







时间序列分析python实践
题目
03年到19年第一季度分季度的数据,13年之前只有传统汽车的销量,13年之后是传统汽车+新能源汽车的销量,需要预测未来三期传统汽车的销量
分析过程
# 数据处理
df = pd.read_excel(r'D:\统计学python实践\时序数据.xlsx',index_col=0)
# 将index的name取消
df.index.name = None
df.reset_index(inplace=True)
df.drop(df.index[64], inplace=True)
# # 把一个时间字符串解析为时间元组
start = datetime.datetime.strptime("2003-01", "%Y-%m")
date_list = [start + relativedelta(months=x*3) for x in range(0, 64)] # 从2003-01-01开始逐月增加组成list
df['index'] = date_list
df.set_index(['index'], inplace=True)
## 观察趋势
dta = np.array(df['传统汽车销量'], dtype=np.float)
# 生成时间序列并画图
dta = pd.Series(dta)
dta.index = df.index
# 趋势
dta.plot(figsize=(12, 8), title='Monthly Total Traditional Car')

图像显示传统汽车销量有明显的递增趋势,判断为非平稳的,再观察是否为季节性的
decomposition = seasonal_decompose(df['传统汽车销量'], freq=12)
fig = plt.figure()
fig = decomposition.plot()
fig.set_size_inches(15, 8)

可以看到有明显季节性波动,需要将数据平稳化,这里我用简单的二阶差分进行(这里可以配合季节性差分进行测试(shift(12) ),最终选择差分方式)
fig = plt.figure(figsize=(12, 8))
ax2 = fig.add_subplot(111)
diff2 = dta.diff(2)
diff2.plot(ax=ax2)

可以看到效果还可以。基础上还可以进行根检验:
sm.tsa.stattools.adfuller(diff2[2:]
寻找最优p,q值组合:
arma_mod70 = sm.tsa.ARMA(dta, (7, 0)).fit()
print(arma_mod70.aic, arma_mod70.bic, arma_mod70.hqic)
arma_mod30 = sm.tsa.ARMA(dta, (0, 1)).fit()
print(arma_mod30.aic, arma_mod30.bic, arma_mod30.hqic)
arma_mod80 = sm.tsa.ARMA(dta, (8, 0)).fit()
print(arma_mod80.aic, arma_mod80.bic, arma_mod80.hqic)
结果如下:

可以看出ARMA(8,0) 和ARMA(7,0) 是差不多的 ,这里选择两个对结果没有太大影响。
预测:
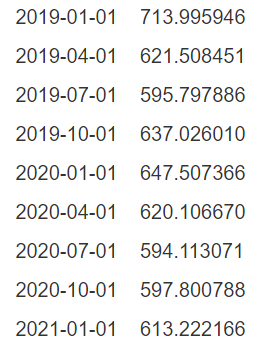
predict_dta = arma_mod80.predict('2019', '2021', dynamic=True)
print(predict_dta)
fig, ax = plt.subplots(figsize=(12, 8))
ax = dta.ix['2000':].plot(ax=ax)
fig = arma_mod80.plot_predict('2019', '2021', dynamic=True, ax=ax, plot_insample=False)
预测结果:
















 3983
3983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









