









摘要
大多数现有的多视图聚类方法都假设所有的视图都是完整的。然而,在许多真实场景中,多视图数据往往是不完整的,例如,硬件故障或数据收集不完整。(发现问题,必要性)
本文提出了一种自适应加权图融合不完全多视图子空间聚类(AWGF-IMSC)方法来解决不完全多视图聚类问题。
首先,为了消除原始空间中存在的噪声,将完整的原始数据转换为潜在的表示(深度表示呗),这有助于更好地构建每个视图的图。
然后,我们将特征提取和不完全图融合合并到一个统一的框架中,而两个过程可以相互协商,用于图学习任务。
对完整图进行稀疏正则化,使其对视图不一致性具有鲁棒性。此外,还可以自动学习不同视图的重要性,进一步指导完整图的构造。
提出了一种有效的迭代算法来解决具有收敛性的优化问题。
1.引言
多视图数据比传统单模态特征表示,可以提供更足够的信息。此外,不同的视图包含视图内部的特定信息和视图内部的互补信息,这些信息可以相互协调,以提高聚类的性能[5-14]。
基于不同的机制,可将现有的多视图聚类方法分为四类。
- 第一类是多核聚类。通常结合多个预定义的核来达到最优的聚类结果[12,15-17]。
- 第二种是协同训练和协同正则化的[18,19]。迭代地学习多个聚类结果,可以为来自不同视图的未标记数据提供预测的聚类索引。这样,聚类结果就被迫在不同的视图之间保持一致。
- 第三种策略协同地将多视图信息转换为一个紧凑的公共二进制代码空间。然后,在汉明空间中对聚类过程进行测量,具有优越的算法效率[20,21]。
- 最后一种机制是基于子空间的多视图聚类方法。其基本思想是找到嵌入在潜在空间中的几种低维表示,并最终获得对下游聚类任务[26]的统一表示。
- 此外,基于矩阵分解(NMF)寻找共享的低维潜在表示,非负矩阵分解([27]的多视图聚类方法[28-31]也可以看作是基于子空间的多视图聚类方法的一个分支。
这些传统的多视图聚类算法仍不能有效地处理特征不完整的多视图数据。因此,不完全多视图聚类算法[32-34]引起了广泛的关注。
现有的不完全多视图聚类算法可以分为两类:基于非负矩阵分解(NMF)的方法和基于图的方法。
基于NMF的方法旨在通过非负矩阵分解直接获得一种常见的低维表示。他们中的大多数采用将特定视图和公共表示组合成统一的策略[35-37]。
另一种代表性方法是用平均特征值填充缺失数据,然后使用加权非负矩阵分解来减少缺失样本[38]的影响。
这些基于NMF的方法可以直接获得与不完整样本的一致表示。
但是,它仅限于以下两点:(1)当视图数量超过两个时,视图的公共部分将显著减少,并且不能学习视图之间的共享表示;(2)基于NMF的方法通常忽略数据的内在结构,导致未压缩的表示。
基于图的不完全多视图聚类算法比基于NMF的方法对探索数据的几何结构更有效。
然而,由于在不完整的多视图聚类中缺乏部分样本,不可能构造一个连接所有样本的完整图。为了解决这个问题,[39]首先填充缺失的部分,然后学习图表示。[36]利用NMF获得一致的表示,以指导局部结构图的生成。
然而,当缺失率较高时,填充策略将主导表示的学习,导致填充的样本相互连接。此外,信息融合是指融合多个源以实现一致性。在这一阶段,多重视图被平等地对待,这在实际应用中是不合理的。(发现问题)
为了解决上述问题,本文提出了一种不完全多视图聚类方法,在潜在嵌入子空间中构建实例之间的图。这样就可以使用任意数量的视图来处理多视图数据。
此外,还引入了一种自适应加权机制,将图与局部结构融合成一个完整的图。通过这种方式,我们建立了缺失样本和未缺失样本之间的关系。
在共识完全图上施加了一个额外的稀疏正则化项,以消除视图与每个视图中的噪声或异常值之间的不一致的不利影响。
在获得潜在空间后,诱导相似图融合,提取内部视图的局部结构。这样,就可以在潜在空间中消除原始空间中存在的噪声,有助于更好地进行图的构造。
它将缺失的样本和完整的样本之间的关系合并到完整的图中。对完整图施加的稀疏约束改善了视图的不一致性,减少了视图之间的差异,使所提出的方法在大多数情况下更具鲁棒性。
每个视图的重要性都会在优化过程中被自动学习和自适应优化。因此,该重要的观点在学习过程中具有很强的指导作用。此外,对视图的数量没有限制,该方法适用于任何多视图数据集。
2.符号
算子A+在保持非负元素的同时,将矩阵A中的负元素变为0
3.相关
3.1.单个视图的半非负矩阵分解
非负矩阵分解(NMF)是矩阵分解领域的一个重要分支。NMF的目的是寻找两个非负矩阵U和V来大致近似于原始数据矩阵,即X≈UV。
半NMF[42]是传统NMF的扩展,它只要求系数矩阵是非负的。
虽然现有基于NMF的方法可以从不完整的视图中学习到共识表示,但视图的数量和局部结构的缺失限制了它们的性能。
3.2.子空间聚类
子空间聚类是传统聚类方法的扩展,该方法旨在在不同的子空间[45,46]中对数据进行分组。子空间聚类的自表示特性[47]旨在通过它们自身的线性组合来表示数据点。
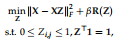
(看起来就是上面的NMF加了个惩罚约束)
由于自表示系数矩阵Z反映了样本之间的相关性,它可以看作是一个图,然后我们可以对其进行光谱聚类算法,得到最终的聚类结果。
3.3.自适应图学习的多视图谱聚类(IMSC-AGL)
IMSC-AGL从每个视图单独形成的低维表示中优化共享图。此外,还引入了一个核范数约束,以保证理想图的低秩性质。
未来仍然可以从超参数的数量中得到改进,并考虑以加权的方式融合多个信息。
4.方法
4.1.自适应加权图融合不完全的多视图子空间聚类
对于不完整的多视图数据,删除不完整的实例。我们假设半NMF将输入数据X(i)分解为基矩阵U(i)和系数矩阵V(i)。
考虑到每个视图中缺失样本的不同,我们学习每个视图中相应可见样本的潜在表示。
为了进一步利用视图内相似性结构和底层子空间结构,利用k×n维潜在表示V(i)上的自表示属性[47]来构造图。因此可以通过解决以下问题得到单个视图的不同图Z(i):
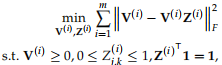
在获得每个视图上的图后,自然的想法是将多个不完整的信息整合成一个完整的信息。为了建立不完全图和完全图之间的对应关系,构建索引矩阵O(i)
通过索引矩阵可以实现完整图和不完整图之间的转换: Z ( i ) = O ( i ) Z ∗ O ( i ) T Z^{(i)}=O^{(i)}Z^∗O^{(i)T} Z(i)=O(i)Z∗O(i)T或 O ( i ) T Z ( i ) O ( i ) = Z ∗ ^ O^{(i)T}Z^{(i)}O^{(i)}=\hat{Z^∗} O(i)TZ(i)O(i)=Z∗^。由于图的大小和视图之间的相似性大小不同,直接合并多个图是不合理的。因此将多个信息集成到一个具有自适应学习权值的完整图中。借助索引矩阵,可以从Z∗中提取相关元素。然后,可以自适应地融合出一个具有自动学习权值的完整图














 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









