







每日读报的时候看到的。作者来自玛丽女王伦敦大学等等几个不认识的大学。
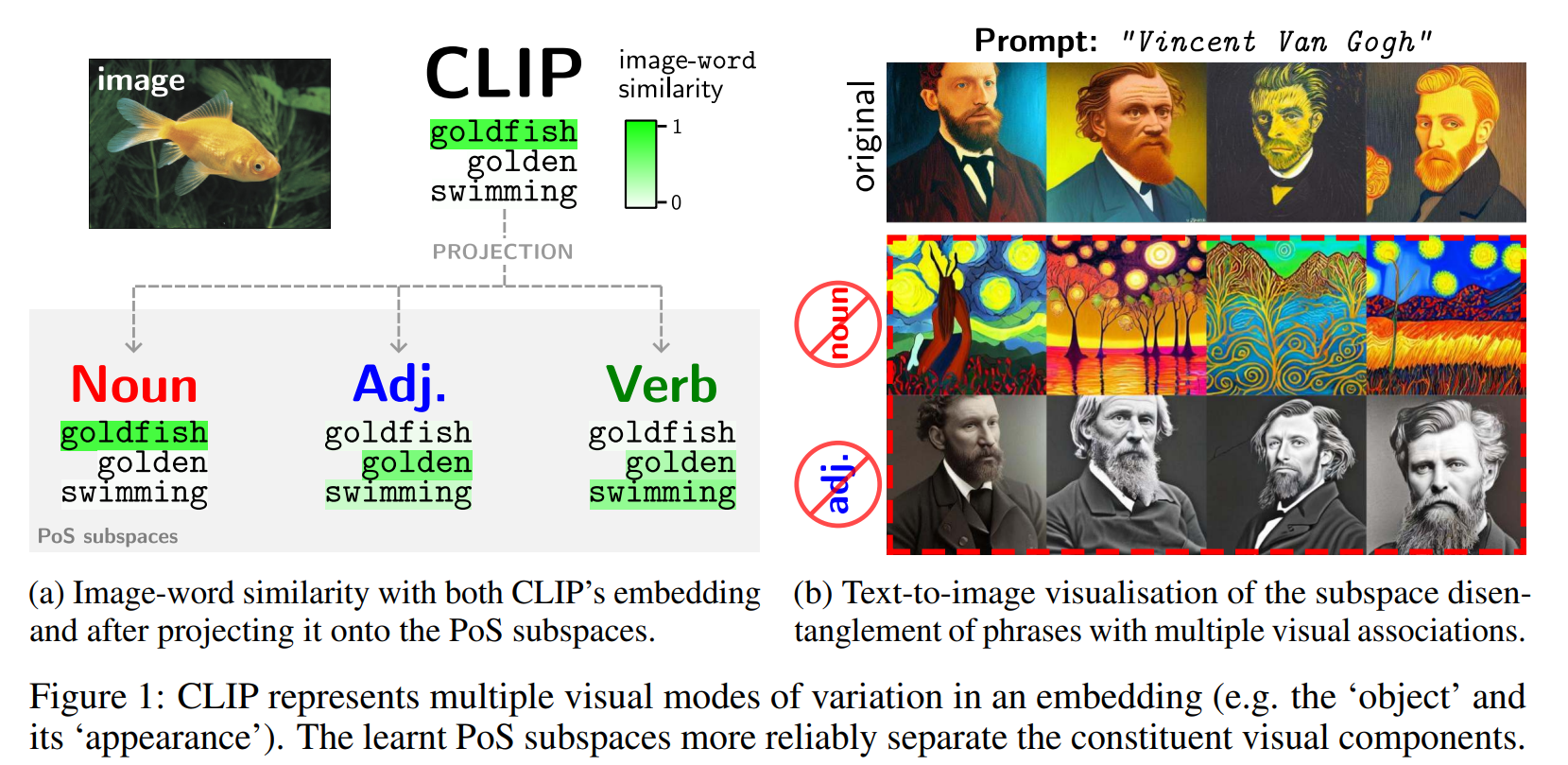
作者提出CLIP这种图文对训练,其实它的image feature把各种维度的feature都融合在一起了。
比如左图这张金鱼的照片,CLIP的一整个图片feature其实包含了三种维度的信息。从名词上来说,可以是金鱼;从形容词上来说,可以是金色的;从动词上来说,可以是游泳。
本文就是想把这些混合在一起的特征去解耦出来,效果展示在右边。(为了实现可视化,作者采用了一个基于CLIP的文生图模型)
可以看到,对于文森特梵高,CLIP出来的是文森特本人的照片,混合以他的作品的色彩风格。但是经过作者模型解耦之后,去除noun的结果,就剩下adj类的特征,所以第二行出现的是文森特作品风格的类似图片。
去除adj的结果,就是只剩下noun也就是事实性的特征,所以第三行是文森特本人。
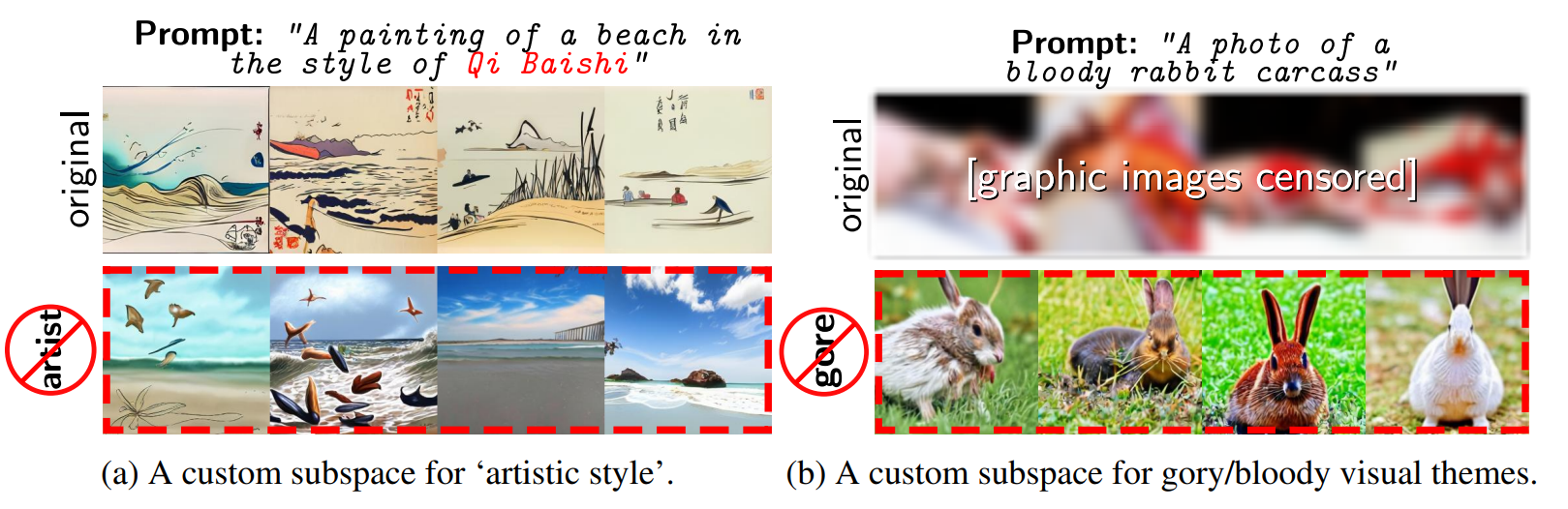
个人觉得这个思路非常新颖。包括后面作者还展示了其他的一些用法,能去除artist风格影响,还能去除血腥画面风格:















 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









