






-
Abstract
-
1. Introduction
-
2. Curiosity-Driven Exploration
-
2.1. Prediction error as curiosity reward
- 基于raw sensory space进行下一时刻的预测是不受欢迎的。因为“基于像素进行预测”能不能提供一个好的优化目标,这一点很难说。问题来了,我们基于什么进行下一状态的预测?我们把agent的observation组成分为三种情况:
- (1)agent完全可以控制的事物。
- (2)有一些事物agent不能控制,但是会影响agent。
- (3)agent不能控制的事物,且对agent无影响。
- 一个好的前向预测模型应该能够预测12的同时不被3影响。
- 基于raw sensory space进行下一时刻的预测是不受欢迎的。因为“基于像素进行预测”能不能提供一个好的优化目标,这一点很难说。问题来了,我们基于什么进行下一状态的预测?我们把agent的observation组成分为三种情况:
-
2.2. Self-supervised prediction for exploration
- 我们的目标是找到“学习特征表示”的通用机制,使得:“基于特征空间的预测误差可以提供一个好的内部奖励信号”。
- Inverse dynamics model:【作用主要是学会编码,详细来说:利用反向传播让神经网络学习到真正由action影响的特征】
- 我们通过训练一个具有两个子模块的神经网络来学习这么一个特征空间。第一个子模块把raw state (st)编码到feature vector φ(st),第二个子模块输入φ(st ), φ(st+1 ),输出action (at)上的softmax概率分布。训练网络的目的就是找到这么一个映射g:
-
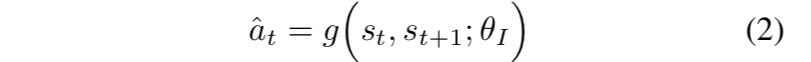
- 其中ˆat是预测得到的动作分布。损失函数如下:
-
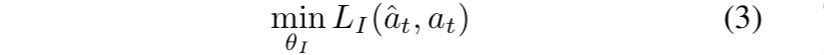
- Forward dy- namics model:【作用是基于特征空间预测下一时刻状态】
- 输入at和φ(st),输出下一时刻的特征编码φ(st)。
-
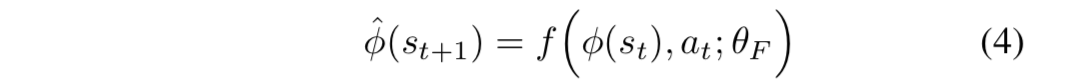
- 损失函数LF如下:
-
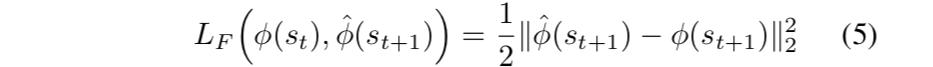
- intrinsic reward signal按照如下方式计算:
-
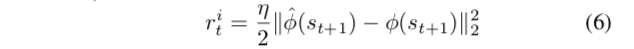
- 为了产生intrinsic reward signal,我们需要联合优化forward and inverse dynamics loss。
- 作者把上述模型概括为Intrinsic Curiosity Module (ICM),总的优化目标如下所示:
-
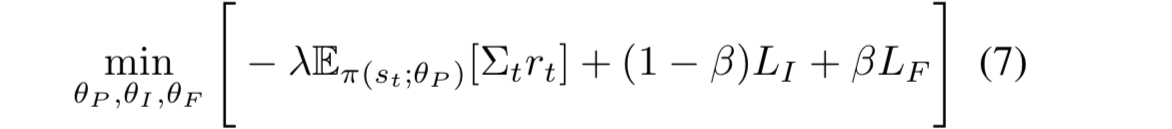
-
-
3. Experimental Setup
- 为了检验“探索能力&泛化到新场景的能力”,使用两个仿真环境进行检验。
-
Environments
- 第一个环境是VizDoom。四个离散的动作:前后左右。当agent找到vest或者步数大于2100时,episode结束。地图:9个由走廊连接的房间。agent需要从随机起点导航到固定目标。只在找到vest获得+1的reward,其余都是0。在进行泛化实验时,使用不同纹理的地图环境进行训练,并且每个episode持续2100步。
- 第二个实验环境是超级玛丽。
-
Training details
- 输入使用四个连续帧的特征进行串联,训练期间执行动作的时候重复四次。而在推理期间,动作不再重复。
-
Baseline Methods
- 3个baseline:
- (1)ε-greedy A3C
- (2)ICM-pixels + A3C
- (3)state-of-the-art exploration methods based on varia- tional information maximization (VIME) which is trained with TRPO
- 3个baseline:
-
4. Experiments
- 使用两个实验定量&定性的分析来有&没有intrinsic curiosity signal的性能。通过实验评估了以下三种设定:
- a) sparse extrinsic reward on reaching a goal
- b) exploration with no extrinsic reward
- c) generalization to novel scenarios
-
4.1. Sparse Extrinsic Reward Setting
- .......
- 使用两个实验定量&定性的分析来有&没有intrinsic curiosity signal的性能。通过实验评估了以下三种设定:
-
【来自18年关于好奇心的文章】局限性:
基于curiosity的定义,当环境变得随机的时候,这里的curiosity就更像是环境的熵了(这么说是基于
 的定义),因而不是更多地探索状态空间了,而是探索环境中熵比较大的位置了。
的定义),因而不是更多地探索状态空间了,而是探索环境中熵比较大的位置了。文章举了一个很有意思的例子,在走迷宫的时候如果在墙上放完全随机的电视画面,那么agent就会更倾向于停在那里看电视而不继续探索了。

















07-07
 1040
1040
1040
04-03
1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









