






知识点记录,持续更新!
1、IIC的SCL SDA是开漏模式,标准模式波特率小于100K,快速模式波特率小于400K,快速模式的占空比,有1/2(高电平是1,低电平是2)和9/16。
I2C(Inter-Integrated Circuit)是一种串行通信协议,广泛应用于嵌入式系统中,用于设备间的通信。在某些情况下,I2C总线需要配置为开漏模式(Open-Drain),这主要是出于以下几个原因:
1)**多主模式(Multi-master Mode)**:
- 在I2C协议中,可以有多个设备作为主设备。开漏模式允许多个主设备共享同一总线,因为只有当主设备主动驱动数据线为低电平时,数据线才会被拉低。
2)**提高驱动能力(Enhanced Driving Capability)**:
- 开漏模式下,数据线可以通过上拉电阻被拉高,而不需要每个设备都提供足够的驱动电流。这可以减少功耗,特别是在总线上连接了多个设备时。
3) **防止电流冲突(Current Conflict)**:
- 如果两个主设备同时尝试驱动数据线,其中一个设备将驱动为低电平,而另一个设备则会被开漏模式的开漏输出所隔离,从而避免了电流冲突。
4) **支持更宽的电压范围(Wider Voltage Range Support)**:
- 开漏模式允许I2C总线在不同的电压级别上工作,因为上拉电阻可以为不同的电压级别提供适当的电平转换。
5)**提高系统的灵活性(Increased System Flexibility)**:
- 开漏模式提供了更多的设计灵活性,允许在不同的硬件配置下使用相同的I2C总线。
6)**减少电磁干扰(Reduced Electromagnetic Interference, EMI)**:
- 开漏模式由于减少了电流的变化,可以降低电磁干扰,这对于需要低EMI的系统非常重要。
7)**支持热插拔(Support for Hot-Plugging)**:
- 在某些应用中,设备可能需要支持热插拔,即在系统运行时连接或断开设备。开漏模式可以更好地处理这种情况,因为它允许设备在没有电源的情况下连接到总线上。
8)**简化设计(Simplified Design)**:
- 在某些情况下,使用开漏模式可以简化电路设计,因为不需要为每个I2C设备添加单独的上拉电阻。
总的来说,开漏模式提供了一种灵活且可靠的方式,以支持I2C总线上的多设备通信和复杂的系统设计需求。
2、ARM系列
ARM7一般没有MMU,ARM9一般有,ARM的A系列和R系列,一般有MMU。需要有MMU才能跑Linux系统。一般ARM的M系列是跑RTOS系统。
3、ELF文件(Executable and Linkable Format):可执行与可链接格式,也算是一种程序文件,相比bin,hex,axf等可执行文件,这种文件包含信息更多、更复杂。
addressline原理:把elf文件通过objdump,反汇编生成lst文件,在lst文件中拿到输出信息。
参数:
-e:指定需要转换地址的可执行文件名;
-a:指定需要查询的地址;
-f:显示函数名;
-i:如果需要转换的地址是一个内联函数,则还将打印返回第一个非内联函数的信息。不仅会显示内联函数的名称,还会显示调用该内联函数的函数名。
例如:addr2line -e rtthread.elf -a -f 1806d33a 1806f884
ELF文件:
除机器码外,还有一些额外信息
– 段的加载地址、运行地址
– 符号表、重定位表等
ELF文件运行,需要OS环境和加载器(loader、ld-linux.so)
Bin文件:
– 只包含机器码,纯粹的程序文件,即镜像文件
– 类似的还有HEX文件
BIN文件运行,只需要将其加载到链接地址即可
ELF和map文件的区别:
- **编译过程**:在程序的编译和链接过程中,ELF文件和map文件都是由链接器生成的。ELF文件是主要的输出文件,包含了可执行的程序代码和数据;而map文件则是辅助性的输出,提供了程序的内存映射信息。
- **信息共享**:两者都包含了程序的符号信息,例如变量和函数的地址,这些信息对于调试和分析程序非常重要。
- **文件格式**:ELF文件是一种二进制文件格式,用于存储可执行代码、对象代码、共享库以及它们的调试信息等数据。它是可执行与可链接格式(Executable and Linkable Format)的缩写,通常用于嵌入式系统中的程序文件。
- **可读性**:与ELF文件不同,map文件是一种文本文件,它以人类可读的格式提供了程序的内存使用情况、变量和函数的地址等信息。它通常用于调试目的,帮助开发者理解程序的内存布局。
- **目的**:ELF文件的主要目的是作为可执行文件,它包含了程序的机器代码和数据对象。而map文件的主要目的是提供程序的内存映射信息,帮助开发者进行调试和优化内存使用。
- **内容**:ELF文件包含了程序的完整二进制内容,可能包含符号信息用于调试,以及将机器代码与源代码相关联的元数据。MAP文件则主要包含代码和数据对象的位置和大小信息,以及内存使用情况的摘要。
addressline -e -f的原理:
**ELF文件结构解析**
- **节头表作用**:ELF文件中的节头表为文件中的各个节提供了必要的信息,如节的大小、偏移量以及节的类型等。这些信息是定位特定数据或代码段的关键。
- **符号表索引**:ELF文件通过符号表来映射人类可读的函数和变量名称到它们的地址。符号表为程序中的每一个符号分配了一个唯一的索引,这个索引被用于间接地址的解析。
- **程序链接表**:程序链接表在ELF文件中扮演着重要的角色,它描述了程序在运行时候的内存布局。程序头表中的每一项都对应一个内存段,包含了该段的地址、大小以及与其他段的关系等信息。
**命令行工具的作用**
- **解析ELF文件**:addressline工具通过解析ELF文件的结构,能够提取出文件中的符号、节头和程序头等信息。这些信息是进一步分析和处理地址映射的基础。
- **符号地址映射**:使用addressline工具时,可以通过提供的符号名查找其在ELF文件中的位置。工具内部会解析符号表,并将符号名映射到相应的地址。
- **地址转换机制**:addressline工具还能够解析程序链接表,从而理解程序加载到内存时的地址转换机制。这对于动态链接的符号尤为重要,因为其地址可能在程序加载时才确定。
**指定选项的作用**
- **`-e`选项**:这个选项允许用户指定要查询的特定节。通过这种方式,用户可以针对ELF文件中的任意部分进行地址查询,而不仅限于默认的文本段或数据段。
- **`-f`选项**:这个选项用于指定输出的格式。用户可以根据需要选择不同的输出格式,以便更好地分析和使用查询结果。
- **组合使用**:当`-e`和`-f`选项组合使用时,它们可以提供更灵活的控制方式,使用户能够以自定义的方式查看ELF文件中特定节的地址信息,并以所需的格式呈现。
**实际应用场景**
- **故障诊断**:在软件开发和故障诊断过程中,开发者可能需要查看特定函数或数据的地址。addressline工具可以帮助快速定位问题所在的代码段。
- **性能优化**:性能优化时常需查看特定函数的地址和大小,以分析其性能瓶颈。addressline工具提供的详细信息有助于性能调优。
- **安全分析**:在进行安全分析时,了解程序的内存布局和函数地址是关键。addressline工具能够帮助安全研究人员快速获取这些信息。
综上所述,addressline -e -f的原理基于对ELF文件结构的深入理解,通过解析文件中的节头表、符号表和程序链接表等信息,实现对特定符号地址的查询和格式化输出。这种机制不仅对于程序的加载和执行分析至关重要,也对于软件的开发、调试和安全分析等领域有着广泛的应用。
4、串口通信一帧数据发送8个bit数据位,每帧数据都有开始位和停止位。
5、当使用fseek函数在文件中偏移100字节而文件长度不足100字节时,fseek会将文件指针定位到文件末尾,并返回成功状态。通过fseek和ftell组合,可以获取文件大小。如果fseek的超过了文件大小,会扩展文件。
6、LittleFS采用日志结构来存储元数据,这意味着它会在块中顺序写入数据,并在必要时进行合并和压缩,以减少存储空间的浪费。
7、ARM寄存器
### 特殊寄存器
- **零寄存器**:当用作目标寄存器时,写操作被忽略,读操作返回0。在很多指令中可以使用,但不是全部
- **栈指针(SP)**:ARMv8体系结构中,栈指针的选择与异常级别有关。每个异常级别都有自己的栈指针,如SP_EL0、SP_EL1等。在AArch64状态下,EL0只能访问SP_EL0,而其他异常级别可以使用专用的64位栈指针或SP_EL0
- **程序计数器(PC)**:在ARMv8中,PC寄存器不再作为直接访问的寄存器,而是隐式地用于某些指令中,如PC相对加载和地址生成。PC不能被指定为数据处理或加载指令的目的操作数
- **异常链接寄存器(ELR)**:保存异常返回地址
- **程序状态保存寄存器(SPSR)**:保存异常发生前的PSTATE值,用于异常返回时恢复PSTATE的值
### 系统控制寄存器
系统控制寄存器(SCTLR)用于控制内存、配置系统能力以及提供处理器核状态信息。不同的异常级别可能拥有独立的SCTLR副本,例如ACTLR_EL1、ACTLR_EL2和ACTLR_EL3
### 影子寄存器(Banked Registers)
ARM体系结构通过影子寄存器的设计,允许在不同工作模式下重复使用相同的寄存器编码,但对应不同的物理寄存器。例如,Abort模式下的R13与用户模式下的R13不同,尽管它们编码相同,实际上却对应不同的物理寄存器
### CPSR和SPSR
CPSR(当前程序状态寄存器)可以在任何处理器模式下访问,包含条件码标志、中断禁止位、当前处理器模式以及其他状态和控制信息。每种异常模式下都有一个对应的SPSR(备份程序状态寄存器),用于保存CPSR的状态,以便在异常返回后恢复
### 寄存器的用途
- R0-R3:通常用于子程序间传递参数或作为返回值。
- R4-R11:主要用于保存局部变量。
- R12:用作子程序间的临时寄存器(scratch register),也称为IP。
- R13:通常用作栈指针(sp)。
- R14:链接寄存器(lr),用于保存子程序和中断的返回地址。
- R15:程序计数器(PC),指向当前执行的指令
8、在嵌入式系统中,同步通信和异步通信是两种基本的数据传输方式,它们各自具有不同的特性和应用场景。下面是这两种通信方式的优缺点:
### 同步通信(Synchronous Communication)
比如IIC,SPI,USB
**优点:**
**高效率**:由于数据传输是连续的,没有额外的同步开销,因此传输效率高。
**高数据速率**:适合高速数据传输,因为可以在短时间内传输大量数据。
**简单性**:在发送和接收端使用相同的时钟,简化了数据同步的复杂性。
**缺点:**
**时钟依赖性**:需要发送和接收设备共享相同的时钟信号,这可能限制了系统的灵活性。
**时钟偏差**:时钟信号的不稳定或偏差可能导致数据同步问题。
**功耗**:在某些情况下,维持时钟信号可能需要较高的功耗。
### 异步通信(Asynchronous Communication)
比如串口通信
**优点:**
**灵活性**:不需要共享时钟信号,适用于不同速率的设备或长距离通信。
**独立性**:每个数据包都有起始位和停止位,使得数据包可以独立传输。
**容错性**:由于数据包独立,即使数据传输中断,也可以重新同步。
**缺点:**
**效率较低**:每个数据包都需要额外的起始位和停止位,增加了数据传输的开销。
**数据速率受限**:由于需要处理每个数据包的同步位,数据传输速率相对较低。
**复杂性**:发送和接收端需要更复杂的逻辑来处理数据包的同步。
9、GPIO(通用输入输出)是一种常见的硬件接口,用于嵌入式系统中的数字信号处理。GPIO端口可以配置为不同的模式,以适应不同的应用需求。以下是一些常见的GPIO模式及其详解:
**输入模式(Input Mode)**:
- GPIO端口被配置为接收外部信号。
- 可以进一步细分为上拉输入、下拉输入等。
**输出模式(Output Mode)**:
- GPIO端口被配置为输出信号到外部设备。
- 可以控制LED、继电器等设备的开关状态。
**上拉输入模式(Pull-Up Input Mode)**:
- 当GPIO端口配置为输入模式时,内部上拉电阻被激活,将输入信号拉高到高电平。
- 适用于外部设备通过下拉电阻将信号拉低的情况。
**下拉输入模式(Pull-Down Input Mode)**:
- 类似于上拉输入,但内部激活的是下拉电阻,将输入信号拉低到低电平。
- 适用于外部设备通过上拉电阻将信号拉高的情况。
**开漏输出模式(Open-Drain Output Mode)**:
- GPIO端口可以输出低电平,但高电平由外部上拉电阻决定。
- 常用于多个设备共享同一信号线的情况,如I2C通信。
**开集输出模式(Open-Collector Output Mode)**:
- 类似于开漏输出,但通常用于双极性晶体管,而不是MOSFET。
- 同样适用于多个设备共享信号线的情况。
**模拟输入模式(Analog Input Mode)**:
- GPIO端口被配置为模拟信号输入,可以读取模拟信号的电压值。
- 通常需要ADC(模拟数字转换器)来转换模拟信号为数字信号。
**特殊功能模式(Alternate Function Mode)**:
- GPIO端口可以配置为特定的特殊功能,如PWM(脉冲宽度调制)、定时器输入/输出等。
- 这通常需要根据微控制器的特定功能来设置。
**中断模式(Interrupt Mode)**:
- GPIO端口可以配置为中断输入,当外部信号变化时,可以触发中断请求。
- 适用于需要快速响应外部事件的应用。
**三态逻辑模式(Tri-State Logic Mode)**:
- GPIO端口可以被配置为高阻态,既不输出也不输入,常用于总线通信。
10、推挽模式(Push-Pull Mode)是一种常见的GPIO(通用输入输出)配置方式,主要用于微控制器或数字逻辑电路中。在推挽模式下,GPIO端口既可以作为输出,也可以作为输入,具有以下特点:
**双向驱动能力**:
- 推挽模式允许GPIO端口在输出时具有较强的驱动能力,可以驱动外部负载。
**输出状态清晰**:
- 在推挽模式下,GPIO端口可以清晰地输出高电平或低电平信号,没有中间状态。
**无需外部上拉或下拉电阻**:
- 与开漏或开集模式不同,推挽模式不需要外部上拉或下拉电阻来确定输出电平。
**内部结构**:
- 推挽模式的GPIO端口内部通常包含两个互补的晶体管或MOSFET,一个用于输出高电平,另一个用于输出低电平。
**应用场景**:
- 适用于需要直接驱动LED、继电器、小型电机等负载的场景。
- 也适用于简单的数字信号传输,如控制其他数字电路的输入。
**功耗**:
- 在推挽模式下,当GPIO端口输出高电平时,内部的低电平输出晶体管关闭,减少了功耗。
- 同样,当输出低电平时,高电平输出晶体管关闭。
**噪声抑制**:
- 由于推挽模式具有较好的驱动能力,它可以减少信号线上的噪声和抖动。
**冲突保护**:
- 在某些微控制器中,推挽模式的GPIO端口可能具有内部保护机制,以防止在输出和输入之间发生冲突。
**配置方式**:
- 推挽模式通常可以通过编程配置,设置GPIO端口的控制寄存器来实现。
**与开漏模式的比较**:
- 与开漏模式相比,推挽模式不需要外部上拉电阻来确定高电平,因此在设计上更为简单。
推挽模式是GPIO端口最基本和最常用的配置之一,适用于大多数需要直接输出数字信号的场景。然而,在设计时,仍需考虑GPIO端口的最大输出电流和电压,以确保不会超出其规格限制。
11、编译优化是编译器在编译过程中对源代码进行的改进,以提高程序的执行效率、减少资源消耗或缩短编译时间等。不同的编译优化等级对应不同的优化策略和强度。以下是一些常见的编译优化等级及其区别:
**-O0**(无优化):
- 不进行任何优化,编译速度最快,生成的代码体积小,但执行效率最低。
- 适用于调试阶段,便于分析程序行为和性能问题。
**-O1**(启用基本优化):
- 启用基本的优化措施,如循环展开、公共子表达式消除等。
- 优化程度适中,编译速度和执行效率之间取得平衡。
**-O2**(优化速度):
- 进一步优化程序的执行速度,可能包括更激进的优化措施。
- 编译时间可能增加,但生成的代码执行效率更高。
**-O3**(优化速度和空间):
- 在-O2的基础上,进一步优化内存使用和执行速度。
- 可能包括更激进的优化,如内联函数、更深层次的循环优化等。
**-Os**(优化大小):
- 优化生成代码的体积,适用于对存储空间有限制的环境。
- 可能牺牲一些执行速度以减少代码大小。
**-Ofast**:
- 启用更多的优化选项,包括那些可能违反严格标准的优化。
- 生成的代码可能执行更快,但可能不符合某些语言标准。
**-Og**:
- 优化的同时尽量保持调试信息的完整性,便于调试优化后的程序。
- 适用于需要优化但又需要保持调试信息的情况。
**-flto**(Link Time Optimization,链接时优化):
- 在链接阶段进行优化,可以跨编译单元进行优化。
- 可以提高程序的执行效率,但会增加编译和链接的时间。
**-finline-functions**:
- 内联所有的函数,包括递归函数。
- 可以减少函数调用的开销,但可能导致生成的代码体积增大。
**-fno-omit-frame-pointer**:
- 保留帧指针,便于调试,但可能会略微影响性能。
不同的编译优化等级会影响程序的性能、大小和调试的便利性。开发者应根据项目的具体需求选择合适的优化等级。例如,开发阶段可能使用-O0或-Og以便于调试,而在发布产品时使用-O2或-O3以提高性能。使用链接时优化(LTO)可以在不牺牲太多编译时间的情况下进一步提高性能。
12、核间通信
共享物理内存方式:
避免竞态的方式:同一个核,可以通过互斥锁,自旋锁的方式,防止同时访问;不同的核,可以通过硬件信号中断来同步,或者硬件消息机制。内存屏障可以解决内存一致性问题。
13、具体来说,当IO口配置为低电平时,IO口通过内部或外部的下拉电阻连接到地,使得IO口输出低电平信号,此时IO口不会向外部电路提供电流,因此不会漏电。同样地,当IO口配置为高电平时,IO口通过内部或外部的上拉电阻连接到电源,使得IO口输出高电平信号,此时虽然IO口与电源相连,但由于上拉电阻的存在,电流被限制在很小的范围内,因此也不会造成显著的漏电。
相比之下,浮空模式(Floating Mode)是容易漏电的一种模式。在浮空模式下,IO口既不上拉也不下拉,其电平状态完全由外部电路决定。由于外部电路可能受到各种干扰和噪声的影响,因此IO口的电平状态可能会频繁变化,导致电流在IO口与外部电路之间来回流动,从而造成漏电。此外,如果外部电路中存在高阻抗路径或漏电通道,也可能导致IO口在浮空模式下漏电。
14、malloc(0)官方解释,可能返回NULL,也有可能返回非NULL。返回的地址是不可存储的。常见的一般返回非NULL。
15、编译构建工具
嵌入式编译构建工具的选择非常多样,它们各自具有不同的特点和优势。以下是一些常见的嵌入式编译构建工具及其区别:
1) Keil MDK:Keil MDK 是一款集成开发环境(IDE),广泛用于ARM Cortex微控制器的开发。它提供了全面的开发工具,包括编辑器、编译器、调试器和仿真器
2) IAR Embedded Workbench:IAR 是一款跨平台的IDE,支持多种编程语言和多种仿真器及调试器。它以其优化编译器和丰富的库支持而闻名
3) STM32CubeIDE:这是STMicroelectronics提供的一款基于Eclipse的IDE,专门用于STM32微控制器的开发。它集成了STM32CubeMX,一个图形化配置工具,用于快速生成STM32的初始化代码和配置文件
4) LLVM/Clang:LLVM是一个编译器基础设施项目,提供了丰富的库,用于构建编译器和工具链。Clang是LLVM项目的一部分,作为前端处理C、C++和Objective-C等语言的编译,而LLVM作为后端进行代码优化和生成
5) GCC:GNU Compiler Collection是一个开源编译器套装,支持多种编程语言和平台。它以广泛的社区支持和平台兼容性著称
6) CMake:CMake是一个跨平台的自动化构建系统,它使用配置文件来生成标准的构建文件,如Makefile或IDE工程文件。CMake广泛用于项目中,因为它可以简化编译过程,并且可以很好地与多种编译器和构建工具集成
7)还有MinGW
每种工具都有其特定的应用场景和优势。例如,Keil和IAR提供了针对特定微控制器的优化和支持,而LLVM/Clang和GCC则提供了更广泛的语言和平台支持。CMake作为一个构建系统,可以与这些编译器配合使用,简化构建过程。开发者可以根据项目需求、目标平台和个人偏好来选择最合适的工具。
16、a++和a--是被拆分成3条汇编指令(1--从内存中读a的值保存在CPU的R0(假设是R0),2--计算a的新值,3--把a的新值写在内存中变量a的位置):加载-计算-保存
17、SPI,IIC
1)SPI是全双工,IIC是半双工,SPI支持更高的传输速率;
2)IIC是两线,通常SPI四线;
3)IIC支持多个主从机,IIC也可以支持,需要通过片选来操作,支持的数量很有限。
18、fatfs32有MBR区,FAT表区,数据区。
BR区用于引导,记录磁盘参数,剩余容量,簇大小等,FAT表区记录数据区存储情况,文件信息,也可以通过遍历fat表区查询剩余容量信息。数据区存储文件数据,以簇的方式管理
19、gcc的目标文件的依赖的.h文件也要加上,不然头文件的更改检测不到,依然是最新的:
main.o:main.c hello.h
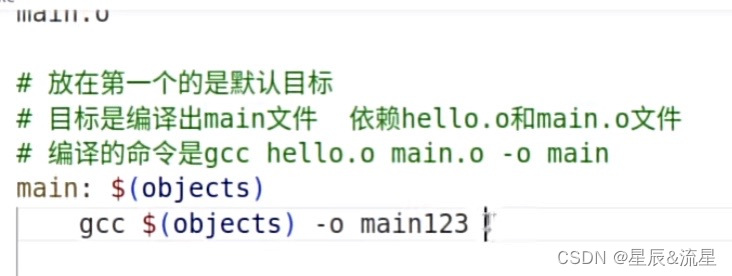
如果目标文件和gcc编译后的文件名不一样,生成的文件名是gcc的,但是makefile检查的是目标文件main,如果文件有改动也检查不到
20、malloc不能在中断中调用:分配时间不确定,会调用到互斥锁,互斥锁基于任务调度器和优先级反转。有可能造成任务获取到了锁,中断获取不到,会卡死。
21、printf:数据一般放到缓冲区,不建议中断使用,执行时间较长。线程不安全,一般是没有锁机制,(sprintf等接口是有锁机制,线程安全)中断调用可能输出发生错误。
22、C语言中,int a[10] = {1};数组的第一个元素初始化为1,如果是全局变量或者静态变量,其余元素(a[1] 到 a[9])则肯定是初始化为0,如果是局部变量,一般也会初始化为0(也有少数编译器不会对后面9个元素做初始化)。如果定义局部变量数组,不初始化,栈空间可能会是随机值。
23、32位的CPU,数据总线也是32位,每次读取四个字节。因为读取效率的原因,CPU一般都会四字节对齐。数据总线读取时,地址一般都是4的倍数。如果全局变量定义的是1字节,实际占用的内存大小可能是1~4字节。编译器可能会进行优化,例如将多个小的全局变量打包到一个更大的内存块中,以减少内存碎片和提高访问效率。
24、文件打开
1)读模式:在大多数情况下,如果一个文件以读模式被打开且未被关闭,再次以读模式打开该文件通常是允许的。每次打开都会获得一个新的文件描述符(file descriptor),这些描述符各自独立,维护着各自的文件状态信息(如文件偏移量)。
2)写模式:写模式通常是独占的,这意味着如果一个文件以写模式被打开且未被关闭,再次尝试以写模式(或读写模式)打开该文件可能会失败,具体取决于操作系统的实现。然而,在某些操作系统和配置下,可能允许以追加模式(append mode)同时打开文件进行写入,而不会相互干扰。
3)其中一个地方关闭close文件,不影响其他地方的打开,文件描述符都是独立的。
25、ARM 架构的中断处理流程
当中断请求(IRQ)发生时,会首先停止当前任务,执行中断,ARM 架构的中断处理流程如下:
1)硬件中断请求:外设(如网卡、定时器等)向中断控制器(如 GIC)发送中断信号(可能是高低电平或者下降沿等信号);
2)中断控制器处理:GIC 接收中断信号,进行优先级仲裁,并将中断信号路由到目标 CPU;
3)CPU 响应中断:CPU 收到中断信号后,保存当前程序状态(如 PC、PSTATE 等),并将处理器状态切换到中断模式(如 IRQ 模式);
4)跳转到中断向量表:CPU 根据中断向量表(存储在 VBAR_EL1 指定的地址)找到对应的中断处理入口地址;
5)执行中断处理程序:中断处理程序(ISR)开始执行,通常由内核提供的通用中断处理框架(如gic_handle_irq)读取中断号,并调用具体的设备驱动中断处理函数;
6)中断处理完成:中断处理程序执行完毕后,通过 ERET 指令恢复中断前的状态,继续执行被中断的任务;
示例:网卡中断处理
以下是一个典型的网卡中断处理流程:
1)硬件触发:网卡接收数据包后,向 GIC 发送中断信号。
2)中断处理:GIC 路由中断到 CPU,CPU 跳转到中断处理程序,执行网卡驱动的 ISR。
3)下半部处理:ISR 读取网卡状态,清除中断标志,并触发 SoftIRQ 或 Tasklet。
4)数据传递:SoftIRQ 或 Tasklet 处理数据包,并通过 sk_buff 将数据传递到网络协议栈。
5)用户空间回调:协议栈将数据包传递到用户空间,应用层通过套接字接口接收数据
26、在单CPU上,多线程执行不存在运行时内存乱序访问,但是可能存在缓存一致问题;
内存屏障是一种硬件指令,用于确保特定的内存操作在执行时的顺序性和可见性。它用于防止编译器和处理器对内存访问指令进行重排序,确保某些操作在内存屏障之前完成,之后的操作不会被提前执行。
volatile是C语言关键字,用于告诉编译器,被修饰的变量可能会被程序之外的其他因素(如硬件、中断、其他线程等)修改。因此,编译器在优化时不能假设该变量的值不会改变,必须每次直接从内存中读取或写入该变量。
27、AMP与SMP的区别
AMP(Asymmetric Multi-Processing,非对称多处理)
SMP(Symmetric Multi-Processing,对称多处理)
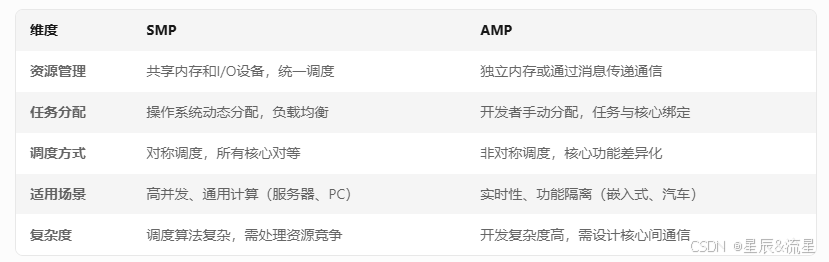
AMP的各处理器可能是不同的架构,比如ARM+RISC-V,一般每个核有自己的操作系统。SMP一般是一个操作系统来调度。
28、文件系统元数据
元数据的组成
• 文件属性:包括文件名、大小、类型、创建时间、修改时间等基本信息。
• 文件位置信息:记录文件在存储设备上的物理位置,如文件起始块号、块分布等。
• 文件系统结构信息:包括文件系统的超级块、inode表、块位图等关键数据结构。
• 访问权限和所有权信息:文件和目录的访问权限、所属用户和用户组等。
• 其他相关信息:如文件的扩展属性、安全标签等。



















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











