






多智能体深度强化学习在移动边缘计算的联合多通道访问和任务卸载中的应用
主要贡献
- 我们首次考虑了 IIoT 中 MEC 协作环境中的联合多通道访问和任务卸载。
- 通过多代理强化学习算法对 MTA 的协作资源分配问题进行建模。
- 提出的算法能够处理大型 MEC 系统,它可以从历史观察中渐进地找到最优策略,而不需要系统动力学的优先级。
- 我们选择一个可以使其他MTA的信道增益算术平均值最大的MTA来存储全局经验重放缓冲区,减少相互通信的开销。
与相关工作比较的贡献
Although there have been some excellent works on multichannel access and task offloading in MEC, but none of them join the two issues in multiagent environment in which the cooperation between devices needs to be considered.
In this article, we first apply a multiagent reinforcement learning scheme to design multichannel access and offloading control in MEC to make MTAs learn to cooperate.
As far as we know, our proposed method is the first study and implementation of MARL in the field of IIoT.
三、系统模型(only 2 pages)
分为网络模型,通信模型,计算模型三个部分进行叙述。
3.1 网络模型
作为一种新型的网络范式,SDN允许直接的可编程的网络控制。
SDN通过分离控制层和数据层使基础设施对用户透明。 SDN 允许支持将计算和存储功能引入边缘网络设备所需的控制功能,从而使云服务更接近最终用户。由于网络控制器都是软件定义的,便于设计新的网络功能和软件接口。
如图 1 所示,在自上而下的视图中,我们提出的网络架构由四层组成:1)应用层; 2)控制层; 3)数据层; 4) ED 层(也就是edge层)。
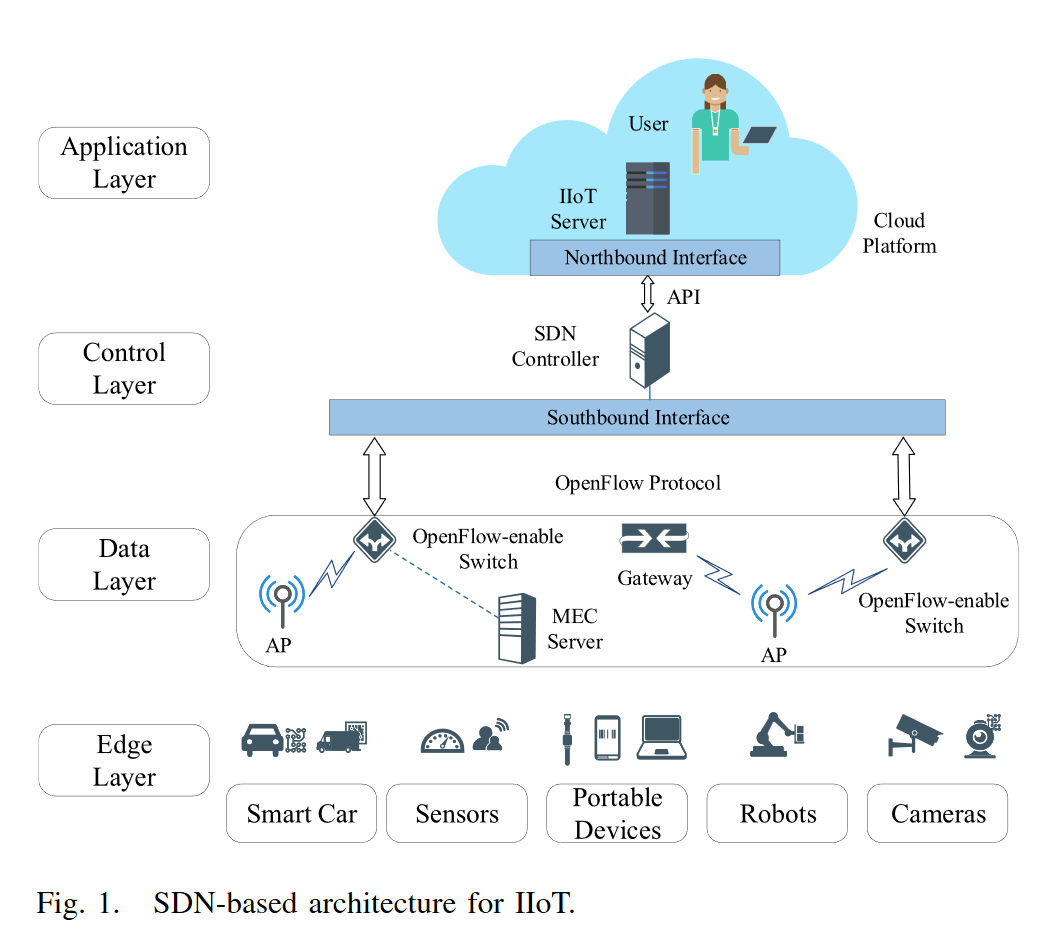
- Application Layer: The application layer has a series of cloud service applications consisting of a bundle of application systems. The goal of the network design is to implement and execute these Web applications.
- Control Layer: In this layer, the SDN controller is responsible for the centralized management of data layer devices and edge computing servers. The controller receives requests from the application layer through the northbound API. These advanced commands are compiled by the controller and converted into low-level OpenFlow messages which is a network communication protocol dedicated to SDN for forwarding to the switch and implementing functionality there. Finally, the SDN controller allocates and adjusts spectrum resources in the network based on different functional or network requirements (e.g., resource allocation and task calculation). 也就是说,application 层通过控制层来控制下面得数据层和边缘计算设备。
- Data Layer: The data transmission layer includes switches, wireless access points, and gateways. All nodes can be controlled by receiving OpenFlow commands from the control layer through the southbound interface, eg. the computation decisions in our proposed task offloading algorithm.
注意,数据传输层包含了交换机,无线访问节点和网关。 - Edge Device Layer: EDs consist of a variety of basic equipments, including smart car, sensors portable devices, robots, cameras, etc. Each device is considered an agent, and we consider a set of MTA, which is denoted as N ={1, 2,…,N}.
3.2 通信模型
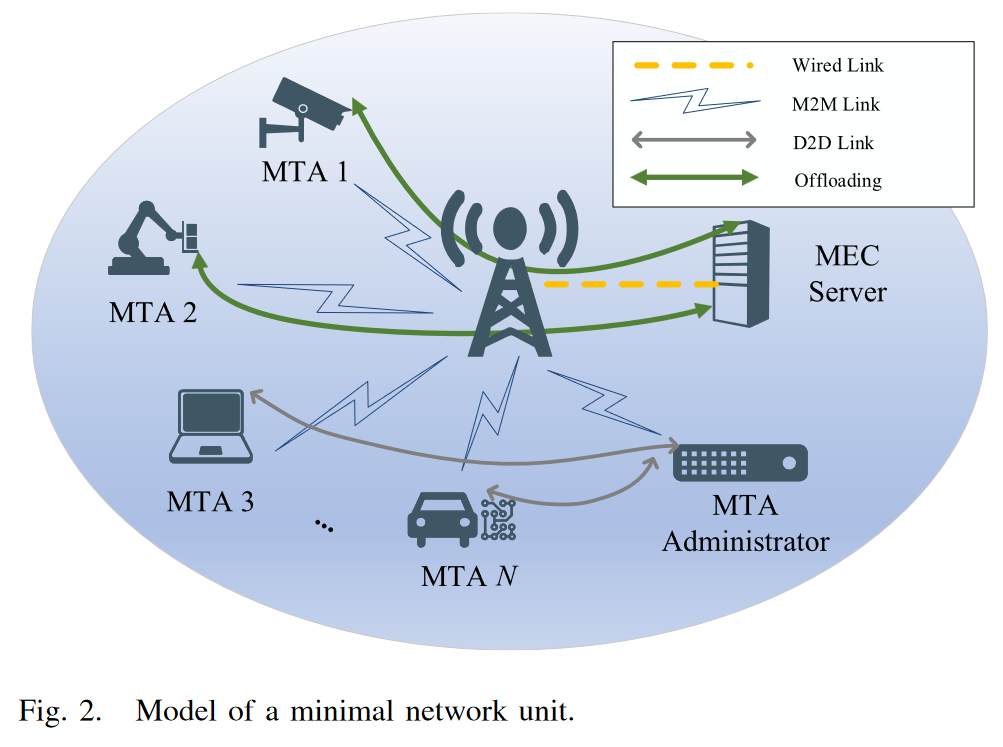
为了更好地利用频谱资源,节省带宽,避免信道拥塞,我们考虑D2D通信。作为2LTE通信技术的补充,D2D通信可以在不经过基站(BS)的情况下实现两个设备之间短距离的直接链接,从而降低传输功率和重复利用频谱。我们考虑根据渠道情况选择 MTA 管理员,记为 aadmin。其余的 MTA 可以直接通过 D2D 通信从 MTA 管理员上传或下载历史信息(观察和行动)。
选择aadmin的方法使用[40]中提出的“A-means”方案,它可以最大化对其他MTA的信道增益的算术平均值。
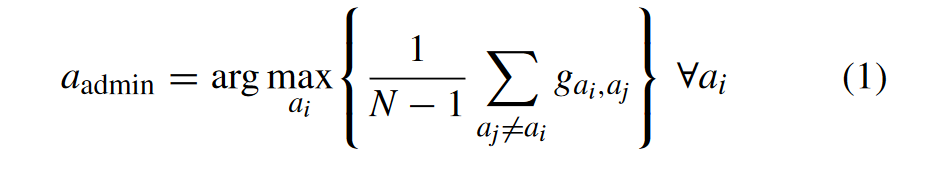
其中 gai,aj 表示 D2D 通信中从 MTAi 到 MTAj 的信道增益
作为说明,图 2 显示了最小网络单元的细节。在最小网络中,有 N 个 MTA 和一个 MEC Server。 MTA 通过 D2D 链接将其经验回放缓冲区 D i l D_i^l Dil (本地观察和操作)上传到 a a d m i n a_{admin} aadmin。 MTA 还可以从 a a d m i n a_{admin} aadmin 下载 全局经验回放缓冲区 D 以训练它的网络。
MTA更新其策略后,根据当前策略选择在本地计算任务或通过M2M链路将任务卸载到MEC服务器,并处于观察状态。最小网络的频谱被划分为K个通道,记为集合K = {1, 2, …, K}。MTA将在每个时隙决定是否将任务卸载到MEC服务器并选择用于无线通信的信道。每个信道的带宽表示为
B
a
i
,
k
B_{{a_i},k}
Bai,k。当MTAi选择将计算卸载到MEC服务器并接入通道k时,上行速率表示为:
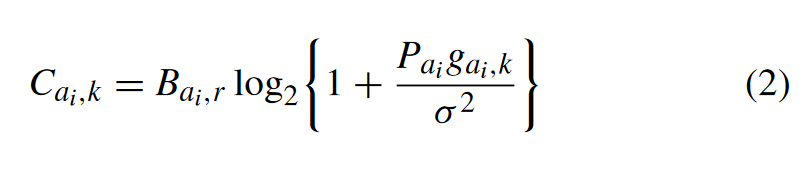
where
g
a
i
,
k
g_{{a_i},k}
gai,k is the channel gain of MTAi to channel k and obeys a Gaussian distribution with zero mean and unit variance
σ
2
σ^2
σ2 which is the system noise power.
Each channel has two states, which can be expressed as
s
k
(
t
)
∈
0
,
1
s_k(t) ∈{0, 1}
sk(t)∈0,1, which means {free, busy}, respectively. When the channel is transmitting a task, the channel will be occupied and the status will change to be busy. In addtion, the connection establishment time is relatively short, and we only consider the transmission time.
3.3 计算模型
在本文的设定中,计算任务是原子的并且不可以被进一步分割。
3.3.1 本地计算
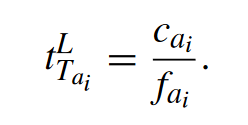
分子是计算任务需要的时钟周期数,分母是计算能力。
3.3.2 卸载计算

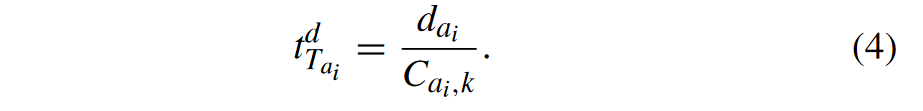
其实就是数据传输量除以数据传输的能力。
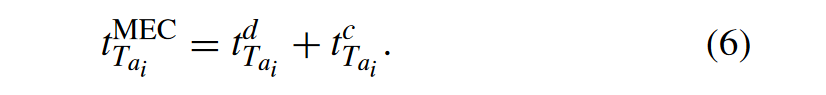
最终的计算延迟的表述为:

四、预备知识(only 1 page)
五、问题阐述(only 2 pages)
在多智能体问题中,像 DQN 这样的传统强化学习算法存在障碍。最重要的原因是在训练过程中,对于每一个agent来说,其他agent都是环境的一部分,其他agent的变化会使环境变得不稳定,这就打破了Q-learning算法所需要的马尔可夫假设。因此,DQN 在多智能体环境中不容易收敛。在本节中,我们考虑 IIoT 中 MEC 的多通道访问和任务卸载问题。然后,我们提出了一种基于 MADDPG 的算法,如算法 1 所示,应用于我们的问题,以便 MTA 可以学习合作策略并提高系统效率。
奖励分为两个部分 the channel quality reward 和 time difference reward for the MTAi
the channel quality reward
当MTA将计算任务卸载给MEC服务器时,考虑到多通道访问问题,MTA会根据当前策略选择一个最优通道。如果MTA选择的频道是空闲的,则表示传输成功,奖励设置为+1。如果通道忙,则表示传输失败,奖励设置为-1。
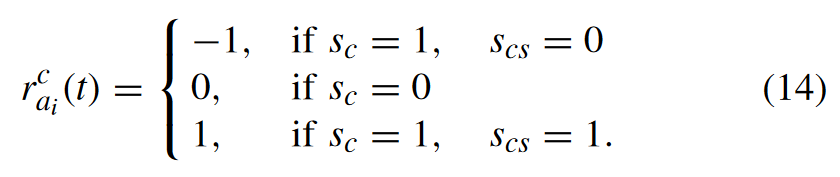
time difference reward for the MTAi
We take the time difference between the local computation delay and the currently obtained delay as part of the reward, which means that the delay reward will be 0 when the MTA process computing tasks locally.
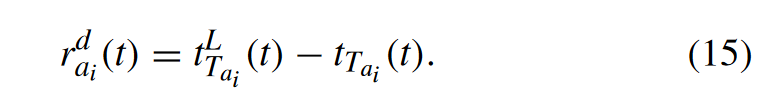
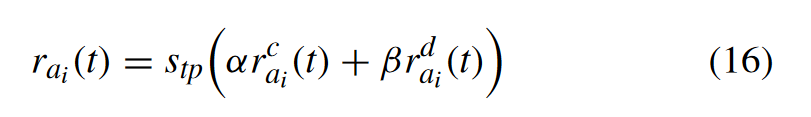
It can be seen that the reward will be 0 if the MTA decides to calculate task locally at one time slot, and we use this as a comparison item. MTA will get a positive reward if the MTA obtains a lower delay than the local calculation. Otherwise, a negative reward will be obtained. Then, the total reward at time slot t is the sum of the reward all MTAs have obtained, which is denoted as
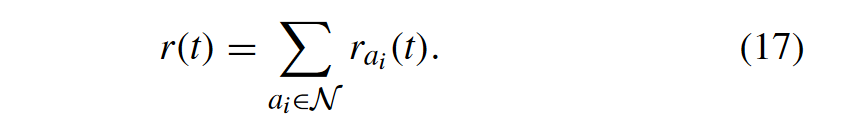
基于 MADDPG 的多通道访问和任务卸载
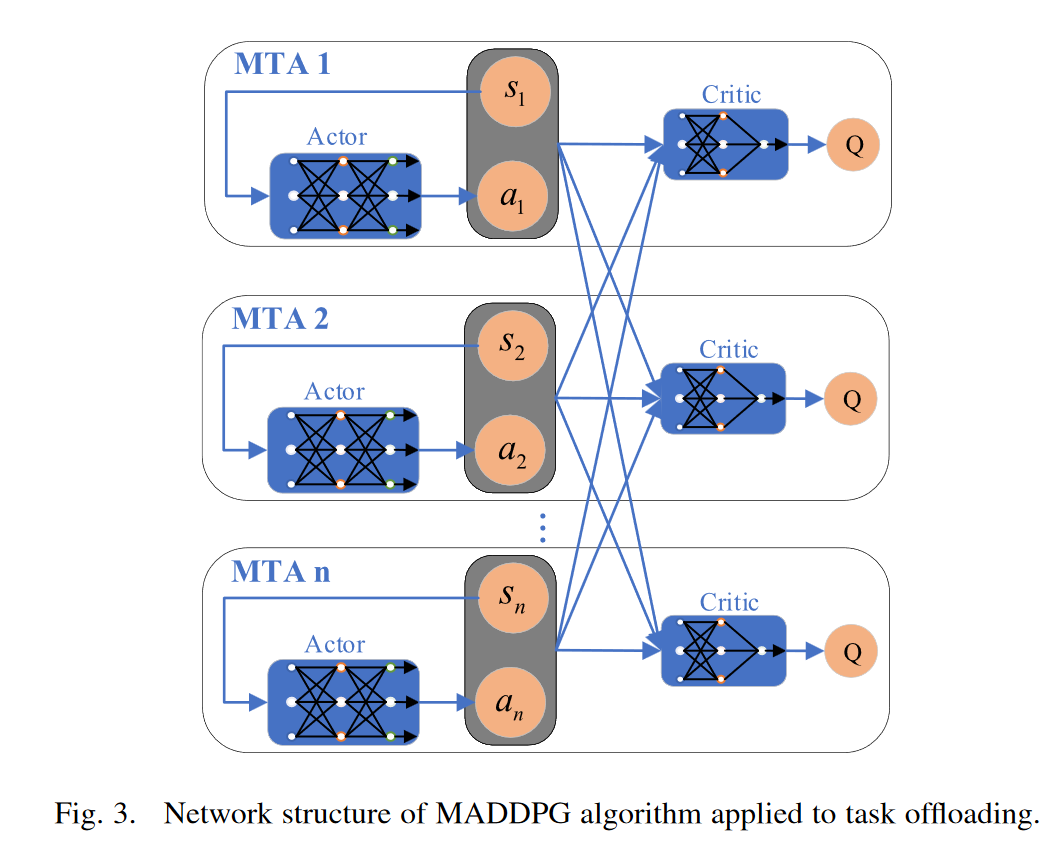
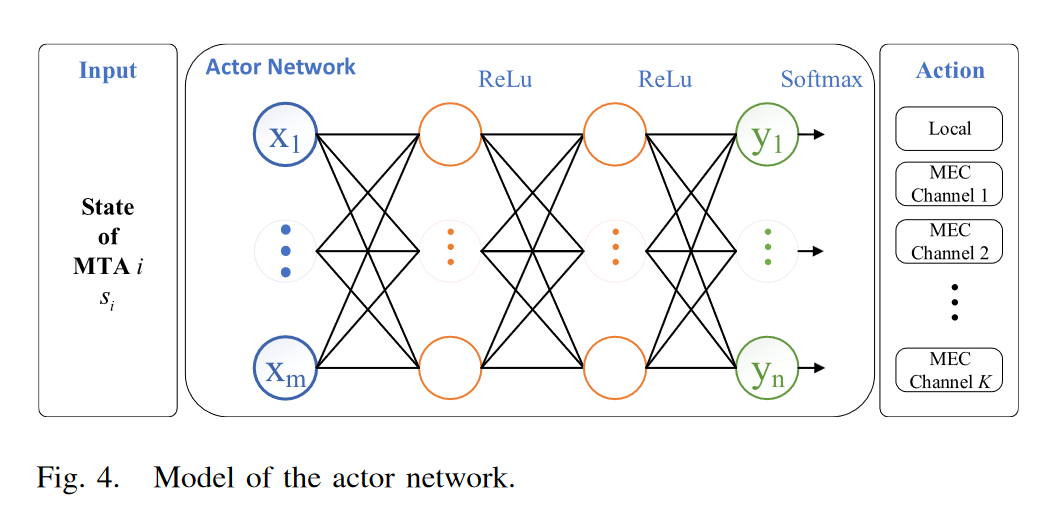
行动者网络:图 4 描述了应动者网络的细节。对于每个MTA,actor网络的输入是它的状态,表示为si(t),然后通过带有ReLU激活层的两层全连接网络。最后,输出层节点的数量是所有可能动作的数量(即K + 1,包括卸载到MEC服务器并在本地计算时的K个通道选择)。输出层经过一层softmax,输出的每个值代表对应动作的概率。最终的输出动作是根据输出概率随机选择的,输出动作用长度为K+1的one-hot向量表示。one-hot是一种将离散特征的值扩展到欧空间的编码方式,使机器更容易处理数据。然后,one-hot vector 可以转换为特定的通道选择 au(t) 和设备选择 ac(t)。为了避免陷入局部最优,我们还将探索概率固定为0.05来输出随机动作。
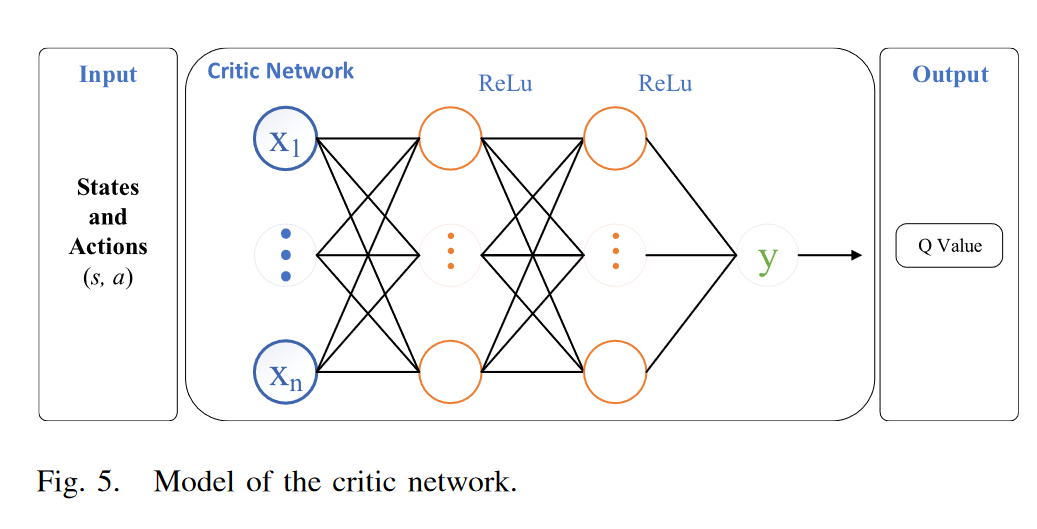
评论家网络:图5描述了评论家网络的细节。评论家网络比演员网络简单。它由两个全连接的网络隐藏层和一个单节点的输出层组成。激活函数为ReLU。图5所示。评论家网络模型。评论家网络的输入是所有mta的状态s和动作a,输出是q值。q值可记为Qπ (st, at)。
关于网络的训练过程(核心算法部分)
在每个时隙开始时,每个MTA都会从全局经验回放缓冲区D中采样S个随机样本的minibatch。将minibatch输入到critic网络后,将得到长度为S的Q值向量。演员网络可以用采样梯度更新,表示为

此外,在训练网络时,actor 网络需要本地信息(即每个 MTA 本身的状态)和 critic 网络输出的 Q 值, 而 critic 网络需要有关所有 MTA 的信息。训练完成后,执行阶段只需要actor网络,每个MTA可以根据自己的状态信息做出最优动作。
实验部分
下面的actor-critic算法假设每一个MTA并不知道其他MTA的信息。

作者设计的baseline
此外,为了提供基线,我们设计了贪心策略。我们假设在贪心策略下所有通道的状态都是已知的。在每个时间段,如果任务成功卸载到 MEC 服务器,MTA 会计算奖励。如果reward大于0且有空闲通道可用,则任务会通过随机空闲通道卸载到服务器,否则任务会在本地计算。显然,由于缺少其他MTA 的信息,当空闲信道的数量远小于将向服务器卸载任务的MTA 的数量时,将导致信道拥塞。 该策略虽然不能达到全局最优,但可以代表单智能体算法在多智能体环境下所能获得的理论上的最优结果。
附录
缩写名词
mobileedge computing (MEC)
the industrial Internet of Things (IIoT) 工业互联网
machine-type agent (MTA)
unmanned aerial vehicles (UAVs) 无人驾驶飞行器
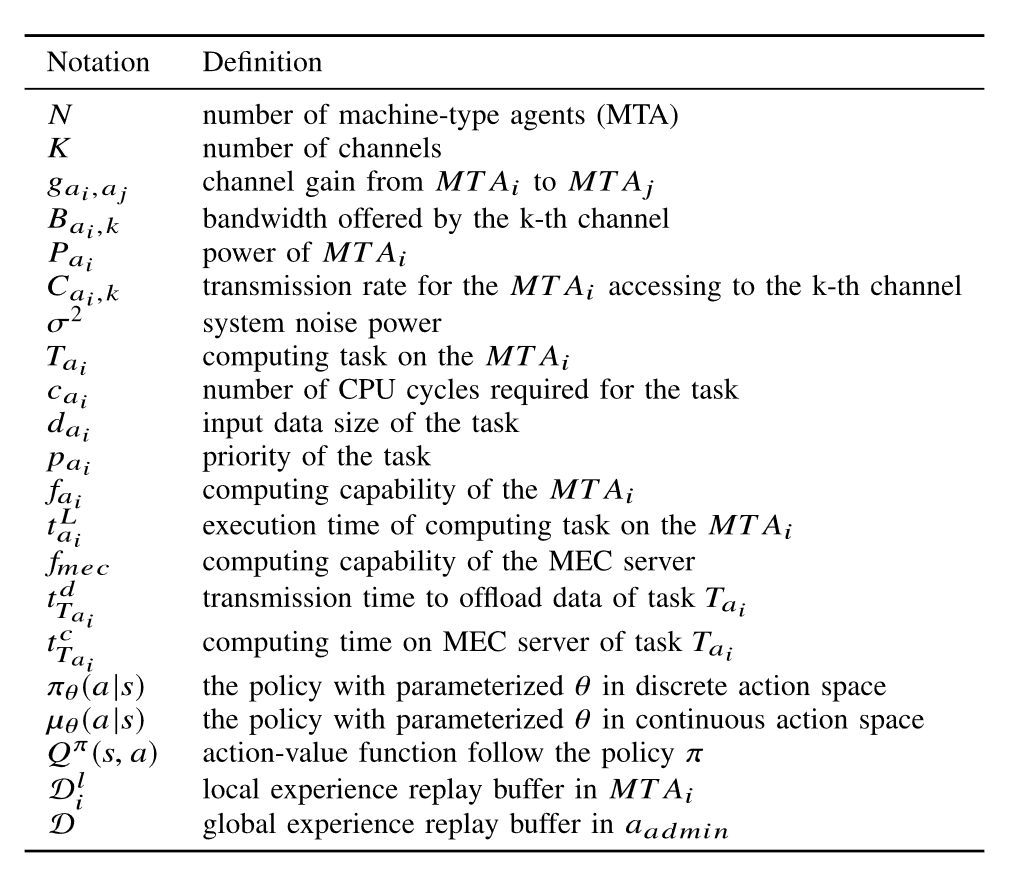
符号说明
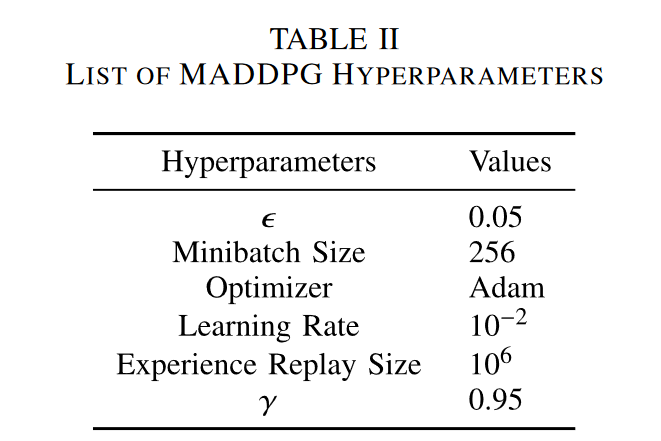
实验中的超参数的设定















 7768
7768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









