






1. 索引
1.1 索引优化
原理:查找过程
B+Tree索引的检索原理图如下:
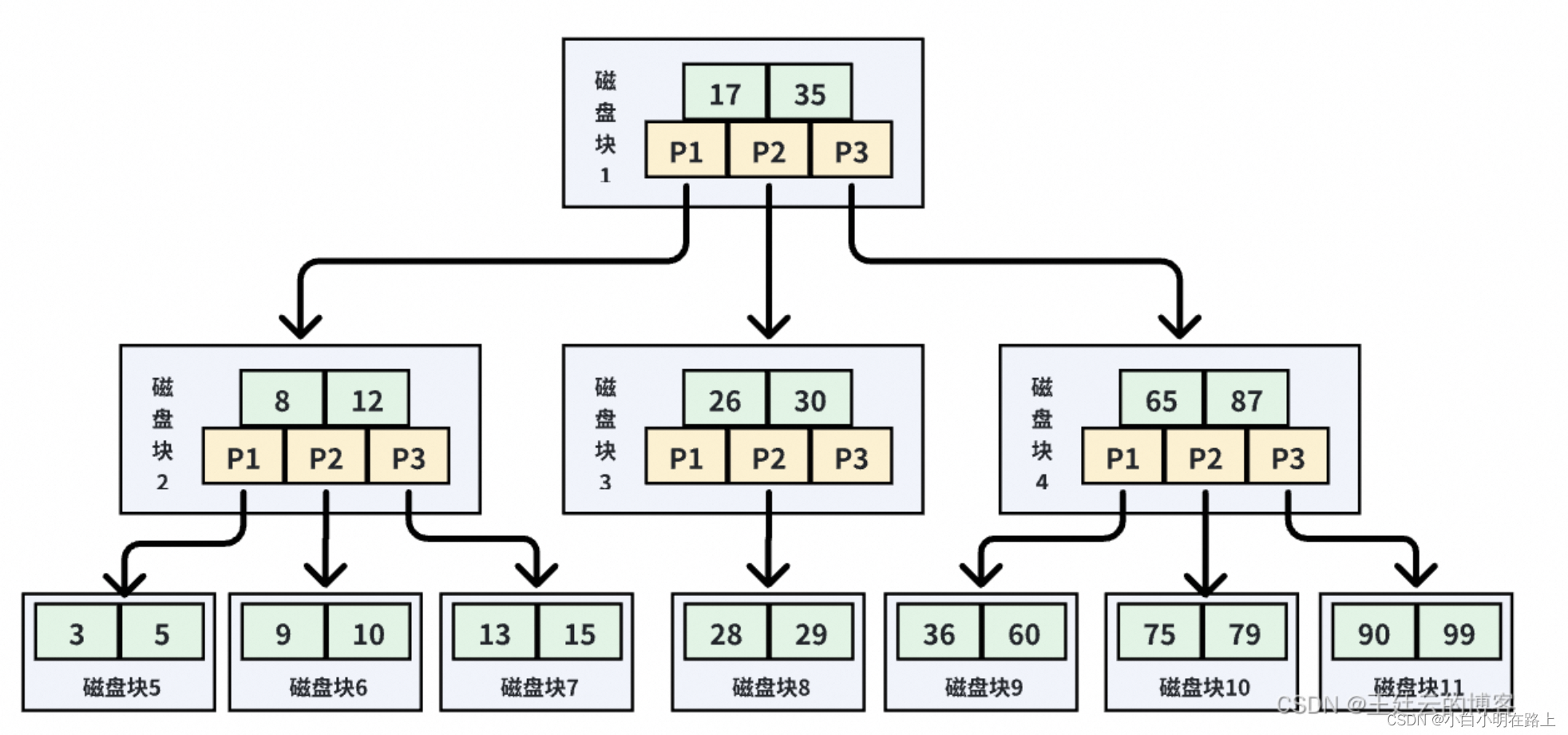
这是一颗典型的 B+ 树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),比如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3。P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。
真实的数据存在于叶子节点,即最下面的数据块:3、5、9、10、13、15 等。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中。
B+ 树的查找过程如下:
如果要查找数据项为 29,那么首先会把磁盘块 1 由磁盘加载到内存,此时发生一次 IO;
在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO;
29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指针,通过指针加载磁盘块 8 到内存,发生第三次IO,同时内存中做二分查找找到 29,结束查询,总计三次 IO
索引优化建议
1、尽可能全值匹配
尽量使用 = 来全值匹配,使用不等于(!= 或者<>)的时候无法使用索引进而导致全表扫描。使用 is null、is not null 也无法使用索引。
对于字符串来说,全值匹配时命中索引几率是最高的,如果要对字符串使用 like 模糊查询,不要把通配符 % 放在开头('%abc...'),这会导致索引失效,进而变成全表扫描。
2、不要在索引列上做运算
如果查询条件中含有函数或表达式,将导致索引失效而进行全表扫描。
3、遵循最左匹配原则
对于复合索引,应该遵循最左匹配原则,更多知识可以参考:【MySQL】之联合索引与最左匹配原则。
4、尽量避免使用 OR 操作符
查询条件如果使用了 OR 操作符,那么 MySQL 在执行查询时,需要分别使用到与 OR 操作符相关的多个子查询语句,这不仅就意味着 MySQL 需要执行多次查询增加数据库的负担,而且,如果 OR 操作符涉及的多个字段没有建立合适的索引,那么 MySQL 就需要对所有数据进行全表扫描,这样就会导致索引失效。
为了避免索引失效,有以下几点建议:
尽量避免在查询语句中使用 OR 操作符。
为涉及到 OR 操作符的多个字段建立合适的索引。
使用 UNION 操作符代替 OR 操作符,这样可以避免 OR 操作带来的性能问题。
5、不要使用含有 NULL 值的列作为索引
只要列中包含有 NULL 值都不应该被包含在索引中,复合索引中只要有一列含有 NULL 值,那么这一列对于此复合索引就是无效的。所以在数据库设计时不要让字段的默认值为 NULL。
6、尽量选择区分度高的列作为索引
区分度的公式是 count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是 1,而一些状态、性别字段可能在大数据面前区分度就是 0。一般需要 join 的字段都要求区分度 0.1 以上,即平均 1 条扫描 10 条记录。
7、尽可能覆盖索引
上面我们也讲解了什么是覆盖索引:如果一个索引包含所有需要的查询的字段的值,我们称之为覆盖索引。覆盖索引是非常有用的工具,能够极大的提高性能。因为只需要读取索引,而无需读表,极大减少数据访问量,这也是不建议使用 Select * 的原因
怎么避免索引失效(也属于sql优化的一种)
①某列使用范围查询(>、<、like、between and)时, 右边的所有列索引也会失效。
②不要对索引字段进行运算。
③在where子句中不要使用 OR、!=、<>和对值null的判断。
④避免使用’%'开头的like的模糊查询。
⑤字符串不加单引号,造成索引失效。
1.2 order by、group by如何走索引
一篇文章彻底搞懂MySql之order by索引优化、文件排序原理(进阶篇)_mysql order by 索引-CSDN博客
order by和group优化总结
1、MySQL支持两种方式的排序filesort(外部排序、又称文件排序)和index(索引排序),Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
2、order by满足两种情况会使用Using index。
1) order by语句使用索引最左前列。
2) 使用where子句与order by子句条件列组合满足索引最左前列。
where子句中如果出现索引的范围查询(explain中出现range)会导致order by 索引失效
3、尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则。
4、如果order by的条件不在索引列上,就会产生Using filesort。
5、能用覆盖索引尽量用覆盖索引
6、group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对于group by的优化如果不需要排序的可以加上order by null禁止排序。注意,where高于having,能写在where中的限定条件就不要去having限定了
Using filesort文件排序原理
双路排序
MYSQL4.1之前是使用的双路排序,字面意思就是两次扫描磁盘,最终得到数据
去读行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中兑取对应的数据输入
从磁盘中取排序字段,在buffer进行排序,在从磁盘去其他字段
取一批数据,要对磁盘进行两次扫描,总所周知,I/O是非常耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序
单路排序
从磁盘读取查询需要的所有列,按照order by列在buffer对他们进行排序,然后扫描排序后的列表进行输出
他的效率更快一些,因为避免了第二次读取数据。并且把随机的IO变成了顺序的IO,但是他会使用更多的空间,因为他把每一行都保存在了内存中
1.3 索引下推
指的是在联合索引中,当搜索的索引字段被中断后,在遍历已确定要回表的结果集中继续使用后面的索引字段进行匹配,只有匹配到的才回表查询的机制,它只能作用于二级索引。
比如现在有一个user表,将username和age设为联合索引,现在要查询姓张的并且年龄为20的用户,如果没有索引下推,根据最左前缀法则,当查出所有姓张的用户数据之后他就不会再根据年龄来继续匹配了,而是将查询出的所有数据逐一进行回表,再去根据年龄匹配。引入索引下推的话,当查出所有姓张的用户数据之后,会先根据年龄进行匹配,匹配成功的数据才进行回表,大大减少了回表的次数
2. 事务与锁
2.1 什么是事务?
一组原子性的 SQL 语句,或者说一个独立的工作单元。(由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。)
- 事务拥有 ACID(原子性、一致性、隔离性、持久性)四个特性。
- 事务通过 日志文件(undo log 和 redo log)实现可靠性。
- 事务通过 隔离级别 实现并发处理。
- 实现事务功能的三个技术:日志文件(redo log 和 undo log)、锁技术、MVCC。
2.2 事务特性
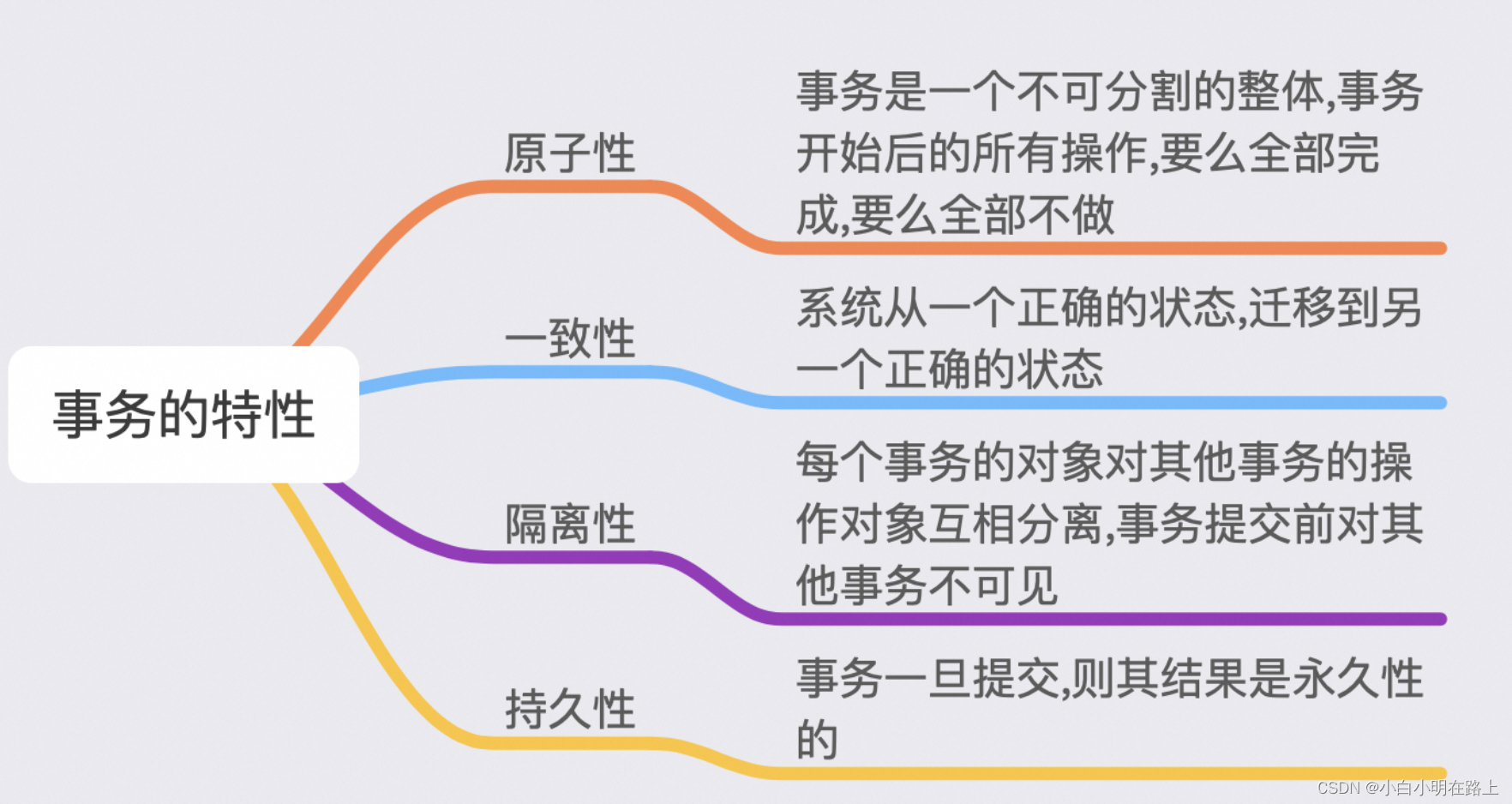
- 原子性:使用 undo log,从而达到回滚。
- 持久性:使用 redo log,从而达到故障后恢复。
- 隔离性:使用锁以及 MVCC,运用的优化思想有读写分离,读读并行,读写并行。
- 一致性:通过回滚,以及恢复,和在并发环境下的隔离做到一致性
2.3 事务隔离级别
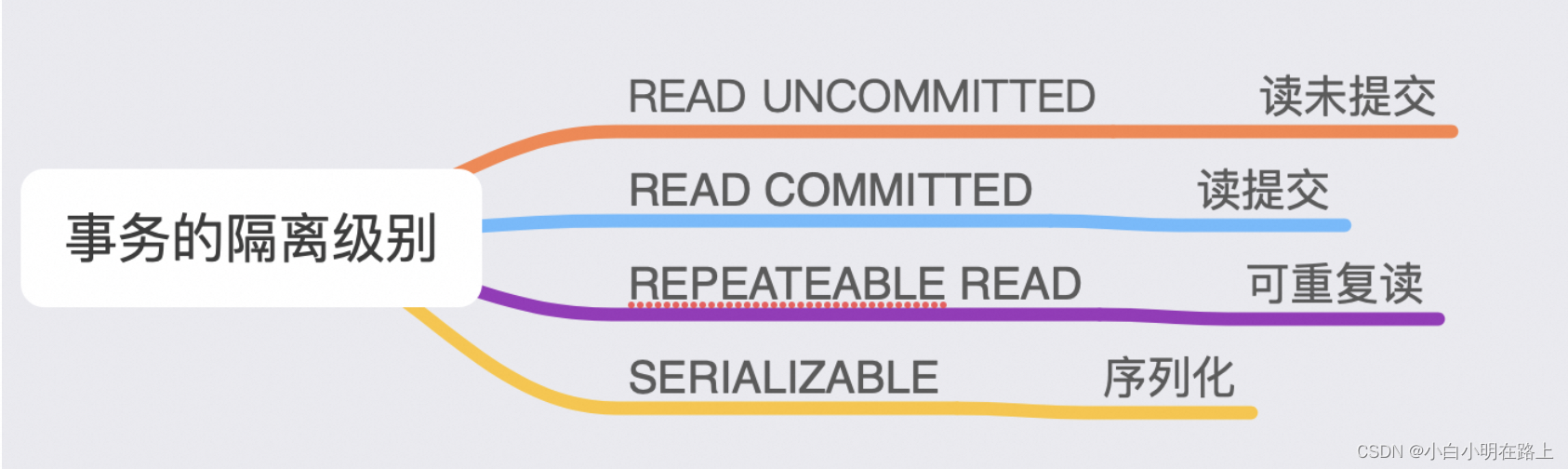
读未提交(Read Uncommitted,RU):在读未提交隔离级别下,一个事务会读到其他事务未提交的数据的,即存在脏读问题。事务 B 都还没 commit 到数据库呢,事务 A 就读到了,感觉都乱套了。实际上,读未提交是隔离级别最低的一种。
读已提交(Read Committed,RC):为了避免脏读,数据库有了比读未提交更高的隔离级别,即读已提交。但是,隔离级别设置为读已提交的时候,还会存在不可重复读的并发问题。
可重复读(Repeatable Read,RR):解决了不可重复读的问题,但没有完全解决存在的幻读问题。
串行化(Serializable):当数据库隔离级别设置为 serializable 的时候,事务 B 对表的写操作,在等事务 A 的读操作。其实,这是隔离级别中最严格的,读写都不允许并发。它保证了最好的安全性,性能却是个问题
2.4 事务问题
脏读:事务 A、B 交替执行,事务 A 被事务 B 干扰到了,因为事务 A 读取到事务 B 未提交的数据。
不可重复读:在事务 A 范围内,两个相同的查询,读取同一条记录,却返回了不同的数据。
幻读:事务 A 查询一个范围的结果集,另一个并发事务 B 往这个范围中 插入 / 删除 了数据,并静悄悄地提交,然后事务 A 再次查询相同的范围,两次读取得到的结果集不一样了
2.5 redo log 和 undo log
redo log 是用来恢复数据的,用于保障已提交事务的持久化特性。
undo log 是用来回滚数据的,用于保障未提交事务的原子性。
2.6 读写锁实现了事务的隔离性
shared lock:共享锁、读锁。
exclusive lock:排他锁,写锁。
2.7 MVCC
MVCC(MultiVersion Concurrency Control),中文叫 多版本并发控制,它是通过读取历史版本的数据,来降低并发事务冲突,从而提高并发性能的一种机制。它的实现依赖于 隐式字段、undo日志、快照读&当前读、Read View。
InnoDB 的 MVCC ,是通过在每行记录的后面保存两个隐藏的列来实现的。这两个列, 一个保存了行的创建时间,一个保存了行的过期时间, 当然存储的并不是实际的时间值,而是系统版本号。
MVCC 在 MySQL 中的实现依赖的是 undo log 与 Read View。undo log 中记录某行数据的多个版本的数据。Read View 用来判断当前版本数据的可见性。
快照读:读取的是记录数据的可见版本(有旧的版本),不加锁,普通的 select 语句都是快照读。
当前读:读取的是记录数据的最新版本,显示加锁的都是当前读。
Read View 就是事务执行快照读时,产生的读视图。事务执行快照读时,会生成数据库系统当前的一个快照,记录当前系统中还有哪些活跃的读写事务,把它们放到一个列表里。Read View主要是用来做可见性判断的,即判断当前事务可见哪个版本的数据 ~
2.8 MySQL 是怎样实现上述四种不同的隔离级别的呢?
MySQL 使用不同的 锁策略 / MVCC 来实现四种不同的隔离级别。RC、RR 的实现原理跟 MVCC 有关,RU 和 Serializable 的实现原理跟锁有关。
读未提交,采取的是读不加锁原理。事务读不加锁,不阻塞其他事务的读和写。事务写阻塞其他事务写,但不阻塞其他事务读;
串行化中,读加共享锁,写加排他锁,读写互斥。如果有未提交的事务正在修改某些行,所有 select 这些行的语句都会阻塞。
RC 跟 RR 隔离级别,最大的区别就是:RC 每次读取数据前都生成一个 ReadView,而 RR 只在第一次读取数据时生成一个 ReadView。
3. 日志
3.1 change buffer
Change Buffer(修改缓冲器)是MySQL InnoDB存储引擎中的一项优化功能,用于最小化磁盘读取和提高写入性能。
当一个数据页在内存中被修改,但又不立即写回磁盘时,这些变更会被保存在Change Buffer中。这种情况经常发生在B树节点的插入、更新或删除操作上。由于不需要立即执行磁盘I/O,Change Buffer可以加速事务的提交速度。
Change Buffer的原理是:
- 在发生插入或更新操作时,InnoDB存储引擎会将变更操作记录在Change Buffer中,同时会把相应的页面标记为“脏页”。
- 当InnoDB需要访问一个页时,它首先会检查Change Buffer,如果发现Buffer中有与该页相关的记录,它会先将变更应用到内存中的页,然后在内存中执行相应的操作。
- 当相关数据页从磁盘加载到内存时,Change Buffer中的记录也会被应用到内存中的页上。
Change Buffer适合于那些写入密集的场景,例如账单、日志等系统,因为写入多读取少的系统中,数据页写入后通常不会立即被查询到,所以Change Buffer的应用效果会比较好。
需要注意的是,Change Buffer对普通索引生效,但对于唯一索引的更新操作无法使用Change Buffer,因为唯一索引需要保证唯一性,因此对唯一索引的更新仍然需要立即应用到内存中,无法通过Change Buffer来进行优化。
总的来说,Change Buffer通过将写操作缓存在内存中,以减少对磁盘的写入,从而提高了写入性能,并且在写入密集型的环境中能够发挥更好的效果
3.2 数据写入流程
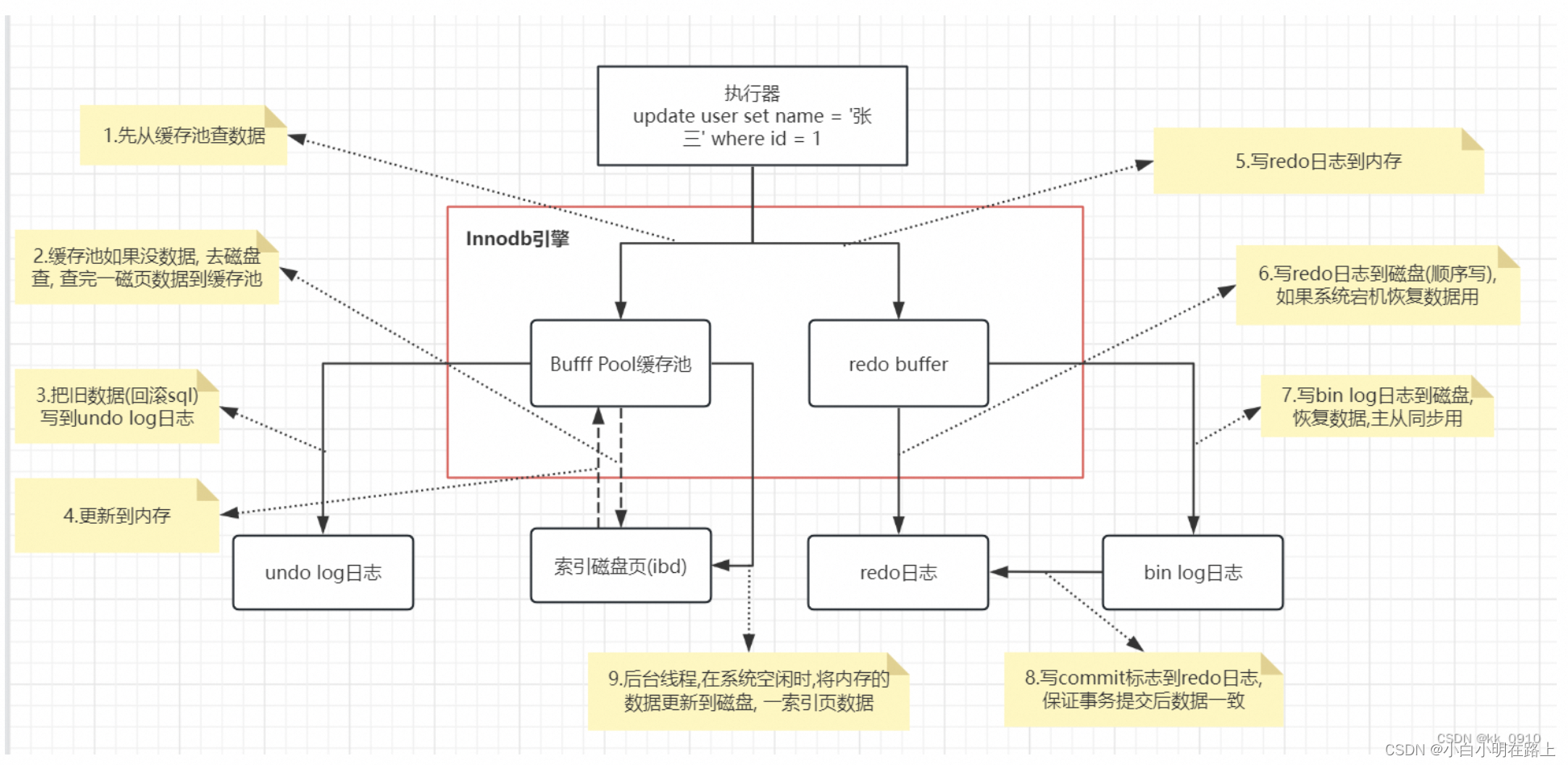
3.3. Innodb相关组件介绍
redolog
redolog日志是Innodb用于保障事务中持久性的基石。
为了提升数据的写入速度,Mysql只是简单的在Page buffer(内存中)修改了数据,并没有进行刷盘操作,在某些情况下,数据会发生丢失的可能。所以为了避免数据丢失,Mysql使用了WAL机制,在事务数据写入内存后,会紧接着写入redo日志,这样在意外宕机的情况下,Mysql仍能根据redo日志恢复出完整数据。
redo默认是先写入log buffer中的,所以会存在redo丢失的可能,Mysql提供了innodb_flush_log_at_trx_commit参数用于控制刷盘时机。
innodb_flush_log_at_trx_commit = 0 :只写log buffer,redo log buffer每隔1S会刷到磁盘上。
innodb_flush_log_at_trx_commit = 1 :每次事务提交前都会添加到redo log日志并刷到磁盘上。
innodb_flush_log_at_trx_commit = 2 :每次事务提交前只会写入redo log日志但不会刷盘,会等待每秒一次的刷盘操作。
刷盘是个昂贵操作,但是为了保障数据不丢失,一般都会设置成1,所以Mysql写入性能并不是很强。
redolog、binlog双写一致性
binlog是在Mysql层面上的日志,而redolog只是Innodb为了持久性而设计的日志,一般情况下,为了做数据同步用,binlog都会是开启状态,Innodb采用了两阶段提交方式来保障redolog和binlog的一致性。
先写redolog日志,生成事务标记xid,并设置状态为prepare状态
写入binlog日志
进行事务提交,更改xid的redolog变成commit状态
假设事务提交失败了,但是binlog写入成功了,Mysql会从binlog日志中获取最后一条xid,并将该xid对应的redolog改为提交状态并用于恢复数据。
Mysql5.7以后默认开启了两阶段提交并且不可关闭,但是这会带来额外的消耗,因为想要保证强一致性的话,redo日志会被刷盘两次(prepare和commit)
undolog
undolog会保留每行数据一段时间内所有事务的操作记录,用于进行事务回滚以及帮助MVCC进行事务隔离。
由于undo链过长会影响性能,所以Mysql会定时的获取当前所有readview中最老的活跃事务id,并使用purge线程将该事务之前的undolog进行回收。
buffer pool
buffer pool是Mysql最核心的一块区域,主要作用就是为了提升Mysql的读写性能而存在的。
Mysql在修改数据时,并不会直接去修改磁盘上的数据(属于随机IO,性能很差),而是先将磁盘上的page加载到buffer pool再进行操作,相当于将磁盘的随机IO转变成了内存的随机IO,提升了大量性能。
buffer pool使用变种LRU算法进行page的维护和淘汰策略,如下图所示。
该算法将buffer pool按照5:3分成了两部分,page第一次被加载时,会先进入old sublist区域的头部。
在old区域中的page会等待再次读取并且停留时间达到一定目标后,才会进入到new sublist区域中。
而new区域中的page也会随时间推移,而降级到old区域中。
当buffer pool空间不足时,会先从old区域的尾部进行淘汰。
change buffer
如果一条update语句是位于普通索引(非唯一索引)上的修改,比方说要修改page500上的某条数据,那么该条修改记录会先记录到change buffer中,而不是产生缺页中断去磁盘上加载新page500。如果在之后的过程中,有新的查询需要加载该page500,当page500加载到buffer pool时,会与change buffer中的相关记录做一次合并操作。这样可以看出明显能节省一次IO过程,有利于写性能的提高。
double write
Mysql是以page为单位从磁盘上获取数据加载到内存或者从内存中写入磁盘的,page的默认大小为16KB,而目前并不是所有的磁盘都能支持16KB的原子性写入的(很多磁盘的块大小是4KB),所以会导致一种情况,Mysql向磁盘中写入一个page时,如果发生意外,磁盘上就会存在一个损坏的page,这将导致Mysql在下次重启过程中,无法恢复该页数据,导致数据丢失。
所以buffer pool中的脏页在写入磁盘前,会先写入double write buffer(会持久化到共享表空间),这样在磁盘上的page发生缺失时,还可以根据double write中的副本页进行恢复。
如果double write持久化时Mysql挂了,那么Mysql会根据脏页前的page + redo log 进行数据恢复。
在innodb中double write是默认开启的,如果不在乎数据丢失或者磁盘可以支持16KB原子写,可以关闭该功能,用于提高Mysql写入性能。
4. 一些题目
4.1 为什么mysql使用B+树,redis使用跳表
核心取决于磁盘数据库和内存数据库的区别,磁盘问题是读取数据速度远小于内存,所以mysql的核心是要减少磁盘io次数,redis不存在这个问题
mysql为什么用B+树
- B+ tree是多叉树结构,每个结点都是一个16k的数据页,能存放较多的索引信息,所以扇出很高。三层左右就可以存储2kw左右的数据。也就是说查询一次数据,如果这些数据页都在磁盘里,那么最多需要查询三次磁盘IO
- 跳表是链表结构,一个结点存放一条数据,如果底层需要存储2kw数据,且每次查询都能达到二分效果,2kw大概需要2的24次方左右,也就是说跳表高度大概在24层左右。最坏情况下,这24层数据会分散在不同的数据页里,也就是说查询一次数据需要24次磁盘IO。
redis zset为什么用跳表
redis是基于内存的数据库,因此不需要考虑磁盘IO,所以索引层数在redis就不再是跳表的劣势了
- B+树在数据写入时,存在拆分和合并数据页的开销,目的是为了保持树的平衡。
- 跳表在数据写入时,只需要通过随机函数生成当前节点的层数即可,然后更新每一层索引,往其中加入一个节点,相比于B+ tree而言,少了旋转平衡带来的开销。
4.2 单表建议2kw数据怎么得出来的
b+树结构:叶子结点放数据,非叶子结点存放页地址
所以一共有多少个页,取决于非叶子结点
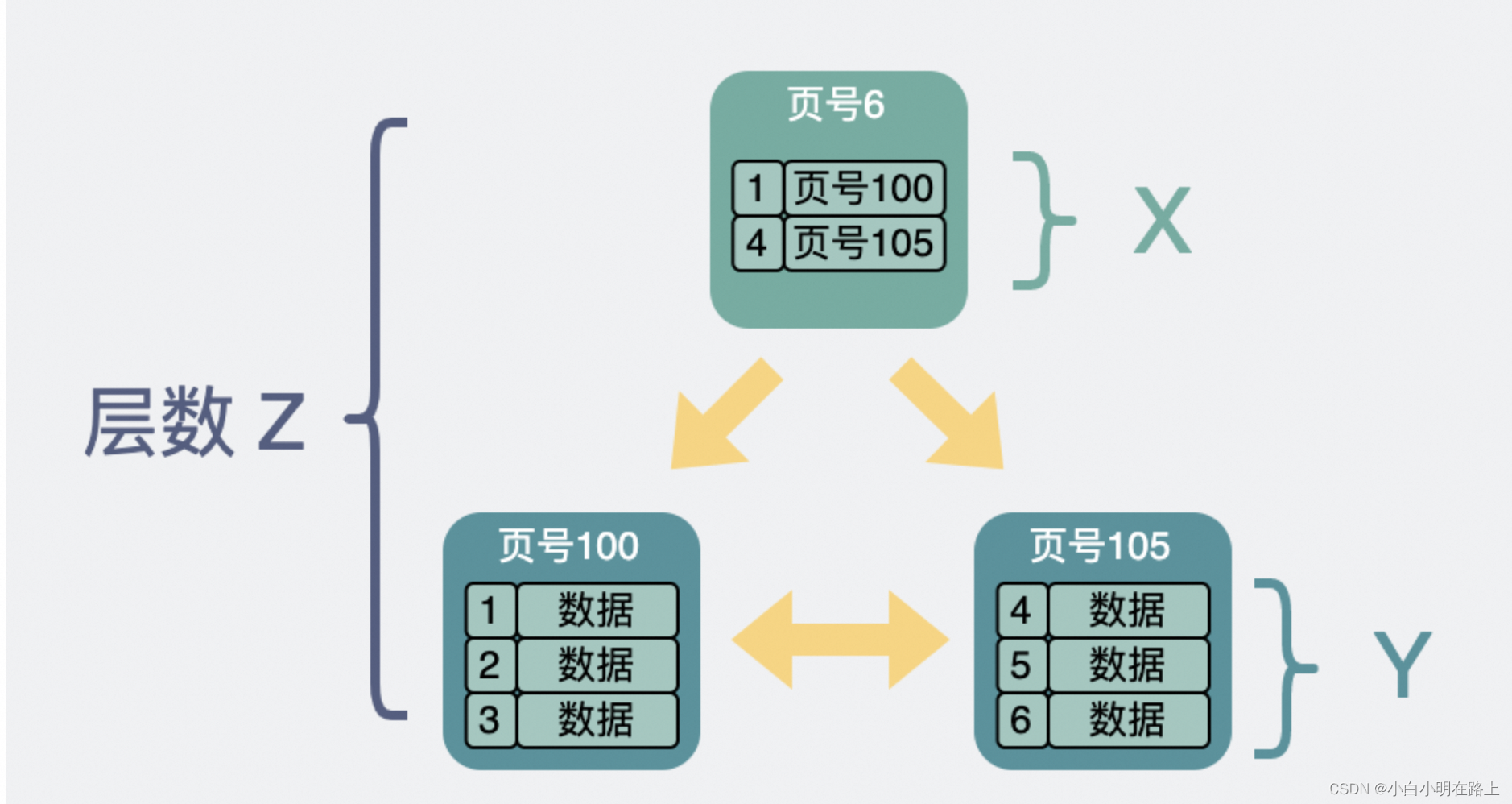
总行数的计算方法
那这棵B+树放的行数据总量等于 (x ^ (z-1)) * y
数据页的结构
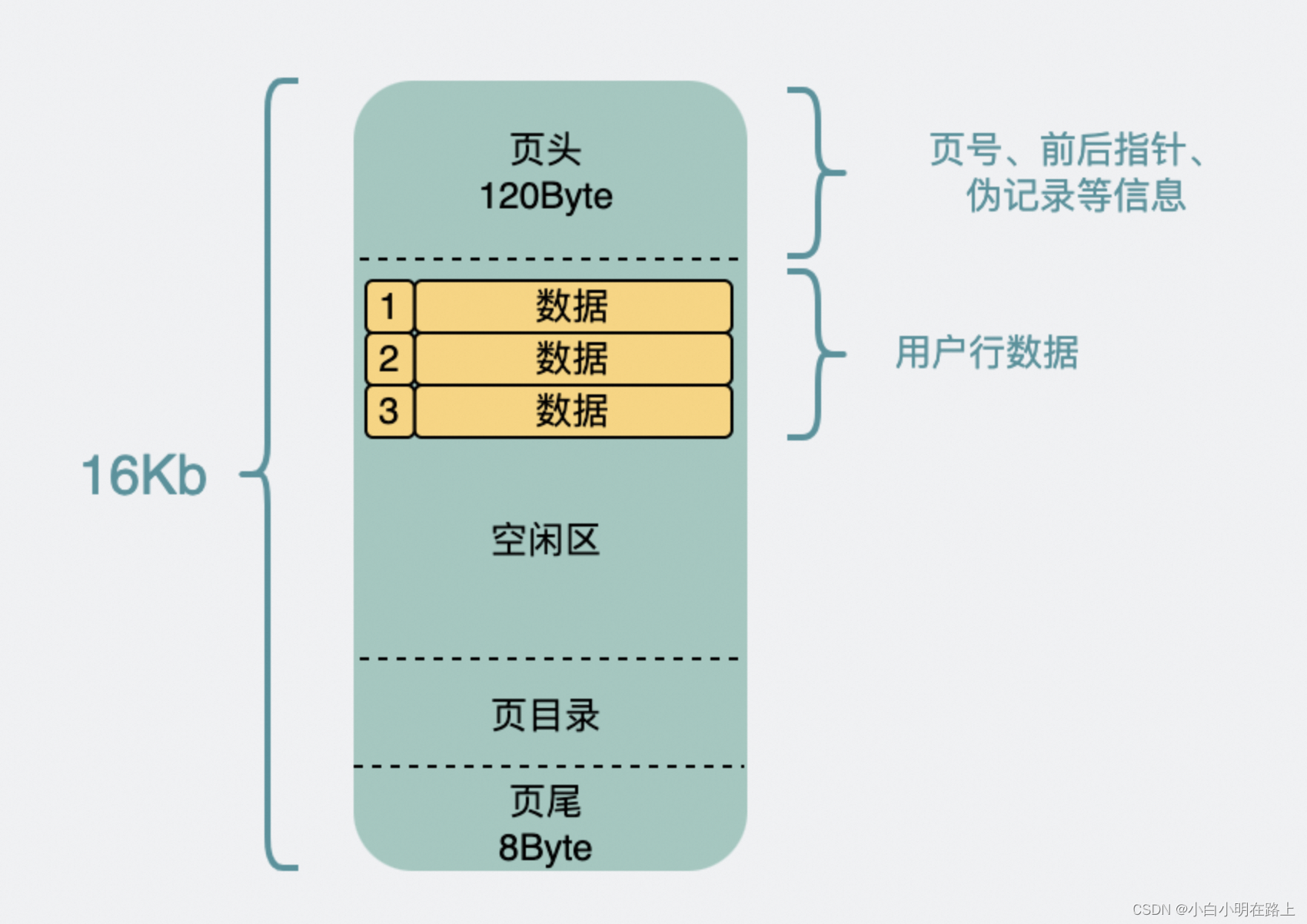
非叶子节点里主要放索引查询相关的数据,放的是主键和指向页号。
主键假设是bigint(8Byte),而页号在源码里叫FIL_PAGE_OFFSET(4Byte),那么非叶子节点里的一条数据是12Byte左右。
整个数据页16k, 页头页尾那部分数据全加起来大概128Byte,加上页目录毛估占1k吧。那剩下的15k除以12Byte,等于1280,也就是可以指向x=1280页
假设一条行数据1kb,所以一页里能放y=15行。
行总数计算
回到 (x ^ (z-1)) * y 这个公式。
已知x=1280,y=15。
假设B+树是两层,那z=2。则是(1280 ^ (2-1)) * 15 ≈ 2w
假设B+树是三层,那z=3。则是(1280 ^ (3-1)) * 15 ≈ 2.5kw















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









