







一 获得规整的数据集
1 原始数据预处理:
去除标点符号 、去停用词、大小写转换等
获得处理后的m条评价记录,reviews=[“is good”, “very happy”, “yes i think so”,…]
2 获取索引集(当然,这个过程也可以用W2V等方法实现,比较好的解决方法是能够考虑到词的频率、顺序等属性):
方法一:网上下载别人训练好适合该场景的领域权威索引集。
方法二:自己制作
<1>得到全部单词words,例如words=[i have an apple you have an orange i love apple]
<2>对words以(key,value)的形式,key为单词,value为该单词在words中出现的次数。
{i:2, have:2, an:2, apple:2, you:2, orange:1, love:1}
3 将文本中所有的评价记录根据索引集转换成数字(此时长短不一)
4 获取最终规整可输入模型的数据集。
<1>确定一个合理的统一的每行的向量维度(即单词个数)Vn
Vn的大小通过数据分析,观察所有记录中各个长度的分布情况,找到一个合理的长度Vn,该长度能覆盖所有记录中大部分的记录。
<2>对于每一条记录,小于Vn个单词的,在前面补0;多于Vn个单词的记录,把多余的部分剔除(多的情况有没有更好的方法),得到最终规整的样本集。
5 获取样本集对应的标签集
二 建立训练集、测试集、验证集(常规操作)
三 建立LSTM网络
把RNN该有的结构搭好,类似传统机器学习应用调包时所有算法结构都已经搭好了,只需输入X,y。深度学习应用的区别就是根据实际需要自己搭相应的框架。
1 设置超参数lstm_size、lstm_layers、batch_size、learning_rate
lstm_size:LSTM细胞隐藏单元数量,稍微设置大点会有不错的效果,常见的值如128, 256, 512等。
lstm_layers:网络中LSTM层的数量,这里从1开始,如果不合适就再增加。
batch_size:在一次训练中训练数据进入网络的数据量。通常情况下,应该设置大一些,如果你能确保内存足够的话。
learning_rate:学习率
2 定义输入

3 添加Embeding层.注意:添加embeding层时只是在构建它的基本框架,本例是等待规整的评价记录这些训练数据输入,是没有实际的数据输入的。

4 建立LSTM层
建立lstm层。这一层中,有 lstm_size 个基本单元
添加dropout
如果一层lsmt不够,多来几层

5 前向传播
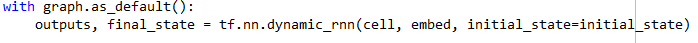
6 定义输出和准确率

7 获取Batch(最小批训练数据),准备训练

四 训练

五 测试(预测结果)

附:github代码 https://github.com/yangbeans/Text_Classification_LSTM















 4057
4057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









