







调参
num_leaves和max_depth
num_leaves这是控制树模型复杂度的主要参数. 理论上, 借鉴 depth-wise 树, 我们可以设置num_leaves = 2^(max_depth)但是, 这种简单的转化在实际应用中表现不佳. 这是因为, 当叶子数目相同时, leaf-wise 树要比 depth-wise 树深得多, 这就有可能导致过拟合. 因此, 当我们试着调整 num_leaves 的取值时, 应该让其小于 2^(max_depth). 举个例子, 当 max_depth=6 时(这里译者认为例子中, 树的最大深度应为7), depth-wise 树可以达到较高的准确率.但是如果设置 num_leaves 为 127 时, 有可能会导致过拟合, 而将其设置为 70 或 80 时可能会得到比 depth-wise 树更高的准确率. 其实, depth 的概念在 leaf-wise 树中并没有多大作用, 因为并不存在一个从 leaves 到 depth 的合理映射.
min_data_in_leaf和min_sum_hessian_in_leaf
-
min_data_in_leaf这是处理 leaf-wise 树的过拟合问题中一个非常重要的参数. 它的值取决于训练数据的样本个树和num_leaves将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合. 实际应用中, 对于大数据集, 设置其为几百或几千就足够了. 你也可以利用max_depth来显式地限制树的深度. -
min_sum_hessian_in_leafdefault = 1e-3, type = double, aliases: min_sum_hessian_per_leaf, min_sum_hessian, min_hessian, min_child_weight, constraints: min_sum_hessian_in_leaf >= 0.0
monotonic constraints单调约束
- It is often the case in a modeling problem or project that the functional form of an acceptable model is constrained in some way. This may happen due to business considerations, or because of the type of scientific question being investigated. In some cases, where there is a very strong prior belief that the true relationship has some quality, constraints can be used to improve the predictive performance of the model. A common type of constraint in this situation is that certain features bear a monotonic relationship to the predicted response:
group_column和ignore_column
-
group_columndefault = “”, type = int or string, aliases: group, group_id, query_column, query, query_id used to specify the query/group id column use number for index, e.g. query=0 means column_0 is the query id add a prefix name: for column name, e.g. query=name:query_id
Note: works only in case of loading data directly from file
Note: data should be grouped by query_id, for more information, see Query Data
Note: index starts from 0 and it doesn’t count the label column when passing type is int, e.g. when label is column_0 and query_id is column_1, the correct parameter is query=0 -
ignore_columndefault = “”, type = multi-int or string, aliases: ignore_feature, blacklist
used to specify some ignoring columns in training
use number for index, e.g. ignore_column=0,1,2 means column_0, column_1 and column_2 will be ignored
add a prefix name: for column name, e.g. ignore_column=name:c1,c2,c3 means c1, c2 and c3 will be ignored
Note: works only in case of loading data directly from file
Note: index starts from 0 and it doesn’t count the label column when passing type is int
Note: despite the fact that specified columns will be completely ignored during the training, they still should have a valid format allowing LightGBM to load file successfully
categorical_feature
categorical_feature, default = “”, type = multi-int or string, aliases: cat_feature, categorical_column, cat_column used to specify categorical features
use number for index, e.g. categorical_feature=0,1,2 means column_0, column_1 and column_2 are categorical features add a prefix name: for column name, e.g. categorical_feature=name:c1,c2,c3 means c1, c2 and c3 are categorical features
Note: only supports categorical with int type (not applicable for data represented as pandas DataFrame in Python-package)
Note: index starts from 0 and it doesn’t count the label column when passing type is int
Note: all values should be less than Int32.MaxValue (2147483647)
Note: using large values could be memory consuming. Tree decision rule works best when categorical features are presented by consecutive integers starting from zero
Note: all negative values will be treated as missing values
Note: the output cannot be monotonically constrained with respect to a categorical feature
lambda_l1和lambda_l2
xbgoost中参数正则项包含叶子数和叶子权重
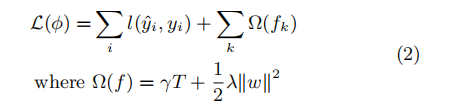
正则化项L1和L2的区别
bagging_fraction和bagging_freq
-
bagging_fraction, default = 1.0, type = double, aliases: sub_row, subsample, bagging, constraints: 0.0 < bagging_fraction <= 1.0
like feature_fraction, but this will randomly select part of data without resampling
can be used to speed up training
can be used to deal with over-fitting
Note: to enable bagging, bagging_freq should be set to a non zero value as well -
bagging_freq, default = 0, type = int, aliases: subsample_freq
frequency for bagging
0 means disable bagging; k means perform bagging at every k iteration. Every k-th iteration, LightGBM will randomly select bagging_fraction * 100 % of the data to use for the next k iterations
Note: to enable bagging, bagging_fraction should be set to value smaller than 1.0 as well -
feature_fraction, default = 1.0, type = double, aliases: sub_feature, colsample_bytree, constraints: 0.0 < feature_fraction <= 1.0
LightGBM will randomly select a subset of features on each iteration (tree) if feature_fraction is smaller than 1.0. For example, if you set it to 0.8, LightGBM will select 80% of features before training each tree
can be used to speed up training
can be used to deal with over-fitting
关于类别特征 Categorical Feature Support
- LightGBM offers good accuracy with integer-encoded categorical features. LightGBM applies Fisher (1958) to find the optimal split over categories as described here. This often performs better than one-hot encoding.
- Use categorical_feature to specify the categorical features. Refer to the parameter categorical_feature in Parameters.
- Categorical features must be encoded as non-negative integers (int) less than Int32.MaxValue (2147483647). It is best to use a contiguous range of integers started from zero.
- Use min_data_per_group, cat_smooth to deal with over-fitting (when #data is small or #category is large).
- For a categorical feature with high cardinality (#category is large), it often works best to treat the feature as numeric, either by simply ignoring the categorical interpretation of the integers or by embedding the categories in a low-dimensional numeric space.
lambdaRank label
- The label should be of type int, such that larger numbers correspond to higher relevance (e.g. 0:bad, 1:fair, 2:good, 3:perfect).
- Use label_gain to set the gain(weight) of int label.
- Use lambdarank_truncation_level to truncate the max DCG.
可以用label_gain设置标签的增益,增益数值的设定是一个待研究的问题
- label_gain , default = 0,1,3,7,15,31,63,…,2^30-1, type = multi-double
- used only in lambdarank application
- relevant gain for labels. For example, the gain of label 2 is 3 in case of default label gains separate by
,
调参
学习率和迭代次数
先把学习率先定一个较高的值,取 learning_rate = 0.1,然后通过cross valid和early_stopping_round计算最佳迭代次数
n_estimators/num_iterations/num_round/num_boost_round。我们可以先将该参数设成一个较大的数,然后在cv结果中查看最优的迭代次数,具体如代码。
通过early_stopping_round(如果一次验证数据的一个度量在最近的early_stopping_round 回合中没有提高,模型将停止训练)
可以设置cv的返回:模型或者评估结果,评估结果类似{'ndcg@10-mean':[, , , ], 'ndcg@10-stdv':[, , , ]}
max_depth和num_leaves
max_bin和min_data_in_leaf
feature_fraction bagging_fraction bagging_freq
lambda_l1和lambda_l2
monotonic constraints
learning_rate
特征重要性
代码
class GridSearch(object):
def __init__(self):
self.gbm = None
self.optimal_params = {}
def grid_search(self, grids, paral=False, is_print=True):
"""一组参数搜索 girds:{feature_name:[]}"""
res_d = {}
grid_l = list(grids.items())
params.update(self.optimal_params)
# 特征并行,暂时用不到
if paral:
pass
# 特征自由组合
else:
# 所有可能的参数组合
param_l = [[x] for x in grid_l[0][1]] # 初始化第一个参数
for i in range(1, len(grid_l)):
param_l = [l + [p] for l in param_l for p in grid_l[i][1]]
name_l = [tup[0] for tup in grid_l]
for i in range(len(param_l)):
_d = dict(zip(name_l, param_l[i]))
params_copy = params.copy()
params_copy.update(_d)
# k = 'lambda_l1: 0.001,lambda_l2: 0.1'
k = ','.join([str(tup[0]) + ": " + str(tup[1]) for tup in zip(name_l, param_l[i])])
print("第{}个组合:{}".format(i, k))
self.gbm = lgb.train(params_copy, train_data, num_boost_round=400, valid_sets=[valid_data],
early_stopping_rounds=40, verbose_eval=20)
res_d[k] = (self.gbm.best_score['valid_0']['ndcg@10'], self.gbm.best_score['valid_0']['ndcg@40'])
# [(k,(ndcg@10, ndcg@30))] k = 'lambda_l1: 0.001,lambda_l2: 0.1'
ndcg_10 = sorted(res_d.items(), key=lambda kv: kv[1][0], reverse=True)
self.optimal_params.update(dict([x.split(': ') for x in ndcg_10[0][0].split(',')]))
print(self.optimal_params)
ndcg_40 = sorted(res_d.items(), key=lambda kv: kv[1][1], reverse=True)
if is_print:
for k, v in ndcg_10:
print(k, v)
print("-" * 40)
for k, v in ndcg_40:
print(k, v)
return ndcg_10, ndcg_40
def all_parameters_search(self, grids_l):
"""自动化搜索所有可能的参数组"""
# with open('train_record', 'w') as f:
for grids in grids_l:
# grids.update(self.optimal_params) # update上一步的最优参数
ndcg_10, ndcg_30 = self.grid_search(grids, paral=False, is_print=False)
for k, v in ndcg_10:
print('{}\t{},{}\n'.format(k, v[0], v[1]))
for k, v in ndcg_30:
print('{}\t{},{}\n'.format(k, v[1], v[0]))
print("-" * 40 + '\n')
print(self.optimal_params)
def print_feature_importance(self):
"""打印特征的重要度
"""
importances = self.gbm.feature_importance(importance_type='split')
feature_names = self.gbm.feature_name()
sum = 0.
for value in importances:
sum += value
name_impo = sorted(list(zip(feature_names, importances)), key=lambda x: x[1], reverse=True)
for name, impo in name_impo:
print('{} : {} : {}'.format(name, impo, impo / sum))
grids_l = [
# {'max_depth': list(range(3, 8, 1)), 'num_leaves': list(range(5, 100, 5))},
# {'max_bin': list(range(5, 256, 10)), 'min_data_in_leaf': list(range(50, 1001, 50))},
{'feature_fraction': [0.6, 0.7, 0.8, 0.9, 1.0], 'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 1.0], 'bagging_freq': range(0, 81, 10)},
{'lambda_l1': [1e-5, 1e-3, 1e-1, 0.0, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0], 'lambda_l2': [1e-5, 1e-3, 1e-1, 0.0, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0]},
{'min_split_gain': [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]},
{'learning_rate': [0.01, 0.03, 0.05, 0.07, 0.1, 0.3, 0.5, 0.7, 1.0]}
]
if __name__ == "__main__":
t = int(sys.argv[1])
# t = 1
# categorical_feature='name:u_fs,up_sex'会报错,因为没有输入feature names
train_data = lgb.Dataset("data/train.csv", categorical_feature=[18, 31], free_raw_data=False)
valid_data = lgb.Dataset("data/valid.csv", categorical_feature=[18, 31], free_raw_data=False)
if t == 0:
cv_res = lgb.cv(params, train_data, num_boost_round=1000, nfold=5, stratified=False, early_stopping_rounds=50)
print("iteration num: {}".format(len(cv_res['ndcg@10-mean'])))
print("ndcg@10:{} ndcg@40: {} ".format(max(cv_res['ndcg@10-mean']), max(cv_res['ndcg@40-mean'])))
elif t == 1: # grid search
gs = GridSearch()
gs.grid_search({'learning_rate': [0.01, 0.03, 0.05, 0.07, 0.1, 0.3, 0.5, 0.7, 1.0]})
gs.print_feature_importance()
elif t == 2:
gs = GridSearch()
gs.all_parameters_search(grids_l)
启动日志,多关注一下,涉及到参数的设置
主要包含:
- 参数的设置,通常会有一些警告
- 数据的整体分析,rank里,类别数、query数、每个query的平均数据等等
[LightGBM] [Info] Construct bin mappers from text data time 0.33 seconds
[LightGBM] [Debug] Number of queries in train3.csv: 118403. Average number of rows per query: 33.868660.
[LightGBM] [Debug] Dataset::GetMultiBinFromSparseFeatures: sparse rate 0.769392
[LightGBM] [Debug] Dataset::GetMultiBinFromAllFeatures: sparse rate 0.492899
[LightGBM] [Debug] init for col-wise cost 0.265492 seconds, init for row-wise cost 0.571826 seconds
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.318483 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Debug] Using Sparse Multi-Val Bin
[LightGBM] [Info] Total Bins 5951
[LightGBM] [Info] Number of data points in the train set: 4010151, number of used features: 31
gbm常用属性
gbm = lgb.train(params, train_data, num_boost_round=400, valid_sets=[valid_data])
gbm.best_score
>>> defaultdict(<class 'collections.OrderedDict'>, {'valid_0': OrderedDict([('ndcg@10', 0.49198254166476096), ('ndcg@30', 0.5681340145051615)])})
predict
预测时,是否有query列不影响最终计算结果
>>>ypred4 = gbm.predict('test4.csv',data_has_header=True)
[LightGBM] [Warning] Feature (sid) is missed in data file. If it is weight/query/group/ignore_column, you can ignore this warning.
>>>ypred4[:10]
array([ 0.54267792, 0.39272917, 0.31842769, 0.10324354, -0.05312303,
0.10855625, 0.0766676 , 0.1336972 , 1.57561062, 0.14458557])
LightGBM的参数详解以及如何调优
LightGBM调参笔记
部署
https://zhuanlan.zhihu.com/p/265888201















 9810
9810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









