









Improving Neural Fine-Grained Entity Typing with Knowledge Attention
- 用于:Fine-grained entity typing细粒度实体类型(它将实体划分为大量细粒度类型,更多类型,可能有层次嵌套)
- 以前:关注上下文的复杂关联,忽略了在知识库中的丰富的背景知识
- 本文:KBs+上下文+mention,attention
1 当前不足
- 将mention和上下文分割开考虑,没考虑他们之间的联系
- 实体上下文分离。现有的方法通常将实体提及(mention)和上下文单词编码为单独的特性,而不考虑它们之间的相关性。但是,可以直观地看出,每个上下文单词的重要性都受到相关实体的显著影响。例如,在盖茨和艾伦共同创立的微软成为最大的软件公司这句话中,当我们决定实体的类型时,上下文单词“公司”是很重要的,但是当我们决定盖茨的类型时,上下文单词“公司”就不那么重要了。
- 没有想过用KBs
- 背景知识是很重要的
- 文本知识分离。知识库(KBs,也称为知识图),如YAGO、Freebase,以三元组(h、r、t)的形式提供了实体之间关系的丰富信息,其中h、t是头实体和尾实体,r是它们之间的关系。这些信息描述了实体之间的关系和交互,因此对实体类型很有帮助。例如,给定一个triple (USA, shared border with, Canada),可以推断,在某句话中,Canada很可能是一个国家。但是,在以前的w中,从来没有使用过关系信息。
2. 本文的想法

为了解决实体-上下文分离和文本-知识分离的问题,我们提出了KnowledgeAttention神经细粒度实体类型(KNET)。如图1所示,我们的模型主要由两部分组成。首先,我们建立一个神经网络来生成上下文和实体提及表示。其次,在实体提及的基础上,运用知识注意力关注重要的语境词,提高语境表达的质量。知识注意力的计算采用实体嵌入的方法,它从知识库的相关信息中学习,然后从文本中重构。考虑到我们将在测试中同时遇到in-KB和out- KB实体,我们提出了一个消除歧义的过程,不仅可以为in-KB实体提供精确的KB信息,还可以为out- KB实体提供有用的知识
- 神经网络生成context和mention的表达
- 在mention的基础上,从KB中拿出了mention的表达,来做context的attention权重
- knowledge attention :基于mention+in-KB+out-KB
- 内涵消歧过程
- 给in-KB提供精确的KB信息
- 给out-KB提供有用的知识
3.相关工作
-
Dong等人(2015)首次尝试探索只使用词嵌入作为特征的实体输入中的深度学习。此外,
-
Shimaoka等人(2016)为FET引入了一种基于注意力的长短时记忆(LSTM),
-
Shimaoka等人(2017)将手工制作的特征加入到基于注意力的神经模型中。
-
—》然而,这些神经模型遇到了实体-上下文分离和文本-知识分离的挑战。本文试图通过结合KBs的丰富信息来解决这些问题
-
KBs在之前的许多著作中都被考虑过(Del Corro et al. 2015;Ren等人2016a;Yaghoobzadeh和Schutze 2017)。然而,他们只考虑知识库中每个实体的类型信息,而忽略了丰富的关系信息(不同实体之间的关系),而这些信息恰好是知识库的重要组成部分。在本文中,我们使用知识表示学习将关系信息合并到实体类型中(详见下一小节)。
-
之前
- 只考虑了KB中的实体类型信息
- 忽略了关系信息
-
句子级别
- Schutze (2015;2017)考虑体级神经实体类型。语料库级实体类型化旨在从大型语料库中推断出实体的全局类型,通常是通过聚合所有提到实体的句子的信息来实现的。相反,句子级实体类型化试图检测单个句子中提到的实体的局部类型,而相同的实体在不同的句子中可能具有不同的类型。我们的工作重点是句子级的实体类型。
4.KNET
- 我们利用TransE来检查将KB的关系信息合并到实体类型中的有效性。
- 目的:给定一个句子,其中包含一个提到的实体及其上下文,以及一组实体类型(分类法)T,我们的模型旨在预测该实体提到的每种类型的概率。
4.1encoder
特征向量x(输入),m-mention,c-上下文
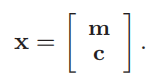
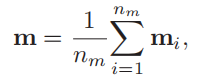
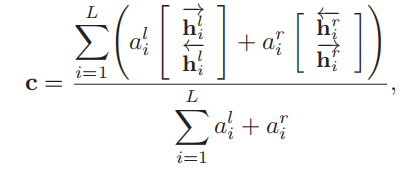
- m-各个mention的均值
- 对于mention的embedding计算,就是取各自的embedding然后取平均。这里的embedding都是预训练的。
- nm—实体mention的个数
- c-上下文
- 双向lstm的编码加权(attention)和
4.2类型预测
- 多层感知机得到y(各个类型下的概率)
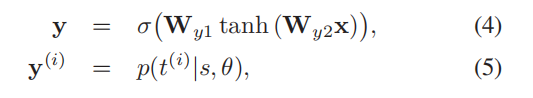
- >0.5为正,没有大于0.5则取最大的
- 目标函数/loss(交叉熵)
4.3attention
-
a l i , a r i a_{l_i},a_{r_i} ali,ari
-
1)Semantic attention:简单地将上下文表示本身作为注意查询,这是由(Shimaoka et al. 2017)提出的,将作为我们的基线方法
- MLP(多层感知机)
- l,r的计算相同
- 所有实体共享
- 2独立于1
- 我们注意到,所有实体共享用于计算SA的相同MLP。因此,上下文词语的注意是独立于实体的。因此,SA很难关注那些与相应实体高度相关的上下文词。
-
2)mention attention:将实体提表示m作为注意查询,期望获取实体与上下文信息之间的语义关联
- f是二次方程 x 2 x^2 x2,正定且可微
-
3)knowledge attention:将从外部KBs中学习到的实体表示形式作为注意查询,获取实体-上下文和实体-知识库的语义关联。
- 用TransE,将关系嵌入到实体embedding中
- 这里的e是上面mention中的相关实体–m的embedding,Wka是双线性参数
- a i K A = f ( e W K A [ h i → h i ← ] ) a_i^{KA}=f(eW_{KA}\left[\begin{matrix}\overrightarrow{h_i}\\\overleftarrow{h_i}\end{matrix}\right]) aiKA=f(eWKA[hihi])
- 在测试中的knowledge attention:不知道KB与mention的哪个实体有对应,甚至可能是out-KB—用文本信息重建实体embedding(单向lstm)(测试时,不知道上面的e,上面的e是直接从KB得到的,这里需要重新构建)(也可以通过实体链接解决,但实体链接本身就不容易)
- e ^ = t a n h ( W [ m c l c r ] ) \hat{e}=tanh\left(W\left[\begin{matrix}m\\c_l\\c_r\end{matrix}\right]\right) e^=tanh⎝⎛W⎣⎡mclcr⎦⎤⎠⎞
- 在训练时,我们同时学习 e ^ \hat{e} e^通过损失函数
- J K B ( θ ) = − Σ ∣ ∣ e − e ^ ∣ ∣ 2 J_{KB}(\theta)=-\Sigma||e-\hat{e}||^2 JKB(θ)=−Σ∣∣e−e^∣∣2
-
knowledge attention (带消歧的)(KA+D)
- 通过获得的mention的表面名称来减少候选实体
- 想要确定mention到底对应实体的哪一个
- :(1)我们通过匹配实体的表面名称来构建候选实体列表
KBs和实体mention。 - (2)计算text-reconstructed嵌入eˆ和在KBs候选实体表示之间的L2距离,并选择最小距离的候选实体
- 如果KB中没有正确的实体(足够信任)就用近似值

- :(1)我们通过匹配实体的表面名称来构建候选实体列表
5.实验
-
衡量:Micro-F1
-
(Shimaoka et al. 2017)之后,我们使用来自(Pennington, Socher, and Manning 2014)的预先训练好的词嵌入。
-
我们使用Adam Optimizer (Kingma and Ba 2014)和
-
mini-batch of size B进行参数优化。
-
我们还使用TransE from (Lin et al. 2015)的实现来获得实体嵌入。
-
overfittiong:在mention上用dropout
-
因为训练集合和测试集的mention不同,测试集合mention不可见,而上下文并没有什么区别
-
超参数的确定–对这些在一定范围内实验确定
- 学习率
- lstm隐藏层尺寸
- 词向量size
- 窗口尺寸L
- batch size B
-
结果
- MA>SA:注意力有好处
- 所有神经网络模型都比AFET好(AFET用了KB但没有用关系)
- KA和KA+D最好,表明引入KB的有用性
- KA+D>KA:消除歧义有用
- KB-only<KA<KA+D:他不可单独工作

-
消歧的困难
- 在KA+D中,对In - kb实体的消歧取决于不同的上下文环境。上下文要么提供关于实体属性的丰富而有用的信息,要么几乎不包含任何有用的提示。另一方面,消除kb外实体的歧义无疑是错误的。根据消歧过程是否正确,我们将测试集分为正确和错误两个子集,并探讨了各种方法的性能。
- 在正确的子集中表现都挺好
- 在错误的子集中表现差,但KA+D也还可以

6.以后
- 可以试图加上其他KRL的方法除了transE
- 我们将在更复杂的实体类型分类(包含更多的类或更深层次结构)中检查KNET方法的有效性
- 直接使用现有的实体连接工具将不可避免地引入噪声。在我们的模型中减少这种噪声并加入实体链接将是未来值得探索的有趣的事情
- 现有的关于FET的工作已经使用了许多不同的数据集和分类法(Shimaoka et al. 2017),我们也将在各种数据集上进一步探索我们的模型















 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









