







1.什么是BN
2.为什么BN算法可以解决梯度消失与梯度爆炸的问题
3.Batch Normalization和Group Normalization的比较
4.Batch Normalization在什么时候用比较合适?
一、什么是BN?
Batch Normalization是2015年一篇论文中提出的数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。BN层和卷积层,池化层一样都是一个网络层。
论文地址:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
首先我们根据论文来介绍一下BN层的有点:
1)加快训练速度,这样我们就可以使用较大的学习率来训练网络。
2)提高网络的泛化能力。
3)BN层本质上是一个归一化网络层,可以替代局部响应归一化层(LRN层)。
4)可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)论文中提到可以提高1%的精度。
实现原理

从论文中可知道BN层的计算流程是:
1)计算样本均值
2)计算样本方差
3)样本数据标准化的处理
4)训练参数γ,β
5)输出y通过γ与β的线性变换得到新的值
在正向传播的时候,通过可学习的γ与β参数求出新的分布值,在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值。

在这里为什么要归一化呢?对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。也就是说,如果训练数据和测试数据分布不同的话,网络的泛化能力也会降低。
大家知道,网络在训练的过程中,除了输入层的数据外(因为一般输入层的数据会人为的对每个样本进行归一化),后边各层的输入数据的分布一直在发生变化的。对于中间各层在训练过程中,数据分布的改变称之为internal covariate shift。BN算法就是为了解决在训练过程中,中间层数据分布发生改变的情况下的数据归一化的。
BN的精髓在于归一之后,使用γ,β作为还原参数,在一定程度上保留原数据的分布。
二、为什么BN算法可以解决梯度消失与梯度爆炸的问题
关于梯度消失,以sigmoid函数为例,sigmoid函数使得输出在[0,1]之间。
事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图:
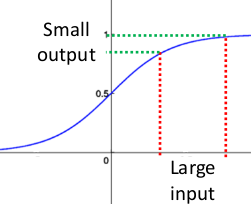
如果输入很大,其对应的斜率就很小,我们知道,其斜率(梯度)在反向传播中是权值学习速率。所以就会出现如下的问题:

在深度网络中,如果网络的激活输出很大,其梯度就很小,学习速率就很慢。假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就大,学习速率就快。
这会造成的影响是在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是,后面几层基本可以表示整个网络,失去了深度的意义。
关于梯度爆炸,根据链式求导法,第一层偏移量的梯度=激活层斜率1 x 权值1 x 激活层斜率2 x…激活层斜率(n-1) x 权值(n-1) x 激活层斜率n
假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。当大过sigmod造成的减小,这样越往前误差就越来越大,梯度爆炸了!
三、Batch Normalization和Group Normalization的比较
Group Normalization(GN)是针对Batch Normalization(BN)在batch size较小时错误率较高而提出的改进算法,因为BN层的计算结果依赖当前batch的数据,当batch size较小时(比如2、4这样),该batch数据的均值和方差的代表性较差,因此对最后的结果影响也较大。如图Figure1所示,随着batch size越来越小,BN层所计算的统计信息的可靠性越来越差,这样就容易导致最后错误率的上升;而在batch size较大时则没有明显的差别。虽然在分类算法中一般的GPU显存都能cover住较大的batch设置,但是在目标检测、分割以及视频相关的算法中,由于输入图像较大、维度多样以及算法本身原因等,batch size一般都设置比较小,所以GN对于这种类型算法的改进应该比较明显。

原文链接:GN算法
Batch Normalization:可以让各种网络并行训练。但是维度进行归一化会带来一些问题-----批量统计估算不准确导致批量变小时,BN 的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN。Group Normalization:GN将通道分组,并且每组内计算归一化的均值和方差。GN的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。
四、Batch Normalization在什么时候用比较合适?
在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
参考链接:
BN算法原理与使用
BN算法
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









