







前面学习了线性回归的原理,那今天来看kaggle上的一个具体案例(房价预测)。
一、提取数据
我已经将数据下载到了本地,大家可以按照我之前的这篇文章来进行数据的下载~

1、提取数据
import numpy as np
import pandas as pd
from pandas import DataFrame as df
import seaborn as sns
path = r'C:\Users\dw\Desktop\新建文件夹\kaggle_房价预测'
train_data = pd.read_csv(path + '\\train.csv')
train_data['set'] = 'train'
test_data = pd.read_csv(path + '\\test.csv')
test_data['set'] = 'test'
all_data = pd.concat([train_data, test_data], ignore_index = True)
2、衍生特征
我们也可以根据自己对数据的理解衍生变量
all_data['diff_YearBuilt'] = all_data['YrSold'] - all_data['YearBuilt']
all_data['diff_YearRemodAdd'] = all_data['YrSold'] - all_data['YearRemodAdd']
all_data['diff_GarageYrBlt'] = np.where(all_data['GarageYrBlt'].isnull(),-999999,all_data['YrSold']-all_data['GarageYrBlt'])
二、数据探索 & 数据清洗
1、整体分析
import data_analysis # 这个包我自己手写的,主要是用于分析数据的空值、单值率等情况
import seaborn as sns
###### 1.整体分析
summary = data_analysis.data_clear(all_data)
explore = all_data.describe().T
数据的空值、单值率、以及要删除的字段如下图:


- 删除空值较多、单值率较高字段
drop_cols = list(set(summary['drop_cols'].unique())-set({np.nan}))
all_data.drop(drop_cols,axis = 1,inplace = True)
- 其余空值处理
# 只有几个空值的字段,采用众数填充
all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0],inplace=True)
all_data['BsmtFullBath'].fillna(all_data['BsmtFullBath'].mode()[0],inplace=True)
all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0],inplace=True)
all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0],inplace=True)
all_data['BsmtFinSF1'].fillna(all_data['BsmtFinSF1'].mode()[0],inplace=True)
all_data['BsmtFinSF2'].fillna(all_data['BsmtFinSF2'].mode()[0],inplace=True)
all_data['BsmtUnfSF'].fillna(all_data['BsmtUnfSF'].mode()[0],inplace=True)
all_data['TotalBsmtSF'].fillna(all_data['TotalBsmtSF'].mode()[0],inplace=True)
all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0],inplace=True)
all_data['GarageCars'].fillna(all_data['GarageCars'].mode()[0],inplace=True)
all_data['GarageArea'].fillna(all_data['GarageArea'].mode()[0],inplace=True)
all_data['SaleType'].fillna(all_data['SaleType'].mode()[0],inplace=True)
# 空值为单独一类
all_data['Fence'].fillna('null',inplace=True) # 围栏:空代表没有围栏
all_data['FireplaceQu'].fillna('null',inplace=True) # 壁炉:空代表没有壁炉
all_data['GarageFinish'].fillna('null',inplace=True) # 车库完成情况:没有车库
all_data['GarageType'].fillna('null',inplace=True) # 车库位置:没有车库
all_data['GarageQual'].fillna('null',inplace=True) # 车库质量:没有车库
all_data['GarageYrBlt'].fillna(0,inplace=True) # 车库建成年份:没有车库
all_data['BsmtCond'].fillna('null',inplace=True) # 评估地下室的总体状况:没有地下室
all_data['BsmtExposure'].fillna('null',inplace=True) # 室外或花园水平的墙壁:没有地下室
all_data['BsmtQual'].fillna('null',inplace=True) # 评估地下室的高度:没有地下室
all_data['BsmtFinType1'].fillna('null',inplace=True) # 地下室完工区域的等级1:没有地下室
all_data['BsmtFinType2'].fillna('null',inplace=True) # 地下室完工区域的等级2:没有地下室
all_data['MasVnrType'].fillna('null',inplace=True) # 砌体饰面类型
all_data['MasVnrArea'].fillna(0,inplace=True) # 砌体饰面面积
# 特殊处理(地块临街面)
all_data['LotFrontage'] = all_data.groupby("Neighborhood")["LotFrontage"].transform(lambda x: x.fillna(x.median()))
2、字段相关性、异常值分析
1) 相关性
# 全部字段相关性(此处只有数值型的相关性)
coeff = all_data[all_data['set']=='train'].corr()
sns.heatmap(coeff,cmap='YlGnBu',square=True)
# 查看与目标值相关性较强的特征间的数据情况
cols10 = list(coeff.nlargest(10, 'SalePrice')['SalePrice'].index)
coeff10 = coeff.loc[cols10,cols10]
sns.heatmap(coeff10,cmap='YlGnBu',annot=True,annot_kws={'size':6,'weight':'bold','color':'white'},square=True)

2) 异常值分析及处理
# GrLivArea:地上居住面积
sns.scatterplot(x='GrLivArea',y='SalePrice',data=all_data[all_data['set']=='train'])
drop_index = all_data[all_data['set']=='train'][(all_data[all_data['set']=='train']['GrLivArea']>4000)&(all_data[all_data['set']=='train']['SalePrice']<300000)]['Id'].index
all_data.drop(drop_index,inplace=True)

# YearBuilt:建造年份
sns.scatterplot(x='YearBuilt',y='SalePrice',data=all_data[all_data['set']=='train'])
drop_index1 = all_data[all_data['set']=='train'][(all_data[all_data['set']=='train']['YearBuilt']<1900)&(all_data[all_data['set']=='train']['SalePrice']>400000)]['Id'].index
all_data.drop(drop_index1,inplace=True)

三、数据转换
1、自变量转换
## 1.自变量转换
from sklearn.preprocessing import StandardScaler
num_cols = list(set(all_data.columns[all_data.dtypes!='object'])-set(['Id','SalePrice']))
all_data[num_cols] = StandardScaler().fit_transform(all_data[num_cols])
all_data_new = pd.get_dummies(all_data)
fin_cols = list(set(all_data_new.columns)-set(['Id','SalePrice','set_test','set_train']))
train_data_new = all_data_new[all_data_new['set_train']==1][fin_cols]
test_data_new = all_data_new[all_data_new['set_test']==1][fin_cols]
2、因变量转换
## 查看因变量的分布
from scipy import stats
from matplotlib import pyplot as plt
train_y = all_data[all_data['set']=='train']['SalePrice']
test_y = pd.read_csv(path+'\\sample_submission.csv')['SalePrice']
stats.probplot(train_y, plot=plt)
sns.distplot(train_y)

# 由上图我们可以看出因变量呈现一种偏态分布,需要将其转换为正态分布
train_y_log = np.log1p(train_y)
test_y_log = np.log1p(test_y)
stats.probplot(train_y, plot=plt)
sns.distplot(train_y)

四、建模
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data_new,train_y, test_size = 0.3, random_state = 13)
# Lasso回归(L1)
from sklearn.linear_model import Lasso
lasso_model = Lasso(alpha=100, max_iter=10000, random_state=1).fit(X_train,y_train)
# 岭回归(L2)
from sklearn.linear_model import Ridge
ridge_model = Ridge(alpha=10, random_state=1).fit(X_train,y_train)
# 弹性网络回归(L1、L2)
from sklearn.linear_model import ElasticNet
elastic_model= ElasticNet(alpha=0.1, l1_ratio=0.9, max_iter=10000, random_state=1).fit(X_train,y_train)
# gboost
from sklearn.ensemble import GradientBoostingRegressor
GBoost_model = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =1).fit(X_train,y_train)
# xgboost
import xgboost as xgb
xgb_model = xgb.XGBRegressor(objective = 'reg:squarederror', n_estimators = 500, seed = 13, subsample = 0.8, learning_rate = 0.1, reg_alpha=0.01, reg_lambda = 10).fit(X_train,y_train)
# LGBM
import lightgbm as lgb
lgb_model = lgb.LGBMRegressor(objective='regression',num_leaves=5, learning_rate=0.05, n_estimators=720, max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319, feature_fraction_seed=9, bagging_seed=9,min_data_in_leaf =6,
min_sum_hessian_in_leaf = 11).fit(X_train,y_train)
# adaboost
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
ada_model = AdaBoostRegressor(base_estimator=DecisionTreeRegressor(max_depth=20),
learning_rate=1, n_estimators=500,
random_state=1).fit(X_train,y_train)
# KernelRidge
from sklearn.kernel_ridge import KernelRidge
KRR_model = KernelRidge(alpha=0.1, degree=1, kernel='polynomial').fit(X_train,y_train)
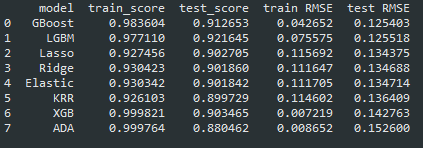
models = [lasso_model,ridge_model, elastic_model, GBoost_model, xgb_model, lgb_model, ada_model, KRR_model]
model_names = ['Lasso','Ridge','Elastic','GBoost','XGB','LGBM','ADA','KRR']
from sklearn.metrics import mean_squared_error
scoreList = []
for i, m in enumerate(models):
print(i)
score = [model_names[i]]
score.append(m.score(X_train,y_train))
score.append(m.score(X_test,y_test))
score.append(np.sqrt(mean_squared_error(np.log1p(y_train),np.log1p(m.predict(X_train)))))
score.append(np.sqrt(mean_squared_error(np.log1p(y_test),np.log1p(m.predict(X_test)))))
scoreList.append(score)
SCORES = pd.DataFrame(scoreList, columns = ['model', 'train_score', 'test_score', 'train RMSE', 'test RMSE'])
SCORES.sort_values(['test RMSE'], ascending = True, inplace = True)
SCORES.reset_index(drop=True, inplace=True)
SCORES
详细内容请看我公众号~
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









