






 本文详细介绍了扩散模型,尤其是DenoisingDiffusionProbabilisticModels(DDPM),其基于逐步去噪过程,构建了编码器-解码器结构。作者通过生动比喻解释了模型如何通过增量更新控制方向,展示了模型的构建块、参数处理和训练流程。
本文详细介绍了扩散模型,尤其是DenoisingDiffusionProbabilisticModels(DDPM),其基于逐步去噪过程,构建了编码器-解码器结构。作者通过生动比喻解释了模型如何通过增量更新控制方向,展示了模型的构建块、参数处理和训练流程。
摘要
近年来,生成工具的惊人增长为“文本到图像”生成和“文本到视频”生成提供了许多令人兴奋的应用。这些生成工具背后的基本原理是扩散的概念,这是一种特殊的采样机制,它克服了以前方法中被认为困难的一些缺点。本教程的目的是讨论扩散模型的基本思想。本教程的目标读者包括对研究扩散模型或应用这些模型来解决其他问题感兴趣的本科生和研究生。
2. Denoising Diffusion Probabilistic Model(DDPM)
在本节中,我们将讨论Ho等人[4]的 DDPM。如果你对网上成千上万的教程感到困惑,请放心, DDPM 并不那么复杂。你所需要了解的是以下总结:
扩散模型是 incremental 逐步的更新,其中整体的组装为我们提供了编码器-解码器结构。从一种状态到另一种状态的转换由去噪器实现。
为什么 incrementa ?这就像改变一艘巨轮的方向。你需要慢慢地把船转向你想要的方向,否则你会失去控制。同样的原则适用于你的生活,你的公司人力资源,你的大学管理,你的配偶,你的孩子,以及你生活中的任何事情。“ Bend one inch at a time!” (图片来源:塞尔吉奥·戈马,他在2023年电子影像展上发表了这番评论。)
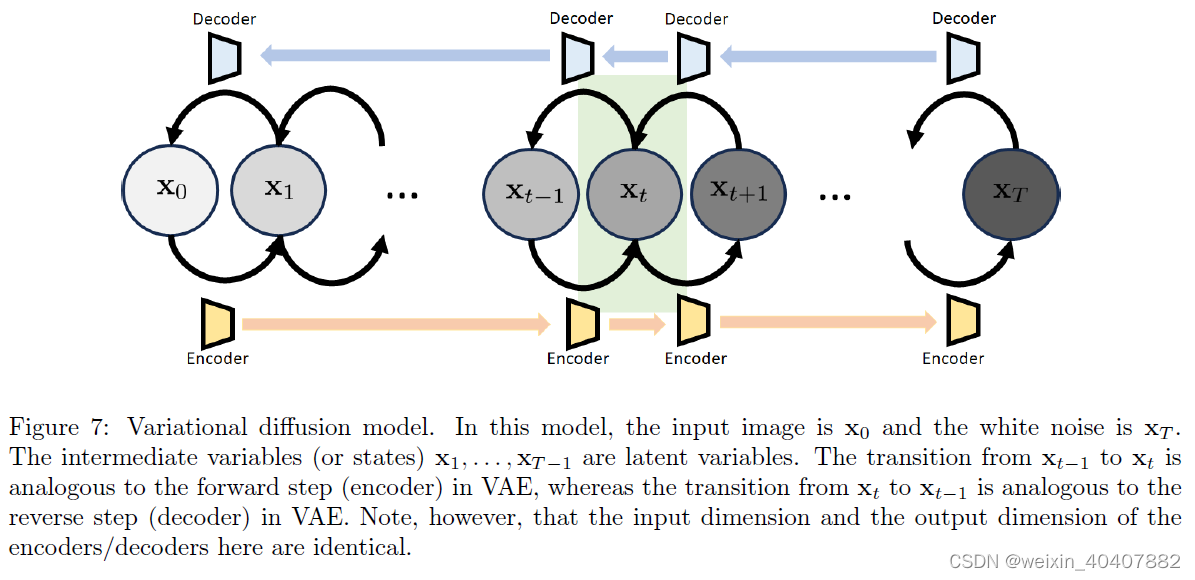
扩散模型的结构如下所示。称为 variational diffusion model 变分扩散模型[5]。变分扩散模型有一系列状态 x0, x1,… , xT:
- x0:为原始图像,与 VAE 中的 x 相同。
- xT:是潜在变量,与 VAE 中的 z 相同。因为我们都很懒,所以我们想要
- x1,…, xT−1:它们是中间态。它们也是潜在变量,但它们不是 white Gaussian 白高斯分布。
变分扩散模型的结构如 图7 所示。正向和反向路径类似于单步变分自编码器的路径。不同之处在于编码器和解码器具有相同的输入输出尺寸。所有正向构建块的组装将为我们提供编码器,所有反向构建块的组装将为我们提供解码器。
2.1 Building Blocks
Transition Block 过渡块:第 t 个过渡块由 xt−1、xt 和 xt+1 三种状态组成。有两种可能的路径可以到达状态xt,如 图8 所示。
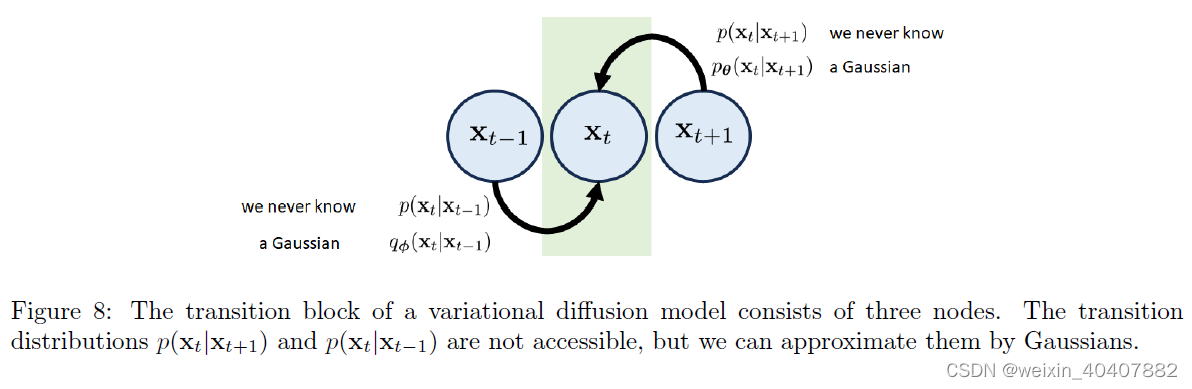
- 从xt - 1到xt的正向跃迁。相关的过渡分布为p(xt|xt−1)。简单地说,如果你告诉我们xt−1,我们可以根据p(xt|xt−1)告诉你xt。然而,就像VAE一样,过渡分布p(xt|xt−1)永远是不可访问的。但这没关系。像我们这样懒惰的人只会用高斯qϕ(xt|xt−1)来近似它。我们稍后将讨论确切的形式qφ,但它只是一些高斯。
- 反向转换从xt+1到xt。同样,我们不知道p(xt+1|xt)但没关系。我们只是使用另一个高斯pθ(xt+1|xt)来近似真实的分布,但它的均值需要通过神经网络来估计。
2.2 The magical scalars and
2.3 Distribution
2.4 Evidence Lower Bound
2.5 Rewrite the Consistency Term
2.6 Derivation of
2.7 Training and Inference
2.8 Derivation based on Noise Vector
2.9 Inversion by Direct Denosing (InDI)















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









