






 文章介绍了如何利用MiniGPT-4等大型视觉语言模型在工业异常检测(IAD)任务中的应用,通过提示嵌入和轻量级解码器改进模型对细粒度语义的理解,以及如何通过模拟异常数据和多模态学习提高模型的实用性和准确性。
文章介绍了如何利用MiniGPT-4等大型视觉语言模型在工业异常检测(IAD)任务中的应用,通过提示嵌入和轻量级解码器改进模型对细粒度语义的理解,以及如何通过模拟异常数据和多模态学习提高模型的实用性和准确性。
摘要
MiniGPT-4 和 LlaVA 等大型视觉语言模型 (LVLM) 已经证明了理解图像的能力,并在各种视觉任务中取得了卓越的性能。尽管由于训练数据集广泛,它们在识别常见对象方面具有很强的能力,但它们缺乏特定的领域知识,并且对对象内的局部细节的理解较弱,这阻碍了它们在工业异常检测 (IAD) 任务中的有效性。另一方面,大多数现有的IAD方法只提供异常分数,需要手动设置阈值来区分正常和异常样本,这限制了它们的实际实现。
引言
包括MiniGPT-4[36]、BLIP-2[15]和PandaGPT[25]在内的新方法通过将视觉特征与文本特征对齐,进一步将llm的能力扩展到视觉处理
由于真实样本的稀有和不可预测性,模型只需要在正常样本上进行训练,并区分偏离正常样本的异常样本。(说白了就是二分类的lowshot吧)
使用 IAD 数据进行直接训练会带来许多挑战。
第一个是数据稀缺。LlaVA [17] 和 PandaGPT [25] 等方法在 160k 图像上进行了预训练,具有相应的多轮对话。然而,现有的 IAD 数据集 [1, 37] 仅包含几千个样本,使得直接微调容易过度拟合和灾难性遗忘。为了解决这个问题,我们使用提示嵌入来微调 LVLM 而不是参数微调(类似于LLM中的prompt调优吗)。在图像输入后添加额外的提示嵌入,将补充的 IAD 知识引入 LVLM。
第二个挑战与细粒度语义有关。我们提出了一种基于轻量级、视觉-文本特征匹配的解码器来生成像素级异常定位结果。解码器的输出通过提示嵌入引入 LVLM 以及原始测试图像,这允许 LVLM 利用原始图像和解码器的输出进行异常确定,提高其判断的准确性。
贡献
• 我们提出了 LVLM 在解决 IAD 任务方面的开创性利用。我们的方法不仅检测和定位异常,无需手动阈值调整,而且支持多轮对话。据我们所知,我们是第一个成功地将 LVLM 应用于工业异常检测领域的人。
• 在我们的工作中,基于轻量级、视觉-文本特征匹配的解码器解决了LLM对细粒度语义识别较弱的局限性,缓解了LLM仅生成文本输出受限能力的约束。
• 我们使用提示嵌入进行微调,并与 LVLM 预训练期间使用的数据同时训练我们的模型,从而保留 LVLM 的固有能力和启用多轮对话。
• 我们的方法保留了强大的可迁移性,并且能够在新数据集上参与上下文小样本学习,从而产生出色的性能。
相关工作
IAD
有基于重构的方法(GAN、AE、扩散网络等,将异常样本重构为对应的正常样本,通过计算重构误差检测异常,相当于求差得到蒙版什么的)和基于特征嵌入的(相当于专门学正常样本的分布)
这些方法通常遵循“单类模型”学习范式,为每个对象类需要大量的正常样本来学习其分布,这使得它们对新的对象类别不切实际,不太适合动态生产环境。
(每个对象类是什么意思,不是只有一个正常类别吗,你要只说正常样本少的话我还能理解接受,扯这些就有些迷惑了)
Zero-/Few-shot 工业异常检测
最近的工作集中在利用最小正常样本来完成 IAD 任务的方法。
这些方法在推理过程中只能为测试样本提供异常分数。为了将正常样本与异常样本区分开来,有必要实验确定测试集上的最佳阈值,这与仅利用正常数据的 IAD 任务的原始意图相矛盾。例如,虽然 PatchCore [23] 在无监督设置下在 MVTec-AD 上实现了 99.3% 的图像级 AUC,但在使用统一的阈值进行推理时,其准确性下降到 79.76%。
相比之下,我们的方法使 LVLM 能够直接评估存在异常并精确定位其位置的测试样本,显示出增强的实用性。
方法
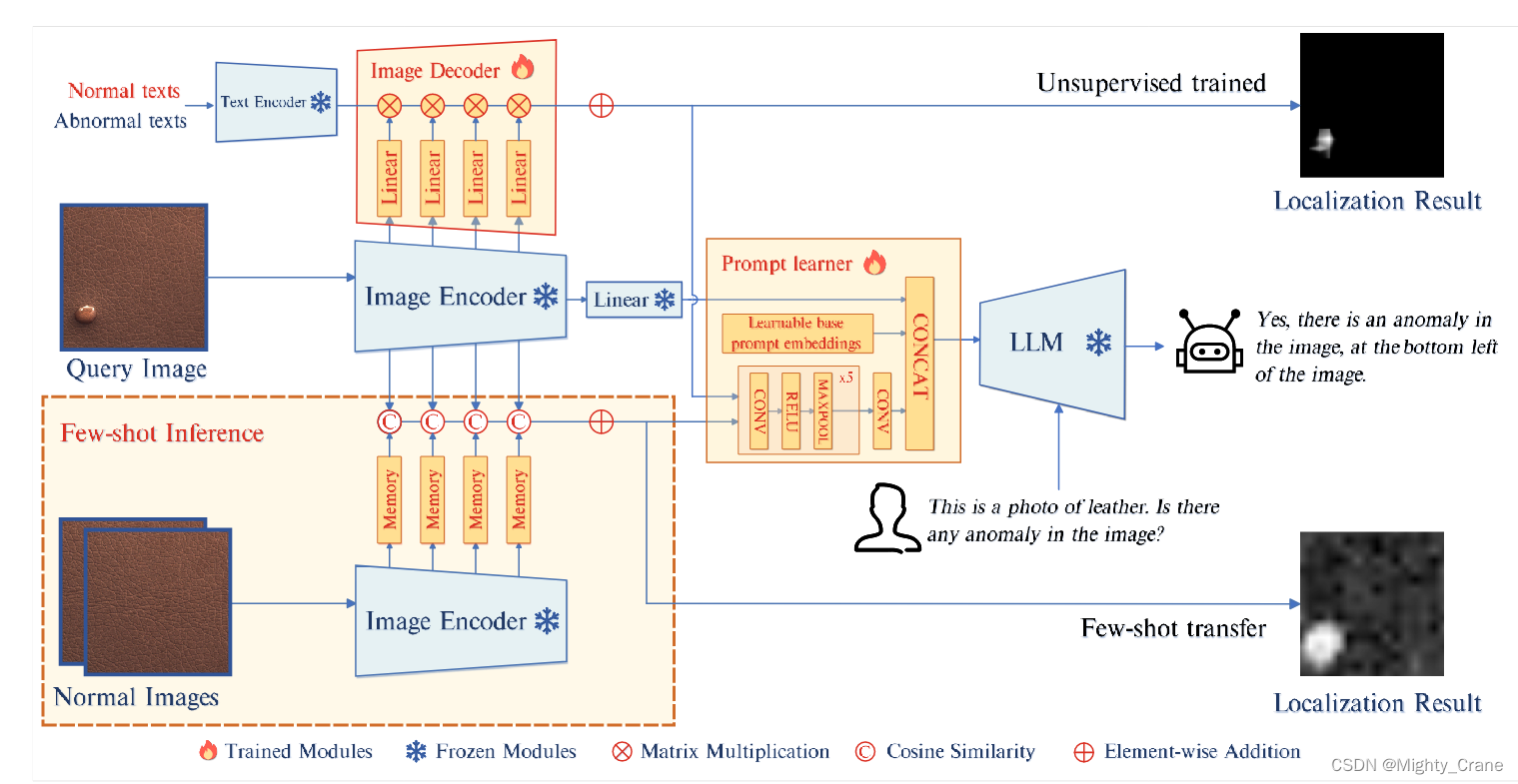
给定一个查询图像x,图像编码器提取的最终特征Fimg通过线性层得到图像嵌入Eimg,然后将其送入LLM
(这一过程是冻结的,ImageBind Huge[8])。
在无监督设置中,图像编码器中间层提取的补丁级特征与文本特征一起输入到解码器(左上,linear用于模态对齐)中,生成像素级异常定位结果(右上)。(那么这一过程就是一个简单的视觉文本双模态检测呗,不涉及LLM)
在few-shot设置中,来自正常样本的补丁级特征存储在内存库中,通过计算查询补丁与其记忆库中最相似的对应块之间的距离来获得定位结果(还真是在拿patch做匹配检索,那复杂度挺大吧)。定位结果随后通过提示学习器转换为提示嵌入(包括无监督和fewshot两部分的),作为LLM(Vicuna-7B)输入的一部分。LLM利用图像输入、提示嵌入和用户提供的文本输入来检测异常并识别它们的位置,从而为用户生成响应。
把patch特征存入内存库后计算每个patch与内存库中最相似的对应patch之间的距离
Prompt
利用来自图像的细粒度语义并保持 LLM 和解码器输出之间的语义一致性,我们引入了一个提示学习器,它将定位结果转换为提示嵌入。此外,可学习的基本提示嵌入与解码器输出无关,被纳入提示学习器,为 IAD 任务提供额外的信息。最后,这些嵌入以及原始图像信息被输入到LLM中。
用于模态对齐的数据
异常模拟(视觉输入)
我们主要采用NSA[24]提出的方法来模拟异常数据。NSA [24] 方法建立在 Cut-paste [14]技术的基础上,通过结合泊松图像编辑 [20]方法来缓解粘贴图像块引入的不连续性。剪切粘贴[14]是IAD领域用于生成模拟异常图像的常用技术。该方法涉及从图像中随机裁剪一个块区域,然后将其粘贴到另一个图像中的随机位置,从而创建一个模拟的异常部分。模拟异常样本可以显著提高IAD模型的性能,但这一过程往往会导致明显的不连续,如图3所示。泊松编辑方法[20]通过求解泊松偏微分方程,将一幅图像中的对象无缝克隆到另一幅图像中。

问题和答案内容 (文本模态
为了对 LVLM 进行提示调优,我们基于模拟异常图像生成相应的文本查询。具体来说,每个查询由两个组件组成。
第一部分涉及输入图像的描述,提供有关图像中存在的对象及其预期属性的信息,例如这是皮革的照片,应该是棕色的,没有任何损坏、缺陷、缺陷、划痕、孔洞或破碎的部分。
第二部分查询对象内部异常的存在,即图像中是否有任何异常。LVLM 首先响应是否存在异常。如果检测到异常,模型继续指定异常区域的数量和位置,例如 Yes,图像中存在异常,位于图像左下角。或否,图像中没有异常。我们将图像划分为 3 × 3 不同区域的网格,以促进 LVLM 口头指示异常的位置,如图 4 所示。关于图像的描述性内容为 LVLM 提供了输入图像的基础知识,有助于模型更好地理解图像内容。然而,在实际应用中,用户可以选择省略这个描述性输入,并且该模型仍然能够仅基于提供的图像输入执行 IAD 任务。附录 C 中提供了每个类别的详细说明。

prompt的格式是:
### Human: <Img>Eimg </Img>Eprompt[Image Description]Is there any anomaly in the image?###Assistant:Eimg ∈ RCemb 表示通过图像编码器和线性层处理的图像嵌入,Eprompt ∈ R(n1+n2)×Cemb 是指提示学习器生成的提示嵌入,[图像描述] 对应于图像的文本描述。
(这些占位符已经是张量而不能使文本token了吧,那就相当于直接把张量写进句子里给LLM去理解吗)
损失
交叉熵-》训练语言模型,它量化了模型生成的文本序列与目标文本序列之间的差异(相当于是逐个token的多分类任务)
焦点损失[16]通常用于目标检测和语义分割,以解决类不平衡的问题,它引入了一个可调参数γ来修改交叉熵损失的权重分布,强调难以分类的样本。在IAD任务中,异常图像中的大多数区域仍然正常,使用焦点损失可以缓解类不平衡的问题。
(好像就是yolov6的那个吧)
其中 n = H × W 表示像素的总数,pi 是正类的预测概率,γ 是调整难以分类样本权重的可调参数。在我们的实现中,我们将 γ 设置为 2。(tunable可调参数是指调参的超参数吧,区别于trainable的参数?这小词整的)
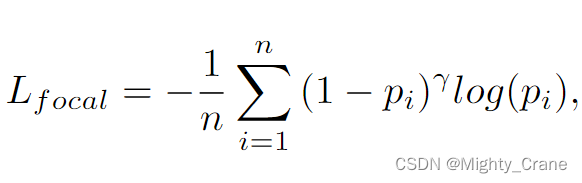
骰子损失[18]是语义分割任务中常用的损失函数。它基于骰子系数,可由式(5)计算:
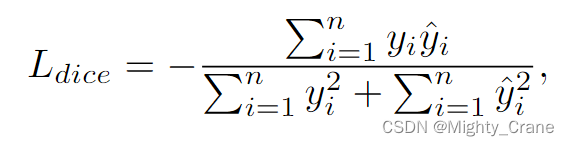
最后仨损失再加权和
数据集
我们主要在MVTecAD[1]和VisA[37]数据集上进行了实验。
MVTec-AD数据集包括15个不同类别的3629张训练图像和1725张测试图像,使其成为IAD最流行的数据集之一。训练图像仅由正常图像组成,而测试图像包含正常图像和异常图像。图像分辨率从700×700到1024×1024不等。
VisA是新引入的IAD数据集,包含12个类别的9621张正常图像和1200张异常图像,分辨率约为1500×1000。与之前的IAD方法一致,我们只使用这些数据集的正常数据进行训练。
实验结果

(看这个示例感觉就像个单纯的程序一样不像AI,输入输出的话都是按照格式的)

















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









