







2021
摘要
主导的多模态命名实体识别(MNER)模型并没有充分利用不同模态语义单元之间的细粒度语义对应,这具有细化多模态表示学习的潜力。
引言
如何充分利用视觉信息是MNER的核心问题之一,它直接影响了模型的性能。
尝试:
(1)将整个图像编码为全局特征向量(图1(a)),可用于增强每个单词表示(月亮、内维斯和卡瓦略2018),或指导单词学习视觉感知表示(Lu等2018;张等2018);(就是节点级分类那种实现方式,比如一张人脸图像整体得到一个嵌入)
(2)将整个图像平均分割成多个区域(图1(b)),并基于变换框架与文本序列交互(Yu等2020)。(就是图级实现的一种方式,类似超像素图块,ZSL还有ViT说的那个patch那种处理)
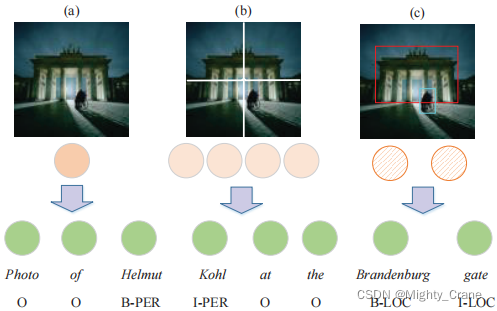
它们并没有充分利用输入句子-图像对中语义单元之间的细粒度语义对应
例如a图是隐式的全局信息
b图是包含了多个平均分割区域的局部信息,但它仍然是隐式的
这两种信息将“门”的线索传播到文本表征上是不同的。这一重要线索的开发失败可能是由于两大挑战:1)如何构建一个统一的表示来弥合两种不同模式之间的语义差距;2)如何实现基于统一表示的语义交互。
于是用了c(这种目标检测就有点任务特定了,是图像中明确可以boundingbox的那种)
方法
构图
节点
文本还是单词做节点
视觉就是bounding box
连边
intra节点全连接,inter节点是对应同一个东西的连起来
融合
intra自注意力,inter门控(和a novel那篇一毛一样)














 2723
2723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









