







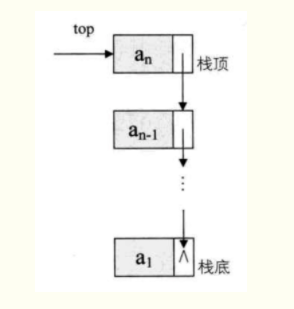
栈也是一种线性表,只不过它是操作受限的线性
表,只能在一端操作。 进出的一端称为栈顶(top),另一端称为栈底(base)。
栈可以用顺序存储,也可以用链式存储。
栈的顺序存储

其中,base 指向栈底,top 指向栈顶。
注意:栈只能在一端操作,后进先出,这是栈的关键特征,也就是说不允许在中间查找、取值、插入、删除等
操作,我们掌握好顺序栈的初始化、入栈,出栈,取栈顶元素等操作即可。
栈的初始化

入栈
入栈操作:判断是否栈满,如果栈已满,则入栈失败,否则将元素放入栈顶,栈顶指针向上移动一个空间(top++)。

出栈
出栈操作: 和入栈相反,出栈前要判断是否栈空,如果栈是空的,则出栈失败,否则将栈顶元素暂存给一个变
量,栈顶指针向下移动一个空间(top--)。
空栈
空栈条件 :S.top ==S.base
栈满
栈满条件 :S.top-S.base=MAXSIZE
算法实现
// 栈stack.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
// Author:See QQ3492625357 添加請説明是CSDN上加的
#include <iostream>
#define MAXSIZE 128 //栈的空闲大小
typedef struct _SqStack
{
int *top;//栈顶指针
int *base;//栈底指针
}SqStack;
//初始化栈
bool InitStack(SqStack &S)
{
S.base = new int[MAXSIZE];
if (!S.base) return false;
S.top = S.base;//空栈
return true;
}
//入栈
bool PushStack(SqStack &S,int e)
{
if (S.top-S.base==MAXSIZE) return false;//栈满
*(S.top++) = e;
return true;
}
//出栈
bool PopStack(SqStack &S,int &e)
{
if (S.base == S.top) return false;//栈空
e = *(--S.top);
return true;
}
//获取栈顶元素
int GetTop(SqStack S)
{
if (S.base == S.top) return -1;
return *(S.top - 1);
}
bool IsEmpty(SqStack &S)
{
if (S.top == S.base)
return true;
else
return false;
}
int main()
{
SqStack S;
InitStack(S);
//入栈
for (int i = 0; i < 5; i++)
PushStack(S, i);
//出栈 :后进先出
int e;
for (int i = 0; i < 5; i++)
{
PopStack(S, e);
std::cout << e << " ";
}
std::cout<<std::endl;
}
栈的链式存储
注:以下内容转自博客园,有修改。 原文链接为:https://www.cnblogs.com/muzijie/p/5647022.html
栈的链式存储结构,简称链栈。
由于栈只是栈顶在做插入和删除操作,所以栈顶应该放在单链表的头部。另外,都有了栈顶在头部了,单链表中的头结点也就失去了意义,通常对于链栈来说,是不需要头结点的。
对于链栈来说,基本不存在栈满的情况,除非内存已经没有使用空间了。
对于空栈来说,链表原来的定义是头指针指向空,那么链栈的空其实就是top=NULL。
typedef struct StackNode
{
SElemType data;
Struct StackNode *next;
StackNode;
typedef struct StackNode *LinkStackPtr;
typedef struct LinkStack
{
LinkStackPtr top;
int count;
}LinkStack;进栈
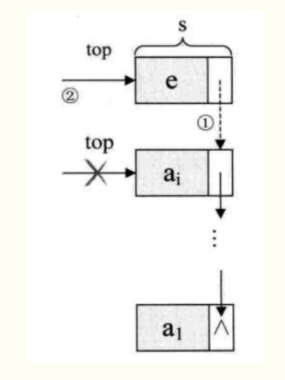
Status push(LinkStack *S, SElemType e) {
LinkStackPtr node = new StackNode ;
node->data = e;
node->next = S->top;
S->top = node;
S->count ++;
return OK;
}出栈
Status pop(LinkStack *S, SElemType *e) {
LinkStackPtr p;
if (S->top == NULL) {
return ERROR;
}
*e = S->top->data;
p = S->top;
S->top = S->top->next;
S->count --;
delete p; //释放结点p
return OK;
}顺序栈和链栈的选择
顺序栈和链栈的时间复杂度都为O(1). 如果栈的使用过程中元素变化不可预期,有时会很大,有时会很小,则选择使用链栈。反之,如果它的变化在可控范围内,选择使用顺序栈比较好。















 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











