







 文章探讨了计算卸载的优化问题,证明其为NP-hard问题,并提出基于深度强化学习(DRL)和联邦学习(FL)的解决方案。通过FL在物联网设备上分布式训练DRL代理,以降低通信成本和保护隐私。算法在通信传输、动态环境适应性和长期效益方面表现出优势。实验表明,与集中式训练相比,该方法在效率和性能上有竞争力,但也可能导致更高的能量消耗。
文章探讨了计算卸载的优化问题,证明其为NP-hard问题,并提出基于深度强化学习(DRL)和联邦学习(FL)的解决方案。通过FL在物联网设备上分布式训练DRL代理,以降低通信成本和保护隐私。算法在通信传输、动态环境适应性和长期效益方面表现出优势。实验表明,与集中式训练相比,该方法在效率和性能上有竞争力,但也可能导致更高的能量消耗。
1、文章概述
1.1、文章信息
CCF-B ACM Transactions on Sensor Networks
1.2、文章介绍
计算卸载决策涉及联合和复杂的资源管理,所以使用部署在物联网设备上的多个深度强化学习代理来指导自己的决策。此外,使用联邦学习以分布式方式训练DRL的agent,旨在使基于DRL的决策实际可行,并进一步降低物联网设备和边缘节点之间的传输成本。文章作者研究了计算卸载优化问题,证明了该问题是一个np-hard问题,然后基于DRL和FL提出了一个卸载算法。
这种优化算法具备以下优势:有利于通信传输、对动态环境的适应性、不仅在时间段内优化系统而且会考虑长期效益。
作者使用联邦学习(FL)来进行DRL代理的训练过程,以共同分配通信和计算资源。具体而言,主要贡献有三个方面:
- 研究了计算卸载问题,证明其是np-hard问题
- 设计了计算卸载和能量分配决策算法;该算法基于联邦学习进行训练,使得每个物联网设备收集的数据在本地分析处理实现了隐私保护
- 进行了算法评估,证明与集中式训练方法相比具有有效性
问题:与集中式训练方法相比是否有更好的速度?
2、背景
2.1、深度强化学习
由于强化学习(RL)技术通常应用于小数据空间,因此使用RL处理高维数据是困难的。然而,深度强化学习(DRL)通过将深度学习的高维输入与RL相结合解决了这个问题。
2.2、联邦学习
由google提出的联邦学习,它允许多个终端设备在本地数据上进行训练,然后只需要将更新上传到云。
过程:
1)终端设备从云中下载共享模型,然后根据本地数据训练模型
2)通过加密传输将更新传输到云中。
3)云根据来自多个终端设备的更新来集成共享模型。
由于用户数据在整个过程中始终存储在终端设备本地,因此可以避免大量数据传输到云端,从而减轻数据传输压力,保护数据隐私。
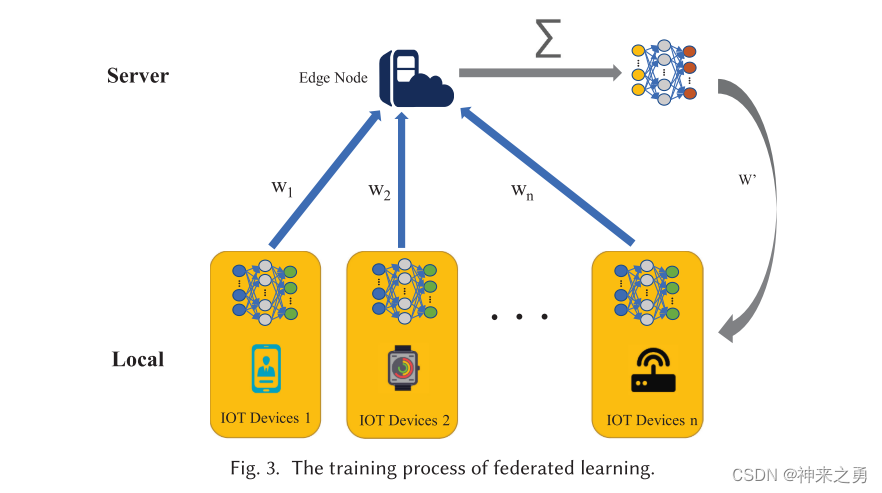
但在实际应用中,仍然存在一些问题。一方面,样本数据将以极不均匀的方式分布在大量终端设备中。另一方面,终端设备的传输速度较慢,特别是数据上传速度会限制整体性能。
为了解决这些问题,谷歌开发了一种算法联邦平均,以减少训练深度神经网络时的网络要求,并通过使用随机旋转和量化来压缩更新,以减少传输的数据量。此外,设计了一种联邦优化算法来优化高维稀疏凸模型。
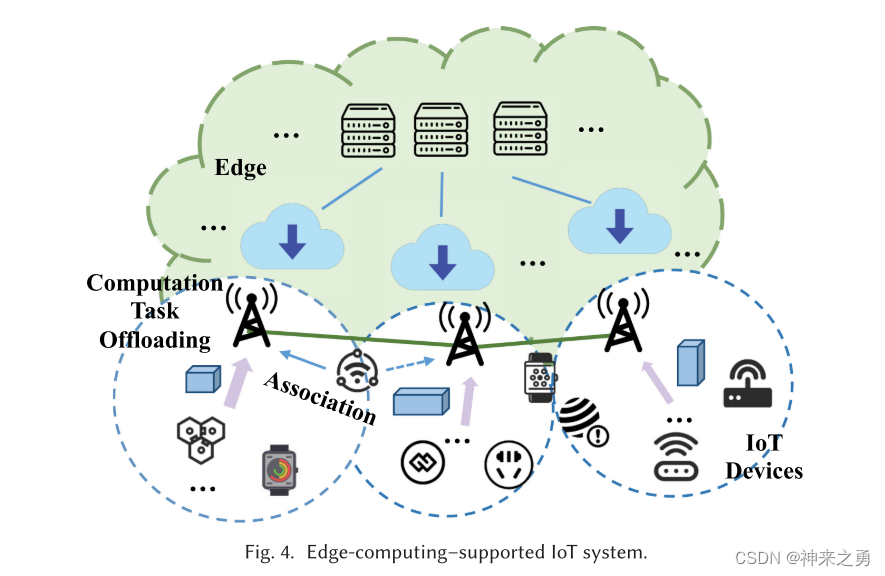
2.3、边缘计算
略
3、系统模型
3.1、概述
IOT设备生成的计算任务被建模为
![]()
μ代表卸载任务所需的传输数据大小
v代表处理任务所需的CPU周期数
3.2、系统模型描述
3.2.1、系统模型体系结构
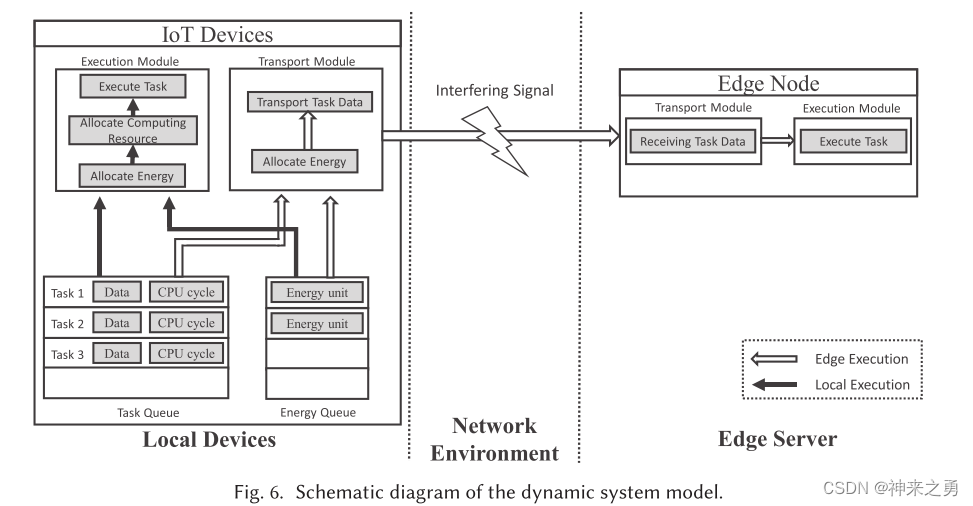
IOT设备需要在epoch i 中做出一个动作集合
![]()
其中C代表卸载决策,具体由0、1、2……N(0代表本地执行,1-N代表在编号为n的EN上执行)
e代表分配的能量单位数量,其影响CPU频率和IOT设备的数据传输速率
3.2.2、本地执行
本地执行的时间约束:
![]()
后者是执行一个任务的速率
本地执行的时间消耗如下:

3.2.3、EN上执行
- 另Si代表epoch i 开始的IOT和EN之间的连接状态

- 改变EN延迟表示为σ
- 无线信道传输速率:
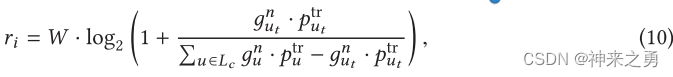
其中,P表示IOT设备u和的传输速率
- 数据传输的时间消耗:
![]()
另外,作者根据其他论文发现保持传输速率恒定可以实现最小传输时间,所以最小传输时间求解为:
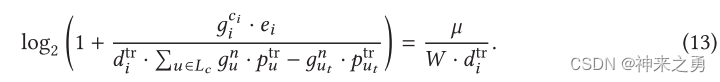
- 任务在EN上的执行延迟:
![]()
- 为避免实际操作中EN资源的额外使用,设置的额外成本
![]()
3.2.4、更新系统模型参数
任务执行延迟可以表示如下:
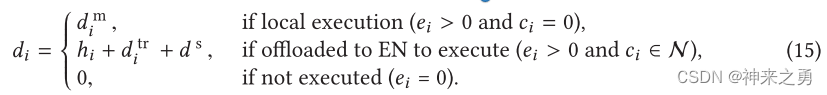
- 考虑并非所有任务生成后都能被立即执行,因此使用如下来表示在epoch i 下的排队延迟:
![]()
4、联邦学习协调下的策略训练
4.1、问题建模
使用Xi代表epoch i中的IoT设备的网络环境,IoT设备在epoch的初始时段做出卸载决策并决定分配的能量单元数量。
策略定义为Φ,长期效用定义为:
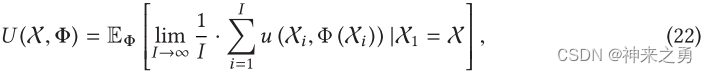
u(.)代表在epoch i中的短期效用,该优化策略可以根据目标进行个性化。例如,如果低延迟是系统中最重要的指标,则可以调整任务执行延迟di和任务排队延迟Pi的权重以改变整个效用中的延迟比例。
4.2、复杂性分析
略
4.3、在边缘计算中使用联邦学习的原因
作者使用DDQN来解决计算卸载中的最大化长期效用问题。但尽管DDQN可以进行高效决策,但会消耗很多计算资源,所以如何训练需要考虑:
- 如果agent在EN上训练存在问题:
- IoT设备与EN之间传输数据,增加无线信道传输压力
- 传输数据不利于隐私保护
- 就算隐私信息可以通过某种方式去除,但会破坏数据完整性,影响训练效果
- 如果在本地单独训练存在问题
- 训练每个DRL 的 agent花费时间太长
- 每个Agent单独训练耗费能量更多
基于以上原因,作者采用分布式方式训练DRL
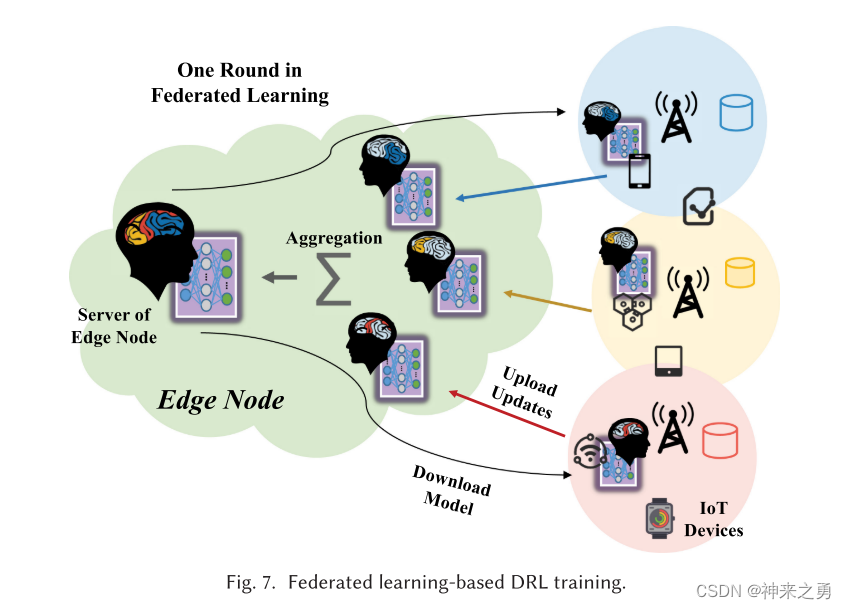
4.4、基于联邦学习的计算卸载DRL训练
Federated Learning-Based DRL Training about Computation Offloading

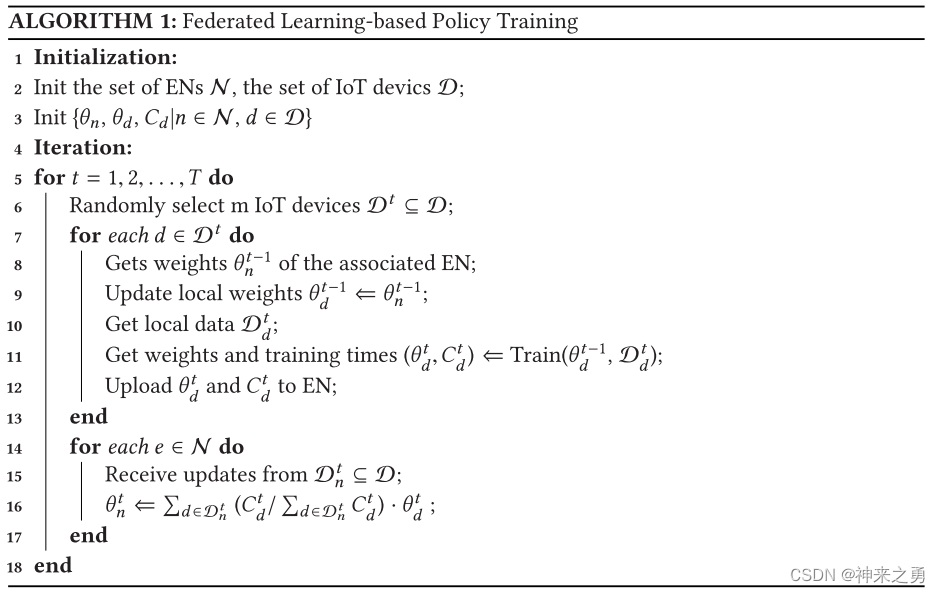
步骤简述:
初始化ENs集合N,IoT设备集合D
随机选取m个IoT设备执行迭代:
对于设备d执行迭代:
从关联EN获取DRL代理权重并赋给自身
获取本地数据并利用其训练agent
上传更新参数到EN
对于EN执行迭代:
接收更新参数进行聚合
4.5、联邦学习策略理论分析(略)
5、性能评价
5.1、实验设置

5.2、探索概率分析
经过分析,作者进行了百次实验采集静校正量。
5.3、任务生成概率分析
任务生成概率作为一个设置参数被用来做比较,以评判算法在高负载情况下的表现,实验数据表明在任务生成概率很高(0.9)时候算法仍然具有很高的效用值(utility value)
5.4、能量生成概率分析
原因:IoT的部署条件差异会导致不同的能量生成概率
通过实验表明,能量生成概率越高,有越多的任务被分配到EN上执行,也就是说EN会消耗更多的能量,但会获得更高的任务处理能力。
5.5、IoT设备数量分析
原因:接入的IoT数量难以确定,所以需要做实验对比不同IoT设备下的实验数据
结论:
- 不同数量IoT设备的早期都呈现上升趋势,后期都趋于稳定
- 同时也有不同点:
- IoT设备较少时,早期效用增长相对缓慢
- 所有的效用在后期都会稳定在同一水平,但不同数量的IoT设备会对效用的标准差产生影响,数量越少标准差越大、性能趋于越稳定
- 早期IoT设备越多,性能越好;但在训练收敛之后,物联网设备越多,性能就越差。原因见论文
物联网设备越多,训练时的收敛速度越快,即早期性能越好。但经过训练聚合后,不同数量的IoT设备的性能趋于同一水平。
5.6、能量消耗分析
基于FL的DRL训练和集中式DRL训练的能耗都高于贪婪策略。原因可能是使用更多的能量减少任务丢弃的数量和任务执行延迟。
提出的算法可能导致更高的能量消耗,这可能是由于用于本地执行或数据传输的更高功率。在这种情况下,尽管能量消耗可能处于高水平,但是在时间延迟、任务丢弃的数量等方面有所改善。
5.7、系统模型中关键指标比较
5.7.1、任务执行延迟
Def:任务从离开任务队列到完成的时间,包含建立连接时间+传输任务数据时间+执行任务时间
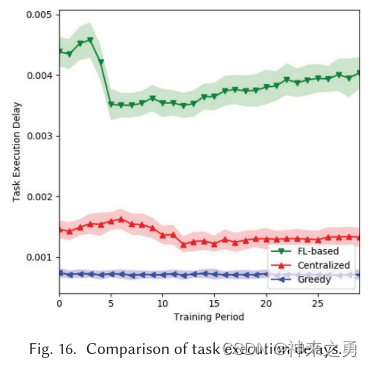
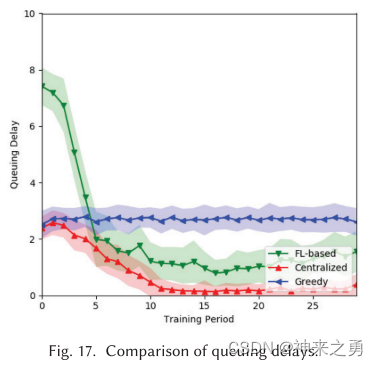
5.7.2、排队延迟
Def:任务放入任务队列到任务去除所花费的时间
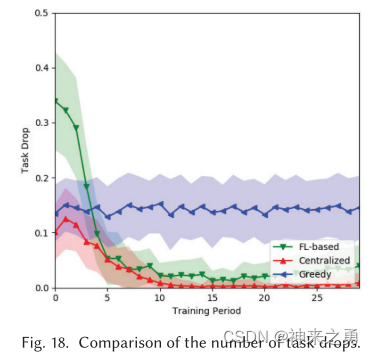
5.7.3、任务丢弃次数
Def:队列中新生成的任务数量达到上限时丢失的任务数量
5.7.4、卸载成本
Def:使用EN所需成本
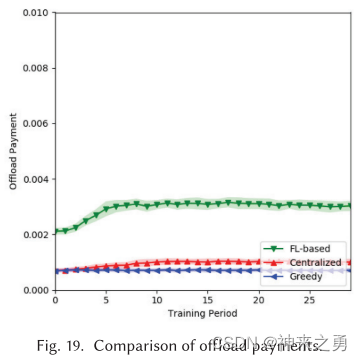
5.8、计算卸载性能分析
略
6、结论
有待解决:
在未来,我们将深入研究是否有关于DRL的模型压缩技术,以及如何以细粒度的方式调度基于FL的DRL训练。


















 8209
8209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











