





深层上下文化的单词表示
题目:
Deep contextualized word representations
作者:
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
来源:
NAACL 2018. Originally posted to openreview 27 Oct 2017. v2 updated for NAACL camera ready
Computation and Language (cs.CL)
Submitted on 25 May 2016
文档链接:
arXiv:1802.05365
代码链接:
https://github.com/zalandoresearch/flair
https://github.com/dmlc/gluon-nlp
https://github.com/allenai/bilm-tf
摘要
我们引入了一种新的深层上下文化的单词表示,它对单词使用的复杂特性(例如语法和语义)和这些用法如何在不同的语言环境中变化(例如,,以模拟一词多义)。我们的词向量是一个深层双向语言模型(biLM)的内部状态的学习函数,它是在一个大型文本语料库上预先训练的。我们表明,这些表示可以很容易地添加到现有的模型中,并通过6个具有挑战性的NLP问题(包括问题回答、文本蕴涵和情感分析)显著改善现有模型的状态。我们还提出了一项分析,显示出预先训练的网络的深层内部结构是至关重要的,允许下游模型混合不同类型的半监督信号。
英文原文
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
要点
我们介绍了一种从biLMs学习高质量的深度上下文相关表示的通用方法,并在将ELMo应用于广泛的NLP任务时显示了很大的改进。通过ablations和其他受控实验,我们也证实了biLM层可以有效地编码关于wordsin-context的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。
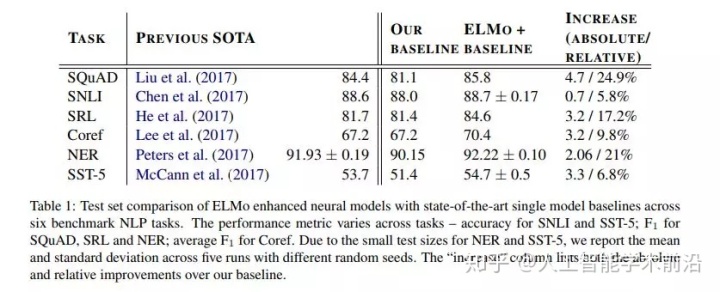
表1:在6个基准NLP任务中,ELMo增强神经模型与最先进的单模型基线的测试集比较。SNLI和SST-5的性能指标随任务精度的不同而不同;F1车队,SRL和NER;平均F1为Coref。由于NER和SST-5的测试规模较小,我们报告了五种不同随机种子的平均和标准偏差。“增加”列列出了相对于基线的绝对和相对改进。
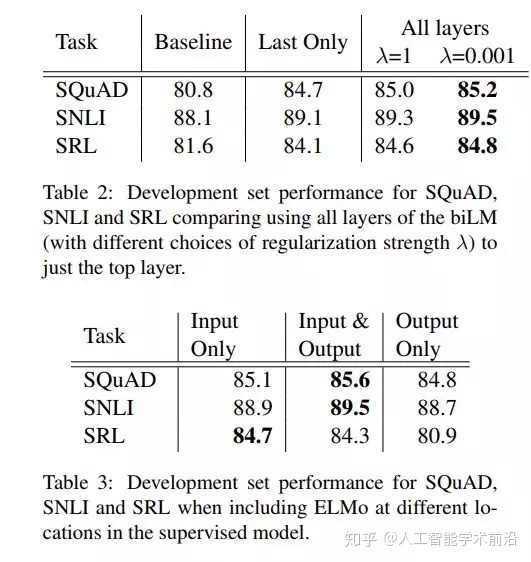
表2: SQuAD,SNLI和SRL的开发集性能比较。顶层使用biLM的所有层(不同的选择正则化强度λ)。
表3:在监督模型中包含不同位置的ELMo时,team、SNLI和SRL的开发集性能。
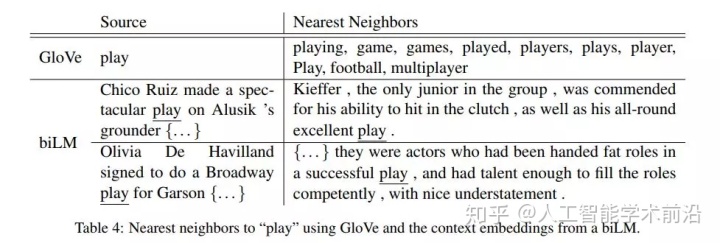
表4:使用GloVe和来自biLM的上下文嵌入来“play”最近的邻居。
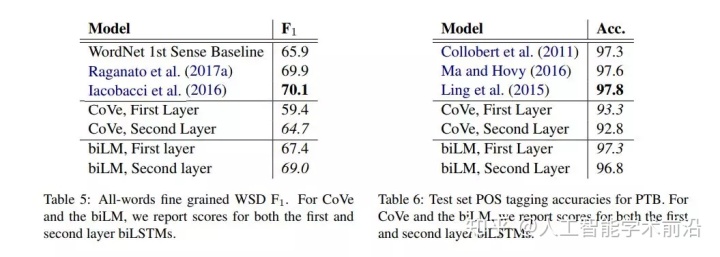
表5:全词细粒度WSD F1。对于CoVe和biLM,我们报告了第一层和第二层biLSTMs的评分。
表6:PTB的测试集POS标记准确性。为
CoVe和biLM,我们报告了第一层和第二层biLSTMs的评分。
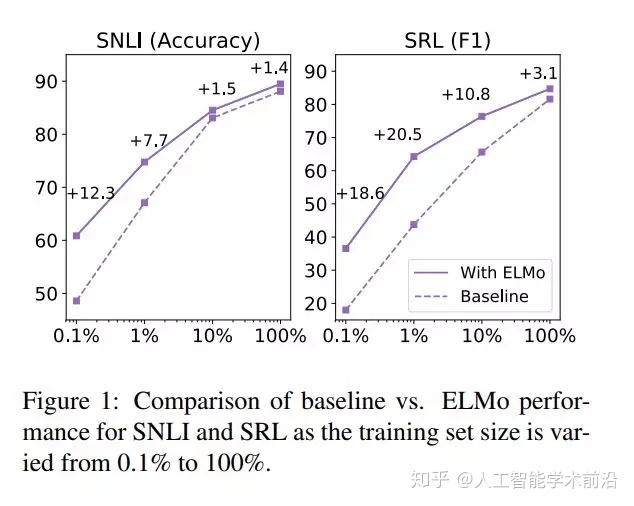
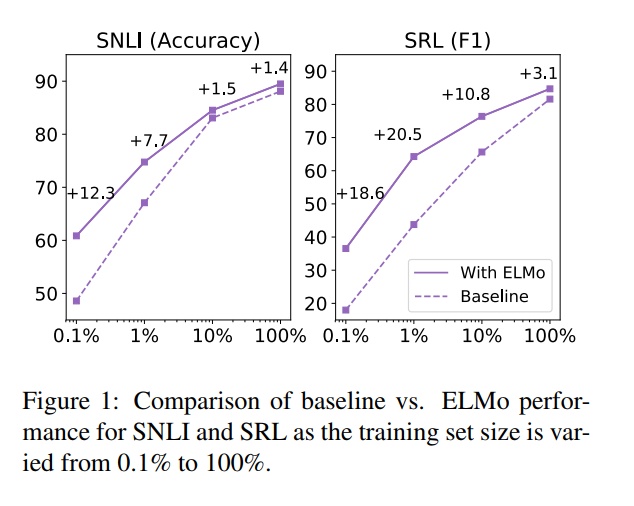
图1:训练集大小从0.1%到100%时,SNLI和SRL的基线与ELMo性能的比较。
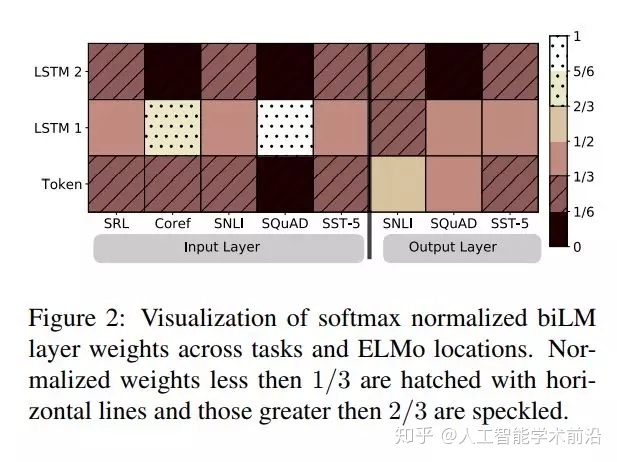
图2:softmax标准化biLM层权重跨任务和ELMo位置的可视化。小于1/3的归一化权重用水平线表示,大于2/3的权重用斑点表示。















 3499
3499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









