









CNN卷积神经网络介绍
在神经网络中,卷积神经网络(ConvNets或CNNs)是进行图像识别、图像分类的主要类别之一。物体探测、人脸识别等是CNNs应用最广泛的领域之一。
CNN图像分类采用一个输入图像,对其进行处理,并将其分类到特定的类别中,其包含了一个由卷积层和子采样层(池化层)构成的特征抽取器。计算机将输入图像视为像素阵列,它取决于图像的分辨率,可以看到h*w *d(h =高度,w =宽度,d =尺寸)。
例如,一幅6x6x3矩阵阵列的RGB图像(3指RGB值)和一幅4x4x1矩阵阵列的灰度图像。
深度学习CNN模型进行训练和测试,每个输入图像都将通过一系列带有过滤器(Kernals)、池化、全连接层(FC)的卷积层,并应用Softmax函数对概率值在0到1之间的对象进行分类。下图是CNN处理输入图像的完整流程,并根据值对对象进行分类。
1、ANN/CNN/RNN是什么?
1)多层感知器Multi-Layer Perceptron (MLP) /人工神经网络Artificial Neural Networks (ANN)
(1)随着图像尺寸的增大,可训练参数的数量会急剧增加
(2)MLP会丢失图像的空间特征。
2)卷积神经网络Convolution Neural Networks (CNN)
卷积神经网络(CNN)目前在深度学习领域非常热门。这些CNN模型被应用于不同的应用和领域,在图像和视频处理项目中尤其普遍。
3)循环神经网络Recurrent Neural Networks (RNN)
RNN在隐藏状态上有一个循环连接,此循环约束能够确保在输入数据中捕捉到顺序信息。
优势:RNN能够捕捉数据中出现的顺序信息,例如,预测时文本中单词之间的依赖关系
(它们构成了深度学习中大多数预训练模型的基础:事实上,不论是哪种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别。)
2、CNN(卷积神经网络)简介
CNN由输入和输出层以及多个隐藏层组成,隐藏层可分为卷积层,池化层、RELU层和全连通层。
卷积网络的核心思想是将:局部感受野、权值共享以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。。
这里主要讨论CNN相比与传统的神经网络的不同之处,CNN主要有三大特色,分别是局部感知、权重共享和多卷积核
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络执行的是有导师训练,所以其样本集是由形如:(输入向量,理想输出向量)的向量对构成的。所有这些向量对,都应该是来源于网络即将模拟的系统的实际“运行”结果。它们可以是从实际运行系统中采集来的。在开始训练前,所有的权都应该用一些不同的小随机数进行初始化。“小随机数”用来保证网络不会因权值过大而进入饱和状态,从而导致训练失败;“不同”用来保证网络可以正常地学习。实际上,如果用相同的数去初始化权矩阵,则网络无能力学习
2.1输入层
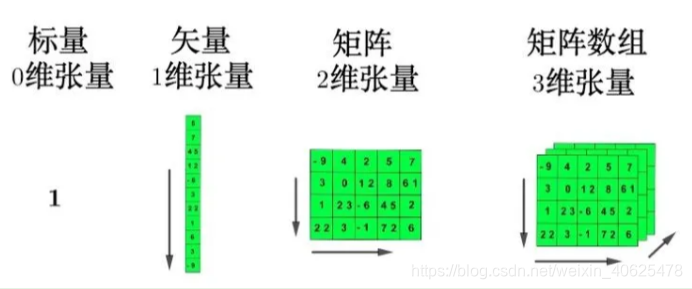
一个标量(一个数字)有0维,一个向量有1维,一个矩阵有2维,一个张量有3维或更多。但是,为了简单起见,我们通常也称向量和矩阵为张量。CNN的输入一般是二维向量,可以有高度,比如,RGB图像;
在深度学习中,张量无处不在。嗯,谷歌的框架被称为TensorFlow是有原因的,那到底什么是张量?
张量
张量(tensor)是多维数组,目的是把向量、矩阵推向更高的维度。
2.2隐含层
2.2.1卷积层
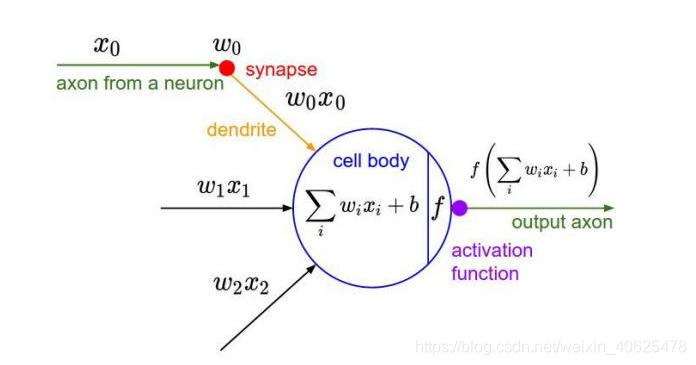
卷积是从输入图像中提取特征的第一层。它是一个数学运算,需要两个输入,如图像矩阵和一个滤波器(或核)。这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,得到这些小区域的特征值,从而保持像素之间的关系。
卷积层是CNN的核心,层的参数由一组可学习的滤波器(filter)或内核(kernels)组成,它们具有小的感受野,延伸到输入容积的整个深度。 在前馈期间,每个滤波器对输入进行卷积,计算滤波器和输入之间的点积,并产生该滤波器的二维激活图(输入一般二维向量,但可能有高度(即RGB))。 简单来说,卷积层是用来对输入层进行卷积,提取更高层次的特征。
2.2.2 激活层(ReLU)
把卷积层输出结果做非线性映射。
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
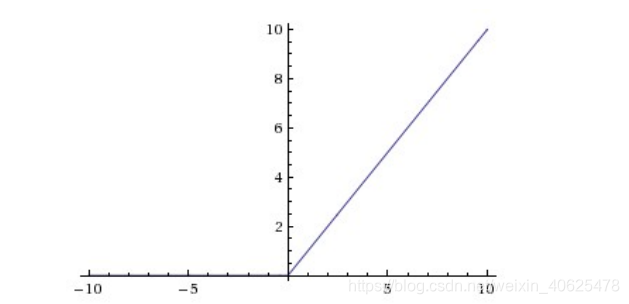
这个RELU我们之前讲过,全名将修正线性单元,是神经元的激活函数,对输入值x的作用是max(0,x),当然RELU只是一种选择,还有选Leak-Relu等等,一般都是用Relu!
2.2.3池化层 (Pooling)
当图像太大时,池化图层部分会减少参数的数量。空间汇聚也称为次采样或下采样,它降低了图像的维度,但保留了重要的信息。Pooling可以有不同的类型:
Max Pooling
Average Pooling
Sum Pooling Max pooling顾名思义就是从校正后的feature map中取最大的元素。Average Pooling 取的是平均值,而Sum Pooling取的是总和;
最常见的池化层是规模为2*2, 步幅为2,对输入的每个深度切片进行下采样。每个MAX操作对四个数进行,如下图所示:
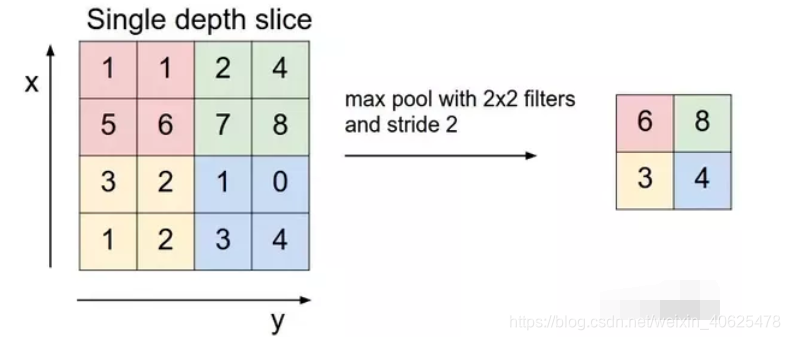
池化操作将保存深度大小不变。如果池化层的输入单元大小不是二的整数倍,一般采取边缘补零(zero-padding)的方式补成2的倍数,然后再池化。
之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
1)池化层相比卷积层可以更有效的降低数据维度,缩小图像的规模,提升计算速度。
2)这些统计特征能够有更低的维度,减少计算量;这么做不但可以大大减少运算量,不容易过拟合,当参数过多的时候很容易造成过度拟合。
2.2.4全连接层
对于任意一个卷积层,要把它变成全连接层只需要把权重变成一个巨大的矩阵,其中大部分都是0 除了一些特定区块(因为局部感知),而且好多区块的权值还相同(由于权重共享)。我们称这一层为FC层,我们将矩阵平铺成向量,并将其作为一个完全连接的层,就像一个神经网络。
这个层就是一个常规的神经网络,它的作用是对经过多次卷积层和多次池化层所得出来的高级特征进行全连接(全连接就是常规神经网络的性质),算出最后的预测值。
全连接层和卷积层可以相互转换:
2.2.5参数减少与权值共享
尽管局部感知使计算量减少了几个数量级,但权重参数数量依然很多。能不能再进一步减少呢?方法就是权值共享。
权值共享:不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权值参数。
卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
3、卷积神经网络的优点
在这里介绍一下深度学习入门课程,也是小编学习的一种,吴恩达老师的深度学习课程神经网络和深度学习
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。
流的分类方式几乎都是基于统计特征的,这就意味着在进行分辨前必须提取某些特征。然而,显式的特征提取并不容易,在一些应用问题中也并非总是可靠的。卷积神经网络,它避免了显式的特征取样,隐式地从训练数据中进行学习。这使得卷积神经网络明显有别于其他基于神经网络的分类器,通过结构重组和减少权值将特征提取功能融合进多层感知器。它可以直接处理灰度图片,能够直接用于处理基于图像的分类。
卷积网络较一般神经网络在图像处理方面有如下优点: a)输入图像和网络的拓扑结构能很好的吻合;b)特征提取和模式分类同时进行,并同时在训练中产生;c)权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。
卷积神经网络之训练算法
1. 同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
2. 找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
卷积神经网络之优缺点
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
引用文章链接:
http://yann.lecun.com/exdb/lenet/weirdos.html
https://www.cnblogs.com/duanhx/p/9655223.html


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











