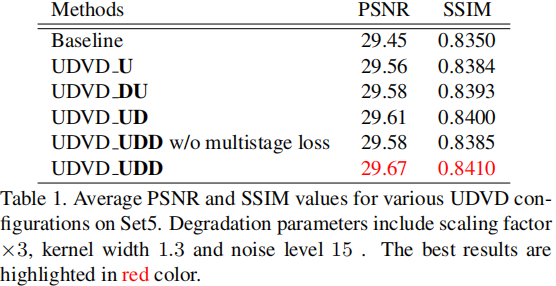 上表总结了不同UDVD配置下的性能对比。其中baseline基本等同于EDSR。**表示常规动态滤波器卷积,**表示上采样动态滤波器卷积。从中可以看出:(1)动态滤波器卷积取得了优于EDSR类方法的性能;(2) UDD组合则具有最佳性能,说明Refinement模块还是有一些必要性的;(3)多阶段损失监督有助于提升模型性能。
上表总结了不同UDVD配置下的性能对比。其中baseline基本等同于EDSR。**表示常规动态滤波器卷积,**表示上采样动态滤波器卷积。从中可以看出:(1)动态滤波器卷积取得了优于EDSR类方法的性能;(2) UDD组合则具有最佳性能,说明Refinement模块还是有一些必要性的;(3)多阶段损失监督有助于提升模型性能。
Visualizing Dynamic Kernel

上图给出了真实卷积核与预测卷积核的可视化效果图。从中可以看出:动态滤波器可以自适应学习最佳卷积核,有能力解决空间可变降质问题。
Comparison
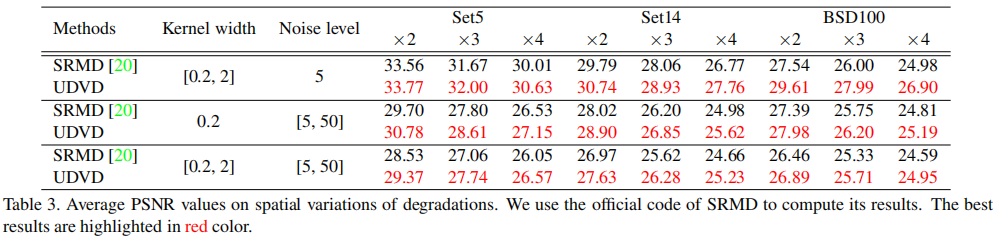
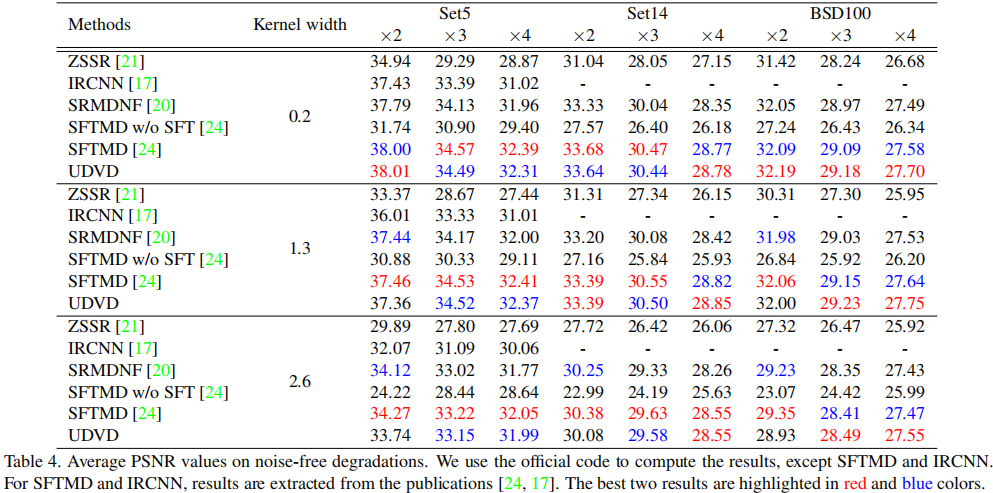
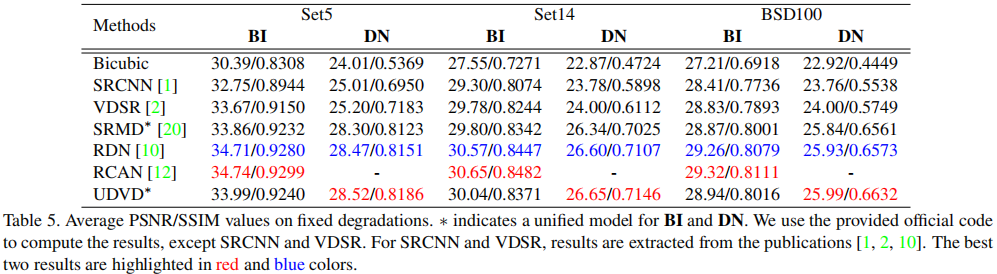
为更好的说明所提方法的优异性能,作者设计了几组实验:(1) 多种可变降质下的性能对比,UDVD具有最佳的PSNR指标;(2) 空间可变降质下的性能对比,UDVD取得了优于SRMD的性能;(3) 无噪可变降质下的性能对比,UDVD取得了仅次于SFTMD的性能,如能嵌入SFT,UDVD也许可以取得由于STFMD的性能;(4) 固定降质下的性能对比,在这种情况下,对于BI降质,UDVD仍具有媲美RCAN的性能,在DN下具有最佳性能。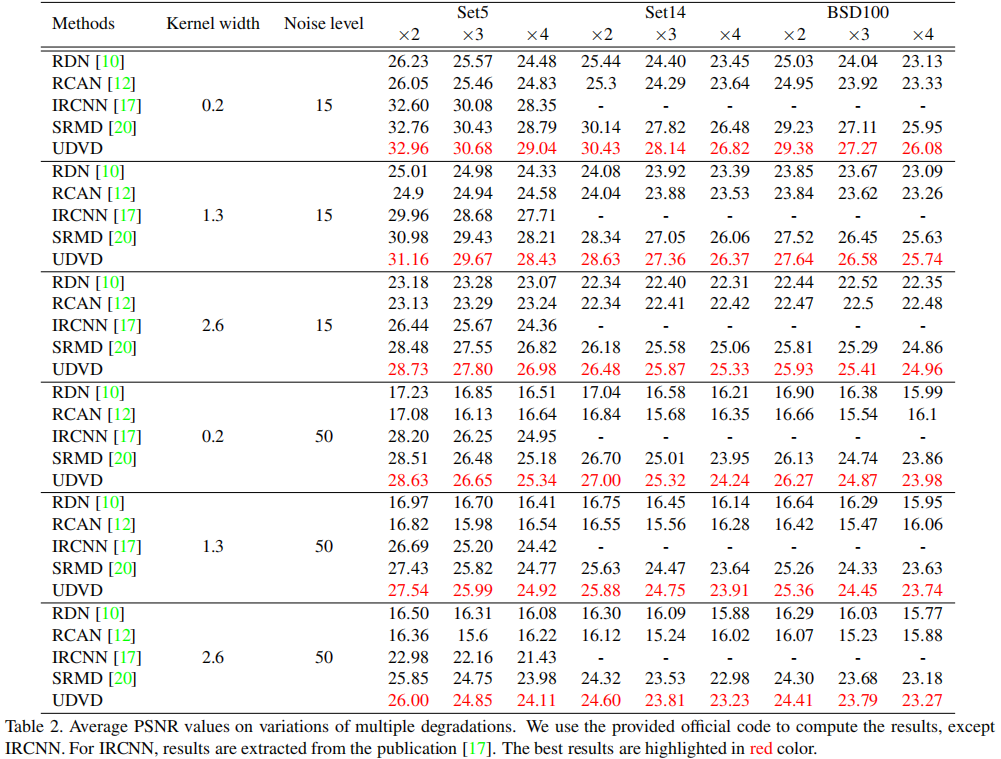

Real Images
除了在前述合成图像上对比外,作者还在真实世界图像上进行了对比,见下图。从中可以看出:UDVD不仅可以很好的移除噪声,同时可以很好的恢复出锐利的细节。

Conclusion
总而言之,作者提出一种Unified Dynamic Convolutional Network for Variational Degradatios, UDVD用于可变降质图像超分。它以SRMD为起点,结合动态滤波器卷积、多阶段损失而得到。在合成数据与真实世界数据上均验证了所提方法的优异性能。
Reference Code
前面介绍了UDVD的原理性介绍,最后补上重磅干货:参考代码(注网络的相关参数已经写成固定模式)。
import numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Fclass UDVD(nn.Module): def __init__(self): super().__init__() self.head = nn.Conv2d(19, 128, 3, 1, 1) body = [ResBlock(128, 3, 0.1) for _ in range(15)] self.body = nn.Sequential(*body) self.UpDyConv = UpDynamicConv() self.ComDyConv1 = CommonDynamicConv() self.ComDyConv2 = CommonDynamicConv() def forward(self, image, kernel, noise): assert image.size(1) == 3, 'Channels of Image should be 3, not {}'.format(image.size(1)) assert kernel.size(1) == 15, 'Channels of kernel should be 15, not {}'.format(kernel.size(1)) assert noise.size(1) == 1, 'Channels of noise should be 1, not {}'.format(noise.size(1)) inputs = torch.cat([image, kernel, noise], 1) head = self.head(inputs) body = self.body(head) + head output1 = self.UpDyConv(image, body) output2 = self.ComDyConv1(output1, body) output3 = self.ComDyConv2(output2, body) return output1, output2, output3class ResBlock(nn.Module): def __init__(self, channels, kernel_size=3, res_scale=1.0): super().__init__() padding = (kernel_size - 1) // 2 self.conv = nn.Sequential( nn.Conv2d(channels, channels, kernel_size, 1, padding), nn.ReLU(inplace=True), nn.Conv2d(channels, channels, kernel_size, 1, padding) ) self.res_scale = res_scale def forward(self, inputs): return inputs + self.conv(inputs) * self.res_scaleclass PixelConv(nn.Module): def __init__(self, scale=2, depthwise=False): super().__init__() self.scale = scale self.depthwise = depthwise def forward(self, feature, kernel): NF, CF, HF, WF = feature.size() NK, ksize, HK, WK = kernel.size() assert NF == NK and HF == HK and WF == WK if self.depthwise: ink = CF outk = 1 ksize = int(np.sqrt(int(ksize // (self.scale ** 2)))) pad = (ksize - 1) // 2 else: ink = 1 outk = CF ksize = int(np.sqrt(int(ksize // CF // (self.scale ** 2)))) pad = (ksize - 1) // 2 # features unfold and reshape, same as PixelConv feat = F.pad(feature, [pad, pad, pad, pad]) feat = feat.unfold(2, ksize, 1).unfold(3, ksize, 1) feat = feat.permute(0, 2, 3, 1, 5, 4).contiguous() feat = feat.reshape(NF, HF, WF, ink, -1) # kernel kernel = kernel.permute(0, 2, 3, 1).reshape(NK, HK, WK, ksize * ksize, self.scale ** 2 * outk) output = torch.matmul(feat, kernel) output = output.permute(0, 3, 4, 1, 2).view(NK, -1, HF, WF) if self.scale > 1: output = F.pixel_shuffle(output, self.scale) return outputclass CommonDynamicConv(nn.Module): def __init__(self): super().__init__() self.image_conv = nn.Sequential( nn.Conv2d(3, 16, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(16, 16, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(16, 32, 3, 1, 1) ) # I'm not sure how to deal the feautre. # Because it need to upsample the feature and align, # but the paper not provide useful information about it, just provide # Sub-pixel Convolution layer is used to align the resolutions between paths. self.feat_conv = nn.Sequential( nn.PixelShuffle(2), nn.Conv2d(32, 128, 1) ) self.feat_residual = nn.Sequential( nn.Conv2d(160, 16, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(16, 3, 3, 1, 1) ) self.feat_kernel = nn.Conv2d(160, 25, 3, 1, 1) self.pixel_conv = PixelConv(scale=1, depthwise=True) def forward(self, image, features): image_conv = self.image_conv(image) features = self.feat_conv(features) cat_inputs = torch.cat([image_conv, features], 1) kernel = self.feat_kernel(cat_inputs) output = self.pixel_conv(image, kernel) residual = self.feat_residual(cat_inputs) return output + residualclass UpDynamicConv(nn.Module): def __init__(self): super().__init__() self.image_conv = nn.Sequential( nn.Conv2d(3, 16, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(16, 16, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(16, 32, 3, 1, 1) ) self.feat_residual = nn.Sequential( nn.Conv2d(160, 64, 3, 1, 1), nn.ReLU(inplace=True), nn.PixelShuffle(upscale_factor=2), nn.Conv2d(16, 3, 3, 1, 1) ) self.feat_kernel = nn.Conv2d(160, 25 * 4, 3, 1, 1) self.pixel_conv = PixelConv(scale=2, depthwise=True) def forward(self, image, features): image_conv = self.image_conv(image) cat_inputs = torch.cat([image_conv, features], 1) kernel = self.feat_kernel(cat_inputs) output = self.pixel_conv(image, kernel) residual = self.feat_residual(cat_inputs) return output + residualdef demo(): net = UDVD() inputs = torch.randn(1, 3, 64, 64) kernel = torch.randn(1, 15, 64, 64) noise = torch.randn(1, 1, 64, 64) with torch.no_grad(): output1, output2, output3 = net(inputs, kernel, noise) print(output1.size()) print(output2.size()) print(output3.size())if __name__ == '__main__': demo()推荐阅读:
SRGAN With WGAN,让超分辨率算法训练更稳定
除了超分辨率,AI 结合 RTC 还有哪些技术实践?
基于深度学习的超分辨率图像技术一览

△长按关注极市平台,获取最新CV干货

觉得有用麻烦给个在看啦~ 















 1368
1368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









