







1 采用抛弃缺失值
抛弃极少量的缺失值的样本对决策树的创建影响不是太大。但是如果属性缺失值较多或是关键属性值缺失,创建的决策树将是不完全的,同时可能给用户造成知识上的大量错误信息,所以抛弃缺失值一般不采用。只有在数据库具有极少量的缺失值同时缺失值不是关键的属性值时,且为了加快创建决策树的速度,才采用抛弃属性缺失值的方式创建决策树。
2 补充缺失值
缺失值较少时按照我们上面的补充规则是可行的。但如果数据库的数据较大,缺失值较多(当然,这样获取的数据库在现实中使用的意义已不大,同时在信息获取方面基本不会出现这样的数据库),这样根据填充后的数据库创建的决策树可能和根据正确值创建的决策树有很大变化。
3 决策树特有的处理缺失值的方法
解决两个问题:
<1> 计算信息增益(或信息增益比或基尼系数等指标)时,遇到缺失值,如何处理?
<2> 每一次求出信息增益(或信息增益比或基尼系数等指标)后,找到最佳分割点后,求最佳分割点时遇到的缺失值如何处理?
例:以ID3算法为例
参考:https://m.imooc.com/article/details?article_id=257743


同理,可求得:
g(D, 根蒂)=0.171;g(D, 敲声)=0.145;g(D, 纹理)=0.424;
g(D, 脐部)=0.289;g(D,触感)=0.006
比较发现,“纹理”在所有属性中的信息增益值最大,因此,“纹理”被选为划分属性,用于对根节点进行划分。划分结果为:“纹理=稍糊”分支:{7,9,13,14,17},“纹理=清晰”分支:{1,2,3,4,5,6,15},“纹理=模糊”分支:{11,12,16}。如下图所示:

将求”纹理”这个最佳分割点时的缺失属性的样本8,9同时放入到分裂的数据集中,此时各个样本的权重不再是1,如图:
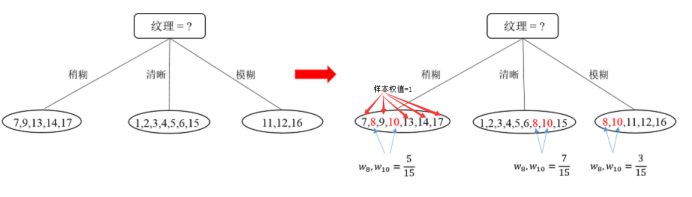
然后对新分出来的三批数据,以同样的方法递归,直到树建成。不同的是,这个时候的样本的权值不都是1,计算时要考虑样本权值。以纹理=稍糊这批数据集为例。

此时色泽的信息增益计算过程如下:

同理,可求得:
g(D, 根蒂)=0.039;g(D, 敲声)=0.381;g(D, 纹理)=None(不做计算);
g(D, 脐部)=0.216;g(D,触感)=0.219
对比能够发现属性“敲声”的星系增益值最大,因此选择“敲声”作为划分属性,划分后的决策树如下图所示:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









