







比较了MDR、FIM、IG、BEAM、SH、MECPM、LRIT、LR 这8种方法,在本次实验中,表现最好的是MECPM方法。
全面搜索:IG、LRIT、LR
随机搜索:BEAM、MDR
确定性启发式搜索:SH、FIM、MECPM
MDR(多因素降维)
如果cases数目和controls数目的比率超过一定的范围,则标记该基因型为“high-risk”。将high-risk基因型分为一组,low-risk基因型分为另一组。如果一个对象有high-risk的基因型则预测为一个case(患病),否则预测是一个control(正常)。利用10倍交叉验证来计算预测错误率,并以此来衡量SNP位点和疾病之间的关系。
FIM(完全关联模型)
IG(信息获取)
C表示疾病状态随机变量,那么{A,B}之间的信息获取就可以表示为
IG(A,B,C) = I(A; B|C) - I(A; B)
互信息I(A; B)为一个非负数,在给定随机变量B的情况下,用来衡量随机变量A的不确定下降。在给定表型随机变量C的情况下,互信息I(A; B|C)用来衡量A和B之间的依赖关系。IG的大小表示了在给定C的情况下A和B之间的依赖关系,换句话说,就是A,B位点之间的联系强度。
BEAM(贝叶斯异位显性关联绘图)
假设L个SNP位点中有N个基因型样本(N个caseN个control),BEAM 将L个SNP分成3组:和疾病没关联的、只有一个主影响因素的、有相互作用因素的。
用D来表示在所有case中第 j 个SNP位点的基因型向量
同样,D也可以分为三组
U来表示在所有control中第 j 个SNP位点的基因型向量
I分成三组,分别表示在第 j 个SNP位点中和疾病没关联的、只有一个主影响因素的、有相互作用因素的。
P(I|D,U) ∝ P(D1|I) · P(D2|I) · P(D0,U|I) · P(I)
SH(SNP 收割机)
该方法主要适用于边缘效应较小的关联作用。
有三步:
1、去除SNP位点的显著主要影响因素
2、
MECPM(最大熵条件概率模型)
根据最大熵准则建立后验表型,再以与关联作用一比一的比例编码约束到模型中,灵活的允许候选的关联作用中存在显性或隐性编码,通过贪婪关联增长搜索策略计算关联搜索候选值,最高不过5次,BIC准则作为模型选择策略。
LR(逻辑回归)
逻辑回归作为一般线性模型用于二项式回归。使用x(i)代表SNP第i个对象的基因型。x(i) = 0 表示纯合主等位基因,x(i) = 1 表示杂合子基因,x(i) = 2 表示纯合次等位基因。π (x(i))表示疾病风险。逻辑回归可以表示为:
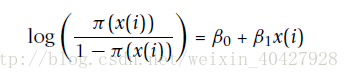
其中的B1和B2代表回归系数,通过最大似然估计计算得到。通过似然比测试,逻辑回归可以计算每个SNP节点的统计学意义。
LRIT(逻辑回归和交互项)
让xm(i)和xn(i)分别代表第m个SNP节点和第n个SNP即诶但的第i个对象的基因型。x(i)可以等为0,1,2,分别代表纯合主等位基因、杂合子基因、纯合次等位基因。π (xm(i), xn(i))代表疾病风险。
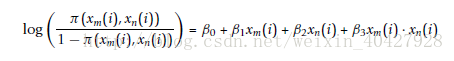
通过最大似然估计得到回归系数。















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









