









针对Spark Streaming我们主要讲一些基本的使用,因为目前在实时计算领域,Flink的应用场景会更多。
一、Spark Streaming
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。
但是注意:这个实时属于近实时,最小可以支持秒级别的实时处理。
二、SparkStreaming工作原理
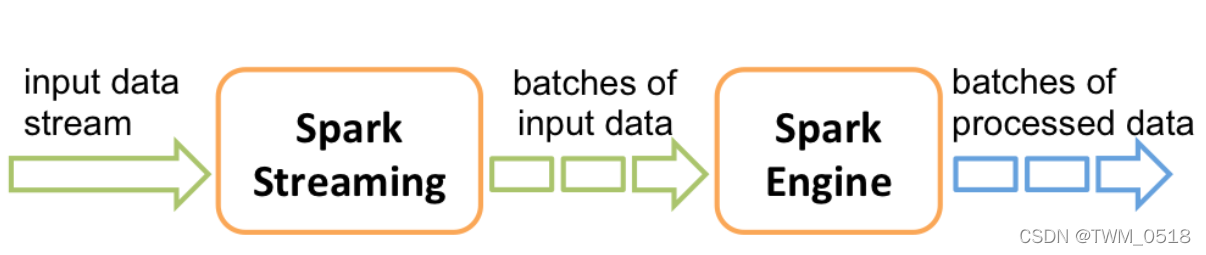
Spark Streaming的工作原理是这样的:
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
三、实时WordCount程序开发
下面我们来开发一个Spark Streaming 的实时WordCount程序感受一下
创建db_sparkstreaming项目
添加spark streaming的maven依赖
注意:由于目前我们下载的spark的安装包中使用的scala是2.11的,所以在这里要选择对应的scala 2.11版本的

 订阅专栏 解锁全文
订阅专栏 解锁全文















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











