







 本文详细介绍了Cortex-M3处理器的架构特点,包括其32位内核、哈佛结构、流水线设计、寄存器组、中断控制器NVIC的功能,以及存储器映射、总线接口和调试支持。作者强调理解和掌握寄存器和中断机制对CPU应用的重要性。
本文详细介绍了Cortex-M3处理器的架构特点,包括其32位内核、哈佛结构、流水线设计、寄存器组、中断控制器NVIC的功能,以及存储器映射、总线接口和调试支持。作者强调理解和掌握寄存器和中断机制对CPU应用的重要性。
从本小节开始,正式进入CM3的世界,废话少说,扬帆启航。
1、简介
Cortex-M3 是一个 32 位处理器内核。内部的数据路径是 32 位的,寄存器是 32 位的,存储器接口也是 32 位的。CM3 采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问通同时进行。但是另一方面,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统),寻址空间为 4GB 。 简化框图如下图所示:

CM3的内核由下面几个模块组成:
- 指令执行单元:由指令预取单元、指令译码、算数逻辑运算单元、寄存器组组成
- 跟踪调试系统
- 存储器接口:提供AHB接口信号的指令总线和数据总线。
- 中断控制器(NVIC)
- MPU:存储器保护单元
- 总线互联模块
- 调试接口:调试接口作为Master挂在内核系统总线上,且都是AHB接口。
- 总线互联模块经过译码等逻辑输出指令总线、系统总线、私有外设总线。
详细的框图
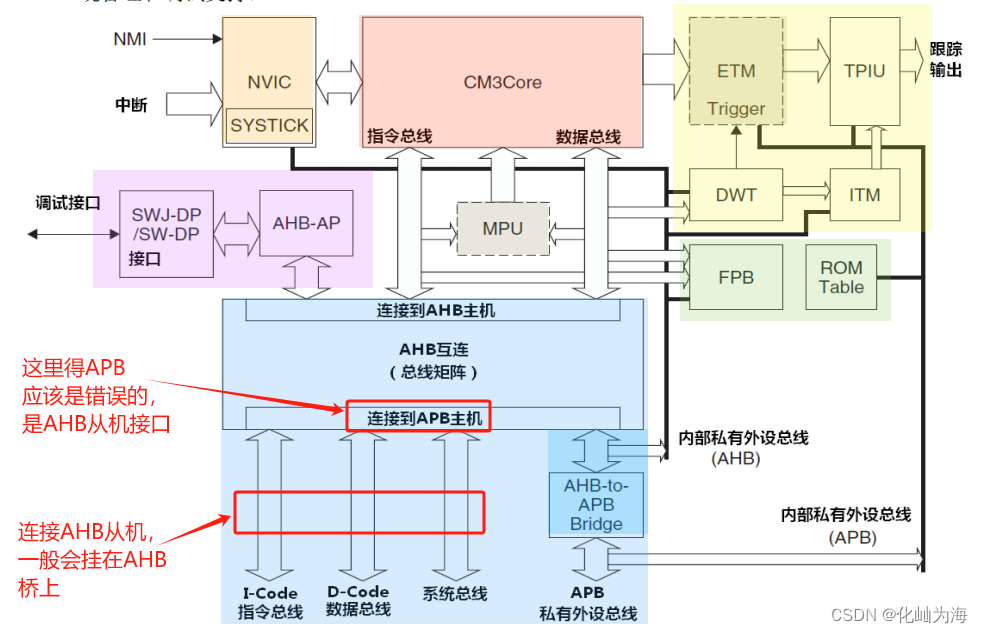
方框图中的缩写及其定义如下描述:
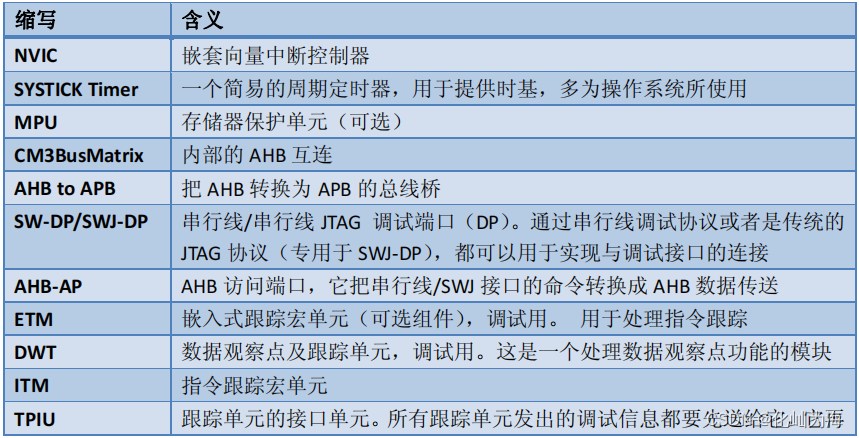

典型的连接方式
CM3中有若干个总线接口,初学者很容易混淆,也不太容易弄清楚它们是怎样与其它设备和存储器连接的。这里给出一个典型的连接实例。如下图所示:
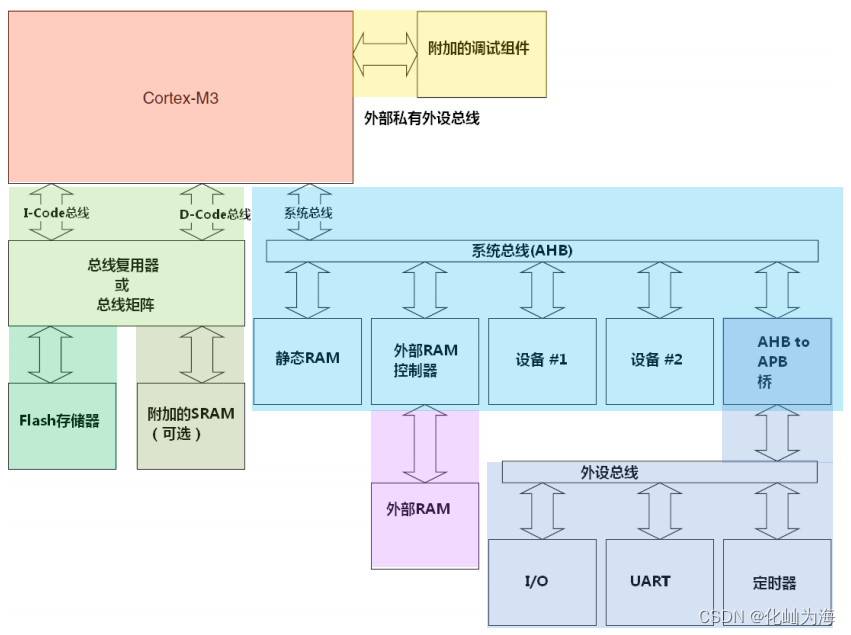
流水线
Cortex‐M3 处理器使用一个 3 级流水线。流水线的 3 级分别是:取指,解码和执行,如下图所示:
2、寄存器组
Cortex-M3 处理器拥有 R0-R15 的寄存器、和三个特殊功能寄存器。通用寄存器组如下图所示:
2.1、R0-R12:通用寄存器
R0-R12 都是 32 位通用寄存器,用于数据操作。绝大多数16位Thumb指令只能访问 R0-R7,而 32 位 Thumb-2 指令可以访问所有寄存器。
2.2、R13: 堆栈指针
Cortex-M3 拥有两个堆栈指针,它们是 banked,但是任一时刻只能使用其中的一个。
- 主堆栈指针(MSP):复位后缺省使用的堆栈指针,用于操作系统内核以及异常处理例程(包
括中断服务例程) - 进程堆栈指针(PSP):由用户的应用程序代码使用。
堆栈指针的最低两位永远是 0,这意味着堆栈总是 4 字节对齐的。
2.3、R14:连接寄存器
当呼叫一个子程序,或者执行异常接口时,由 R14 存储返回地址。
2.4、特殊功能寄存器
Cortex-M3 在内核水平上搭载了三个特殊功能寄存器,包括
- 程序状态字寄存器组(PSRs)
- 中断屏蔽寄存器组(PRIMASK, FAULTMASK, BASEPRI)
- 控制寄存器(CONTROL)
特殊寄存器框图如下图所示:

xPSR:记录 ALU 标志(0 标志,进位标志,负数标志,溢出标志),执行状态,以及当前正服务的中断号。
PRIMASK:除能所有的中断,NMI中断除外。
FAULTMASK:除能所有的 fault,NMI 依然不受影响,而且被除能的 faults 会“上访”,
BASEPRI:除能所有优先级不高于某个具体数值的中断。
CONTROL:定义特权状态,并且决定使用哪一个堆栈指针。
3、操作模式和特权极别
Cortex-M3 处理器支持两种处理器的操作模式,和支持两级特权操作。
两种操作模式分别为:处理者模式(handler mode)和线程模式(thread mode)。
两种特权级分别为:特权级和用户级。这提供一种存储器访问的保护机制,使得普通的用户程序代码不能意外地,甚至是恶意地执行涉及到要害的操作。处理器支持两种特权级,这也是一个基本的安全模型。特权和操作模式对应模式如下图所示,没有用户处理者模式。

在 CM3 运行主应用程序时(线程模式),既可以使用特权级,也可以使用用户级;但是异常服务例程必须在特权级下执行。复位后,处理器默认进入线程模式,特权极访问。在特权级下,程序可以访问所有范围的存储器(如果有 MPU,还要在 MPU 规定的禁地之外),并且可以执行所有指令。在特权级下的程序可以为所欲为,但也可能会把自己给玩进去——切换到用户级。一旦进入用户级,再想回来就得走“法律程序”了——用户级的程序不能简简单单地试图改写 CONTROL 寄存器就回到特权级,它必须先“申诉”:执行一条系统调用指令(SVC)。这会触发 SVC 异常,然后由异常服务例程(通常是操作系统的一部分)接管,如果批准了进入,则异常服务例程修改CONTROL 寄存器,才能在用户级的线程模式下重新进入特权级。事实上,从用户级到特权级的唯一途径就是异常:如果在程序执行过程中触发了一个异常,处理器总是先切换入特权级,并且在异常服务例程执行完毕退出时,返回先前的状态。三种特权级模式切换如下图所示:

4、内建的嵌套向量中断控制器
Cortex-M3 在内核水平上搭载了一颗中断控制器——嵌套向量中断控制器 NVIC(Nested Vectored Interrupt Controller)。它与内核有很深的“亲密接触”——与内核是紧耦合的。NVIC 提供如下的功能:
- 可嵌套中断支持
- 向量中断支持
- 动态优先级调整支持
- 中断延迟大大缩短
- 中断可屏蔽
ARMv7-M开创了一个全新的异常模型,CM3 采用了它。这种异常模型跟传统 ARM 处理器使用的完全是两码事。新的异常模型“使能”了非常高效的异常处理。它支持16-4-1=11种系统异常(保留了4+1个档位),外加240个外部中断输入。在CM3中取消了 FIQ 的概念(v7 前的 ARM 都有这个 FIQ,快中断请求),这是因为有了更新更好的机制——中断优先级管理以及嵌套中断支持,它们被纳入 CM3 的中断管理逻辑中。因此,支持嵌套中断的系统就更容易实现FIQ。CM3的所有中断机制都由NVIC实现。除了支持240条中断之外,NVIC 还支持 16-4-1=11 个内部异常源,可以实现 fault 管理机制。结果,CM3 就有了 256 个预定义的异常类型。异常类型如下表所示:

5、存储器映射
Cortex-M3 支持 4GB 存储空间,不像其它的 ARM 架构,它们的存储器映射由半导体厂家说了算。Cortex-M3 预先定义好了“粗线条的”存储器映射,将4G的空间分成了6个BANK。芯片生产厂商需要根据定好的空间经行地址分配。这么做的原因,有助于Core以及用户程序的代码移植,提高了开发效率。地址分配空间如下图所示。

6、Cortex-M3 的总线接口
Cortex-M3 内部有若干个总线接口,以使 CM3 能同时取址和访内(访问内存),它们是:
- 指令存储区总线(两条)
- 系统总线
- 私有外设总线
总线在架构框图的位置如下所示:

两条代码存储区总线负责对代码存储区的访问,分别是 I-Code 总线和 D-Code 总线。前者用于取指,后者用于查表等操作。(重点理解)
I-Code 总线
I‐Code 总线是一条基于 AHB‐Lite 总线协议的 32 位总线,负责在 0x0000_0000 –0x1FFF_FFFF之间的取指操作。取指以字的长度执行,即使是对于16 位指令也如此。因此CPU 内核可以一次取出两条 16 位Thumb 指令。
D-Code 总线
D‐Code 总线也是一条基于 AHB‐Lite 总线协议的 32 位总线,负责在 0x0000_0000 –0x1FFF_FFFF之间的数据访问操作。尽管 CM3 支持非对齐访问,但你绝不会在该总线上看到任何非对齐的地址,这是因为处理器的总线接口会把非对齐的数据传送都转换成对齐的数据传送。因此,连接到 D‐Code 总线上的任何设备都只需支持 AHB‐Lite 的对齐访问,不需要支持非对齐访问。
系统总线
系统总线用于访问内存和外设,覆盖的区域包括 SRAM,片上外设,片外 RAM,片外扩展设备,以及系统级存储区的部分空间。系统总线也是一条基于 AHB‐Lite 总线协议的 32 位总线,负责在 0x2000_0000 –0xDFFF_FFFF 和 0xE010_0000 –0xFFFF_FFFF 之间的所有数据传送,取指和数据访问都算上。和 D‐Code 总线一样,所有的数据传送都是对齐的。
外部私有外设总线
私有外设总线负责一部分私有外设的访问,主要就是访问调试组件。它们也在系统级存储区。这是一条基于 APB 总线协议的 32 位总线。此总线来负责 0xE004_0000 – 0xE00F_FFFF 之间的私有外设访问。但是,由于此 APB 存储空间的一部分已经被 TPIU、ETM 以及 ROM 表用掉了,就只留下了 0xE004_2000‐E00F_F000 这个区间用于配接附加的(私有)外设。
7、指令集
Cortex-M3 只使用 Thumb-2 指令集。它允许 32 位指令和 16 位指令水乳交融,代码密度与处理性能两手抓,两手都硬。而且虽然它很强大,却依然易于使用。在过去,做 ARM 开发必须处理好两个状态。这两个状态是井水不犯河水的,它们是:32 位的ARM 状态和 16 位的 Thumb 状态。当处理器在 ARM 状态下时,所有的指令均是 32 位的(哪怕只是个”NOP”指令),此时性能相当高。而在 Thumb 状态下,所有的指令均是 16 位的,代码密度提高了一倍。不过,thumb 状态下的指令功能只是ARM下的一个子集,结果可能需要更多条的指令去完成相同的工作,导致处理性能下降。为了取长补短,很多应用程序都混合使用 ARM 和 Thumb 代码段。然而,这种混合使用是有额外开销(overhead)的,时间上的和空间上的都有,主要发生在状态切换之时。另一方面,ARM 代码和 Thumb 代码需要以不同的方式编译,这也增加了软件开发管理的复杂度。
传统ARM状态切换如下如所示。

伴随着 Thumb-2 指令集的横空出世,Cortex-M3 内核干脆都不支持 ARM 指令,中断也在 Thumb 态下处理,它使CM3 在好几个方面都比传统的 ARM 处理器更先进:
- 消灭了状态切换的额外开销,节省了 both 执行时间和指令空间。
- 不再需要把源代码文件分成按 ARM 编译的和按 Thumb 编译的,软件开发的管理大大减负。
- 无需再反复地求证和测试:究竟该在何时何地切换到何种状态下,我的程序才最有效率。开发
软件容易多了。
8、存储器保护单元(MPU)
Cortex-M3 有一个可选的存储器保护单元。配上它之后,就可以对特权级访问和用户级访问分别施加不同的访问限制。当检测到犯规(violated)时,MPU 就会产生一个 fault 异常,可以由fault 异常的服务例程来分析该错误,并且在可能时改正它。
9、调试支持
Cortex-M3 在内核水平上搭载了若干种调试相关的特性。最主要的就是程序执行控制,包括停机(halting)、单步执行(stepping)、指令断点、数据观察点、寄存器和存储器访问、性能速写(profiling)以及各种跟踪机制。
Cortex-M3 的调试系统基于 ARM 最新的 CoreSight 架构。不同于以往的 ARM 处理器,内核本身不再含有 JTAG 接口。取而代之的,是 CPU 提供称为“调试访问接口(DAP)”的总线接口。通过这个总线接口,可以访问芯片的寄存器,也可以访问系统存储器,甚至是在内核运行的时候访问!对此总线接口的使用,是由一个调试端口(DP)设备完成的。DPs 不属于 CM3 内核,但它们是在芯片的内部实现的。目前可用的 DPs 包括 SWJ-DP(既支持传统的 JTAG 调试,也支持新的串行线调试协议),另一个 SW-DP 则去掉了对 JTAG 的支持。另外,也可以使用 ARM CoreSignt 产品家族的 JTAG-DP模块。这下就有 3 个 DPs 可以选了,芯片制造商可以从中选择一个,以提供具体的调试接口(通常都是选 SWJ-DP)。
此外,CM3 还能挂载一个所谓的“嵌入式跟踪宏单元(ETM)”。ETM 可以不断地发出跟踪信息,这些信息通过一个被称为“跟踪端口接口单元(TPIU)”的模块而送到内核的外部,再在芯片外面使用一个“跟踪信息分析仪”,就可以把 TIPU 输出的“已执行指令信息”捕捉到,并且送给调试主机——也就是 PC。
在 Cortex-M3 中,调试动作能由一系列的事件触发,包括断点,数据观察点,fault 条件,或者是外部调试请求输入的信号。当调试事件发生时,Cortex-M3 可能会停机,也可能进入调试监视器异常 handler。具体如何反应,则根据与调试相关寄存器的配置。
10、总结
对于CPU的学习,我觉得应该重点理解寄存器组的信息和使用方式,以及CPU的中断机制(不同的CPU对中断处理的方式多少是有差异的),只有熟知了这些东西,才会对汇编指令编写,以及操作系统移植有更深入的认识。本人也是曾经在RISCV内核平台移植过UCOS II系统,遇到很多坑,在此过程中,我越发的觉得 Cortex-M3设计的巧妙之处,对设计CPU的工程师由衷的感到钦佩。当然这也不是说RISCV不如Cortex-M3。把Cortex-M3知识掌握对了解其他的CPU架构是有很大的帮助的。学会一款CPU的指令架构后,你会有不一样眼光去看CPU的知识,这里面是有很大的智慧的。
最后希望看过我文档的同学,对于写的好文档帮忙点个赞,或者评论一下,不好的地方请指出来,我必会改善。你们每一个点赞都是我坚持下去的动力。谢谢!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









