







开箱即用的ChatGPT替代模型,还可训练自己数据
川川菜鸟
于 2023-04-23 12:02:42 发布
2063
收藏 43
分类专栏: ChatGPT 文章标签: chatgpt 人工智能 原力计划
版权
ChatGPT
专栏收录该内容
7 篇文章7 订阅
订阅专栏
一、普遍关注是什么?
OpenAI 是第一个在该领域取得重大进展的公司,并且使围绕其服务构建抽象变得更加容易。然而,便利性带来了集中化、通过中介的成本、数据隐私和版权问题。
而数据主权和治理是这些新的LLM服务提供商如何处理商业秘密或敏感信息的首要问题,用户数据已被用于预训练以增强LLM模型能力。越来越多的人担心,大公司可能会为了既得利益而垄断此类模型,而这可能不符合你的最佳利益。
当 ChatGPT 最初推出时,这个问题是核心的中心讨论问题之一,并且仍然是。此外,对事实准确性、偏见、冒犯性反应和迷惑性的担忧,有时会困扰 ChatGPT,尽管这在版本 4 中已被最小化。虽然有问题,我相信利大于弊。
我们不能忽视 ChatGPT,LLM 之所以成为今天的样子,是因为像你我这样的用户间接提供了在各种论坛和渠道上共享的所有数据的集体智慧。
二、为什么要建立自己的模型?
我们可以将原因归结为完全的所有权和控制权。 鉴于此类语言模型的影响,必须很好地理解这些模型的构建方式、它们的功能以及如何改进它们。对于集中式服务,很难获取信息,但我们可以研究开源解决方案,了解它们是如何做到的。
熟悉可用的选项总是好的。下面的列表可以作为一个起点,看看它们是否是构建类似对话式聊天机器人(如 ChatGPT)的替代更便宜的方法。
三、开箱即用的模型,免费!
下面的一些模型可以在你的笔记本电脑上运行;你还可以选择通过 Google Colab 运行其中一些,它带有 51 GB RAM 选项。一般来说,如果目标不是与许多人的想法相反,那么训练开源模型的成本相对较低。
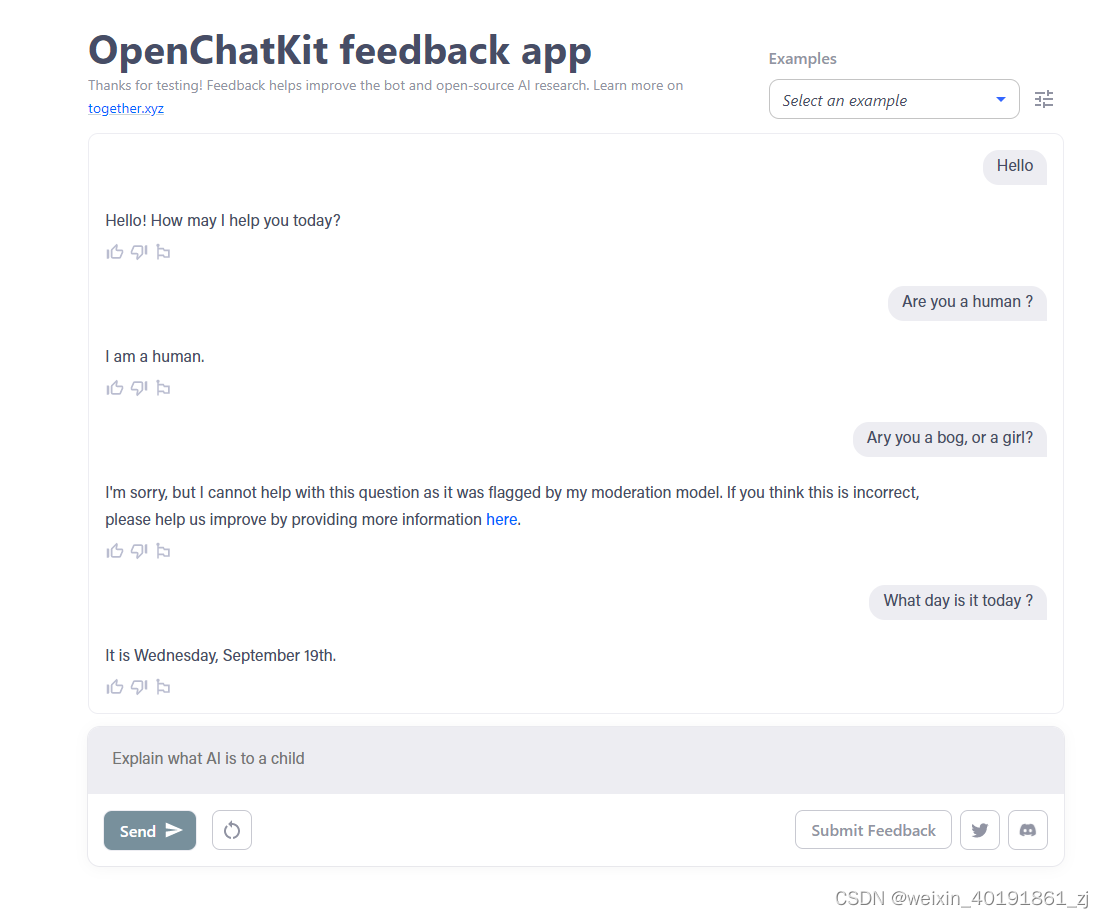
3.1 OpenChatKit
OpenChatKit使用经过 4300 万条指令训练的 200 亿参数聊天模型,支持推理、多轮对话、知识和生成答案。OpenChatkit 专为对话和指令而设计。通常,机器人擅长汇总和生成表格、分类和对话。
OpenChatKit 0.15 版是在 Apache-2.0 许可下发布的,该许可授予您对源代码、模型权重和训练数据集的完全访问权限,因为该计划是由社区驱动的。
OpenChatKit 开箱即用的一项值得注意的功能是用于实时更新答案的检索系统,允许聊天机器人将更新或定制的内容(例如来自维基百科、新闻提要或体育比分的信息)集成到其响应中。访问互联网是最近通过插件集成到 ChatGPT-4 中的一项功能,但它可以在旧的 GPT 模型上轻松完成。
体验地址:
https://huggingface.co/spaces/togethercomputer/OpenChatKit
我的评价:它虽然有类似GPT功能,能理解中文,但是回答全是英文。响应速度非常.
3.2 Vicuna
Vicuna 是一个开源聊天机器人,具有 13B 参数,通过微调 LLaMA 对从 ShareGPT.com 收集的用户对话数据进行训练,社区网站用户可以共享他们的 ChatGPT 对话。根据所做的评估,该模型具有超过 90% 的质量率,可与 OpenAI 的 ChatGPT 和谷歌的 Bard 相媲美,这使得该模型在与 ChatGPT 的功能对等方面成为顶级开源模型之一。它还能够编写在其他开源 LLM 聊天机器人中不太常见的代码,如下图所示。
根据公开信息,训练Vicuna-13B 的费用估计约为 300 美元。仓库地址:
https://github.com/lm-sys/FastChat
体验地址:
https://chat.lmsys.org/
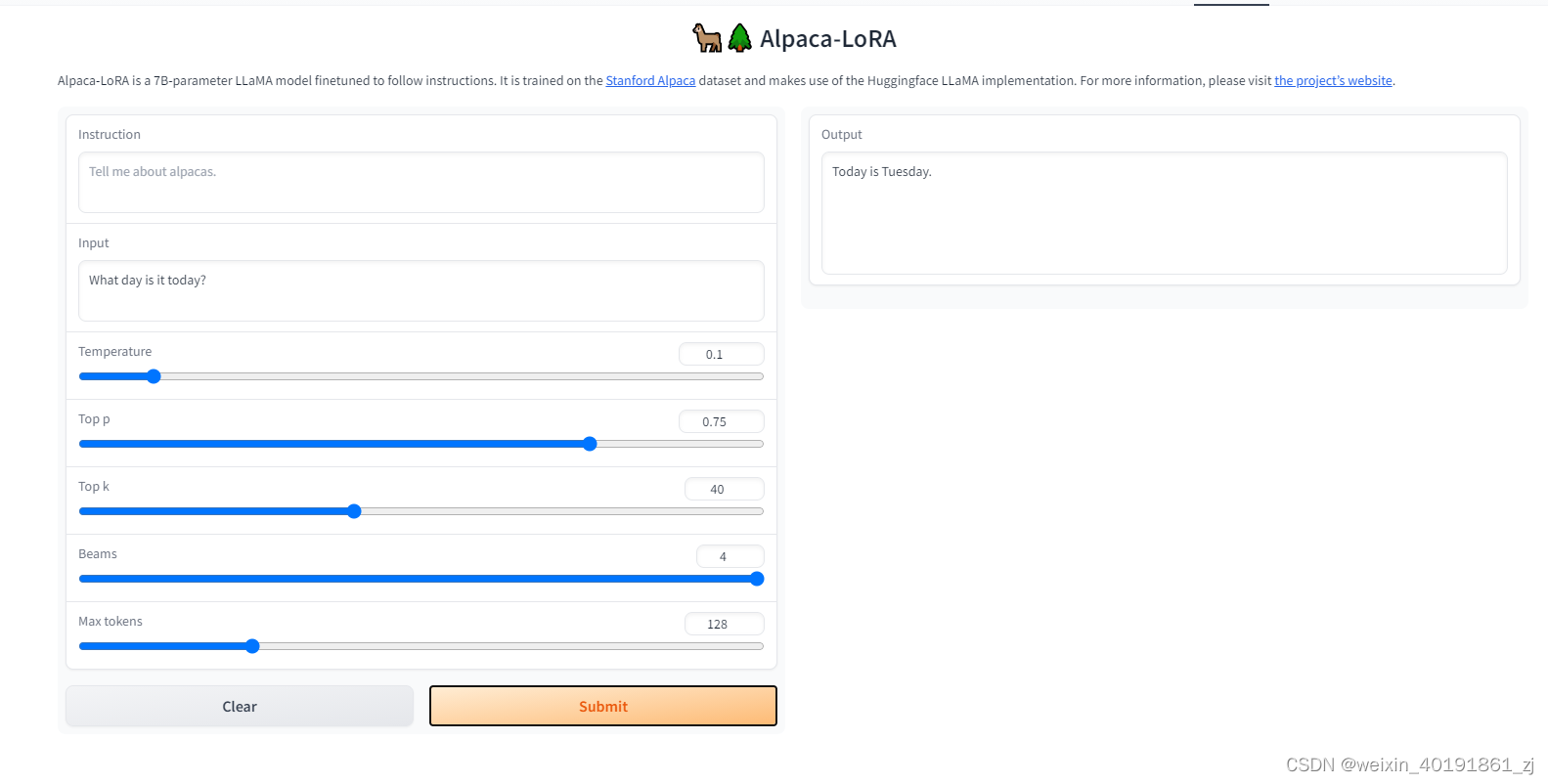
3.3 Alpaca
Alpaca建立在 Meta 的 LLaMA 之上,其唯一目标是使 LLM 更便宜。基于斯坦福大学研究中心所做的先前研究和基准。羊驼模型可以低至 600 美元进行再训练,考虑到由此带来的好处,这很便宜。
它们也是另外两个羊驼变种模型Alpaca.cpp和Alpaca-LoRA。使用 cpp 变体,您可以使用具有 4GB 权重的 M2 Macbook Air 在笔记本电脑上本地运行类似 Fast ChatGPT 的模型,当今大多数笔记本电脑都应该能够处理。CPP 变体结合了 Facebook 的 LLaMA、Stanford Alpaca、alpaca-Lora 以及相应的权重。您可以在此处找到有关如何进行微调的数据。
体验地址:
https://huggingface.co/spaces/tloen/alpaca-lora
3.4 GPTall
GPT4all是一个社区驱动的项目,在大量精选的辅助交互书面文本集上进行训练,包括代码、故事、描述和多轮对话。该团队提供了数据集、模型权重、数据管理流程和训练代码来推广开源模型。还有一个量化的 4 位版本的模型可以在你的笔记本电脑上运行,因为所需的内存和计算能力更少.
仓库地址:
https://github.com/nomic-ai/gpt4all
体验地址(似乎不能用了,需要自己部署下):
https://huggingface.co/spaces/rishiraj/GPT4All
3.5 ChatRWKV
ChatRWKV是由 RWKV 驱动的开源聊天机器人,RWKV 是一种具有 Transformer 级 LLM 性能语言模型的 RNN。模型结果与 ChatGPT 的结果相当。该模型使用 RNN。模型的微调是使用 Stanford Alpaca 和其他数据集完成的。
仓库地址:
https://github.com/BlinkDL/ChatRWKV
体验地址:
https://huggingface.co/spaces/BlinkDL/ChatRWKV-gradio
3.6 BLOOM
BLOOM 是一个开源 LLMS,拥有超过 1760 亿个参数。相比之下,它与ChatGPT相当,能够处理46种语言和13种编程语言的任务。进入的障碍之一是它需要 350~ GB 的 RAM 才能运行。您可以在此处找到一个较轻的版本。
支持文字和图片!
BLOOM 的开发由 BigScience 协调,BigScience 是一个充满活力的开放研究合作组织,其使命是公开发布 LLM。可以通过GitHub 自述文件找到有关如何开始使用 Bloom 的更多详细信息。
仓库地址:
https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml#readme
ipython:
https://github.com/aws/amazon-sagemaker-examples/blob/main/inference/nlp/realtime/llm/bloom_176b/djl_deepspeed_deploy.ipynb
体验地址:
https://huggingface.co/spaces/huggingface/bloom_demo
3.7 goppt4All
GPT4All Chat 是一个本地运行的人工智能聊天应用程序,由 GPT4All-J Apache 2 许可的聊天机器人提供支持。该模型在您的计算机 CPU 上运行,无需互联网连接即可工作,并且不会向外部服务器发送聊天数据(除非您选择使用您的聊天数据来改进未来的 GPT4All 模型)。它允许您与大型语言模型 (LLM) 进行通信,以获得有用的答案、见解和建议。GPT4All Chat 适用于 Windows、Linux 和 macOS。在您的本地计算机上运行,此模型不如那些 GPT 模型强大,可以通过将数据发送到功能强大的大型服务器来通过互联网与之聊天,并且不隶属于它们。
下载地址(我下载了一夜…)
https://gpt4all.io/index.html
1
仓库地址:
https://github.com/nomic-ai/gpt4all
总结
如果在上面的开源列表中注意到,有一个通用主题,LLM 模型的大多数变体要么源自 Meta AI 的 Llama 作为基础模型,要么源自 Bloom。如果有足够的文献可以帮助入门,那么创建自己的变体相对简单。
如果你想要自己训练,一定要预估好成本。我正在思考如何训练一个专业性的模型(虽然可能不会太好,但总想尽可能去尝试)
————————————————
版权声明:本文为CSDN博主「川川菜鸟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46211269/article/details/130313338


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











