






点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

图像/视频超分领域近期并无突破性的方法出现,故近期计划将图像/视频超分相关方法进行一次综述性汇总。计划从不同点出发对图像/视频超分进行一次“反思”之旅。本文是该旅程的第一站:图像降质过程。
尽管图像超分和视频超分在方法上或多或少会有一些关键性的区别,但是两者在训练数据对的制作方面其实并无非常大的区别。所以本文主要以图像超分为例进行介绍。
说到图像超分,大家可能会很自然的想到这样几个数据集:DIV2K,Set5,Set14等等。确实,这些数据集都是图像超分领域最常见的数据集。我们先来简单汇总一下图像/视频超分领域有哪些公开数据集。
| Name | Phase |
|---|---|
| Set5 | test |
| Set14 | test |
| B100 | test |
| Menga109 | test |
| Urban100 | test |
| General100 | test |
| L20 | test |
| DIV2K | train/val |
| DIV8K | train/val |
| Flickr2K | train |
| DF2K(DIV2K+Flickr2K) | train |
| City100 | train/val |
| DRealSR | train/val |
| RealSR(V1, V2, V3) | train/val |
| Aogra(声网) | train |
| Vid4 | test |
| SPMCs | test |
| UDM10 | test |
| MM522 | train |
| REDS | train/val |
| Vimeo | train/val |
| Youku | train |
注:上面所列出的仅是图像/视频超分的常用数据集以及部分竞赛数据集,除此之外还有一些Real-World数据集。其中DIV2K当属图像超分领域应用最多的一个数据集,它也是目前图像超分最常用的一个训练数据集(部分模型会考虑采用DF2K进一步提升模型性能,比如AIM2020-Efficient SuperResolution中的方法都采用了DF2K进行模型训练);REDS与Vimeo是视频超分领域应用最多的两个训练数据集(REDS是NTIRE2019竞赛中引入的一个数据集);RealSR、DRealSR是两个真实场景采集的图像超分数据集(具体怎样构建的训练数据对后期有空会介绍一下)。
尽管有了上述数据集,那么训练数据对LR-HR是如何构建的呢?
原理
对于图像超分而言,LR图像的获取过程一般可以描述为:
其中,k表示降质模糊核(它有多种选择,比如双三次核、高斯核等), 表示下采样,n表示加性高斯白噪声。
可以看到上述降质过程包含模糊、下采样以及噪声,而图像超分则仅仅考虑了模糊核下采样。我们就来对可能的降质过程做一个简单的归纳,见下表。
| 类型 | 说明 |
|---|---|
| BI | bicubic-down |
| BD | blur-down |
| BN | bicubic-down+noise |
| DN | blur-down+noise |
注:BI表示降质过程仅包含双三次下采样;BD表示通过高斯模糊下采样;BN表示双三次插值下采样+高斯白噪声;DN表示高斯模糊下采样+高斯白噪声。
在这四种降质类型中,BI与BD是最常见的两种降质类型,而针对BN和DN的研究相对较少。而针对BI与BD两种降质的研究则属BI更多。
BI实现
接下来,我们将简单的介绍一下上述四种降质类型是如何实现的。首先,我们来看一下BI。做CV的同学对Bicubic应该非常熟悉,可以轻松的采用OpenCV或者PIL等库图像的双三次插值。但是,这里大家需要特别注意:BI一般特指matlab中的imresize。OpenCV与MATLAB在imresize的实现上是有区别的:matlab中的imresize具有抗锯齿功能,而OpenCV中的resize则不具备上述功能。关于matlab如何制作数据,可以参考BasicSR。这里附上关键性代码。
sclae = 4
image_path = "butterfly.png"
image = imread(image_path)
image = im2double(image)
image = modcrop(image, scale)
imgLR = imresize(image, 1/scale, 'bicubic')
function image = modcrop(image, scale)
if size(img, 3) == 1
sz = size(img);
sz = sz - mod(sz, scale)
image = image(1:sz(1), 1:sz(2))
else
tmpsz = size(img);
sz = tmpsz(1:2)
sz = sz - mod(sz, scale)
image = image(1:sz(1), 1:sz(2))
end
end
也许有同学会说,都2020年了,谁还会用MATLAB啊,有没有Python版的呢?这里提供两个基于Pytorch与matlab相当的imresize。
matlab_functiosn_verification
bicubic_pytorch
但是,需要注意:尽管上述两个版本的imresize实现是参考MATLAB中的imresize进行的实现,但因为一些数据精度问题,最终的实现还是会有一点点的区别。区别有多大呢,见下表。
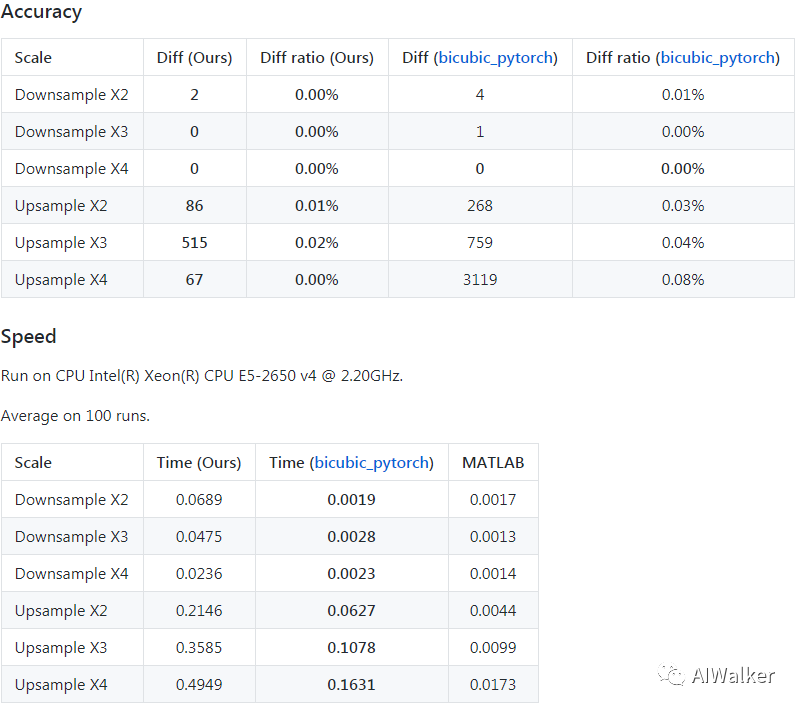
注:表中数据来自XinTao大佬的测试,笔者也对Diff进行了测试,指标一致;不过与测试机器的性能区别,算法的耗时存在部分出入。
从上述表中结果来看,如果要进行X4超分,强烈建议各位同学采用bicubic_pytorch中的实现,因为它还可以通过GPU进行加速(就是这么优秀);当然XinTao大佬提供的Pytorch实现更为精确(笔者就是资深受益者,哈哈)。
BD实现
上面介绍了BI的实现方法(matlab和python),这里我们将介绍BD的实现方法。
在图像超分领域,BD中的高斯模糊参数为:kernelsize=7,sigma=1.6。相关实现可以参考如下链接中的代码:Prepare_TrainData_HR_LR_BD.m。这里列出核心代码:
kernelsize = 7;
sigma = 1.6;
kernel = fspecial('gaussian', kernelsize, sigma)
sclae = 4
image_path = "butterfly.png"
image = imread(image_path)
image = im2double(image)
image = modcrop(image, scale)
blur = imfilter(image, kernel, 'replicate')
imgLR = imresize(blur, 1/scale, 'nearest')
在视频超分领域,BD中的高斯模糊参数为:kernelsize=13, sigma=1.6。相关实现可以参考如下链接中的代码:DUFDown(这里这里是采用Tesorflow进行的实现)。考虑到不少同学对于Tensorflow不熟悉,我们这里提供一版Pytorch实现(XinTao大佬提供)。
def DUF_downsample(x, scale=4):
"""Downsamping with Gaussian kernel used in the DUF official code
Args:
x (Tensor, [B, T, C, H, W]): frames to be downsampled.
scale (int): downsampling factor: 2 | 3 | 4.
"""
assert scale in [2, 3, 4], 'Scale [{}] is not supported'.format(scale)
def gkern(kernlen=13, nsig=1.6):
import scipy.ndimage.filters as fi
inp = np.zeros((kernlen, kernlen))
# set element at the middle to one, a dirac delta
inp[kernlen // 2, kernlen // 2] = 1
# gaussian-smooth the dirac, resulting in a gaussian filter mask
return fi.gaussian_filter(inp, nsig)
B, T, C, H, W = x.size()
x = x.view(-1, 1, H, W)
pad_w, pad_h = 6 + scale * 2, 6 + scale * 2 # 6 is the pad of the gaussian filter
r_h, r_w = 0, 0
if scale == 3:
r_h = 3 - (H % 3)
r_w = 3 - (W % 3)
x = F.pad(x, [pad_w, pad_w + r_w, pad_h, pad_h + r_h], 'reflect')
gaussian_filter = torch.from_numpy(gkern(13, 0.4 * scale)).type_as(x).unsqueeze(0).unsqueeze(0)
x = F.conv2d(x, gaussian_filter, stride=scale)
x = x[:, :, 2:-2, 2:-2]
x = x.view(B, T, C, x.size(2), x.size(3))
return x
BN/DN实现
接下来,我们将要介绍一下DN的实现。它是在BD的基础上添加额外的高斯白噪声,它是RDN所提出。RDN的官方代码中也提供了响应的matlab实现:Prepare_TrainData_HR_LR_DN。但不知为何这里的DN其实是BI+Noise的实现,也就是应当是Noise。但无论如何,这里关键的是Noise的生成方式,看到code后,想必各位同学可以轻易根据改成所需要的code。这里列出关键性code。
sclae = 4;
sigma = 30; %噪声水平
image_path = "butterfly.png";
image = imread(image_path);
image = im2double(image);
image = modcrop(image, scale);
imgLR = imresize(image, 1/scale, 'bicubic');
imgLR = single(imgLR)
LRNoise = imgLR + single(sigma * randn(size(imgLR)));
LRNoise = uint8(LRNoise)
上面所提供的代码为matlab代码,但相比BI,BD,这里的关键仅在于Noise的生成部分。大家可以采用Pytorch、Numpy以及Tensorflow等轻易实现。比如,Pytorch的参考实现:
noise = torch.randn(B,C,H,W).mul_(noise_level).float()
Others
上面介绍了BI、BD、BN以及BD降质原理以及实现代码。那么除了上述降质外,还有其他类型的吗?有的!但基本与上述降质大同小异,对此感兴趣的同学可以去看一下KAIR中实现的几种降质:SRMD, DPSR, USRNet。这里就不再进行过多的介绍。
注意事项
前面对图像/视频超分中的降质方案进行了简单的梳理与总结。有一点需要各位同学牢记在心:在进行方法对比时,其降质过程一定要相同,否则对比就会不公平。为什么这样说呢?见下表的结果对比。
| Degradation | Method | Scale | Dataset | PSNR | SSIM |
|---|---|---|---|---|---|
| BI | RDN | X3 | Set5 | 34.71 | 0.9296 |
| BD | RDN | X3 | Set5 | 34.58 | 0.9280 |
| BI | RCAN | X3 | Set5 | 34.74 | 0.9299 |
| BD | RCAN | X3 | Set5 | 34.70 | 0.9288 |
| BI | TDAN | X4 | Vid4 | 26.24 | 0.7800 |
| BD | TDAN | X4 | Vid4 | 26.58 | 0.8010 |
从上表可以看到:对于图像超分而言,BI与BD两种降质制作的数据训练的模型指标基本相当;而对于视频超分而言,BI与BD两种降质方式训练的模型的指标差别较大(0.34dB)。
所以研究视频超分的小伙伴一定要特别注意新方法的指标是在BD降质所得,还是BI降质所得。如果强制的将BD模型指标与BI模型指标进行对比,那么有点"贻笑大方"了。
参考
KAIR
RDN
EDVR
BasicSR
matlab_functions_verification
bicubic_pytorch
VSR-DUF
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
觉得有用,麻烦给个赞和在看~ 

















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









