







- 概述
- 样例数据集及模拟数据生成函数
- 分类
- 回归分析
- 聚类
- 模型评价与优化
- 数据预处理
人工智能(Artificial Intelligence,简称AI)、机器学习(Machine Learning,简称ML)以及深度学习(Deep Learning,简称DL)是当前热门的三个名词,这三者之间既有一定联系,也有明显的区别。
人工智能是指利用计算机去做以前只有人才能做的智能工作,目标是希望机器能像人类一样去思考问题、解决问题,甚至比人类做的更好。
机器学习是人工智能的一个分支,也称为统计机器学习,其基本思想是基于数据构建统计模型,并利用模型对数据进行分析和预测的一门科学。
深度学习是基于多层神经网络的机器学习方法,是特殊的机器学习实现方法。
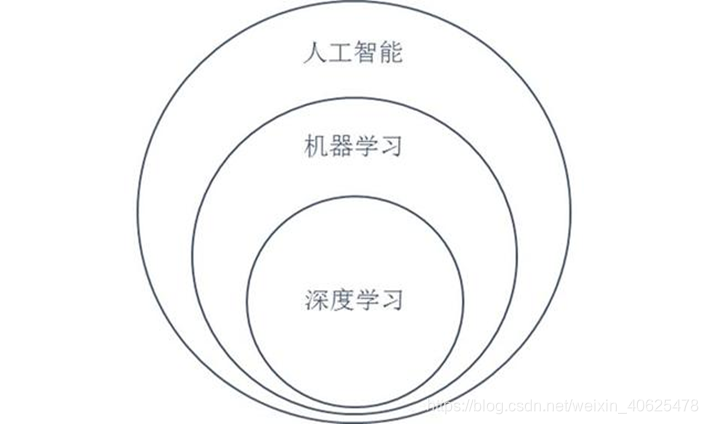
人工智能、机器学习和深度学习关系图
机器学习的模型分为回归模型和分类模型。
回归模型得到的结果是连续值,如预测明天的温度。
分类模型得到的结果是离散值,如预测明天天气(阴、晴、雨)。
回归模型可以转换为分类模型,如根据预测的温度确定是否是高温天气;分类问题也可以通过回归模型来预测,如某个事件出现的概率。
机器学习的过程可概括为:
- 组织数据,即按要求对数据进行处理,转换成特定的格式。
- 建立模型,即利用样本数据进行算法学习,得到预测模型。
- 预测结果,即根据模型对输入数据的结果进行预测,根据预测结果,还可以进一步评价和调整模型
机器学习的方法可以分为监督学习和非监督学习两大类。
监督学习是有训练样本,根据训练样本的特征(属性)信息和结果信息对算法进行训练,然后利用训练后的算法对输入数据进行分类或回归。
非监督学习没有训练样本,是直接根据输入样本的特征(属性)信息对样本进行聚类,非监督学习也称为聚类。
1.2scikit-learn
scikit-learn是一个用于机器学习的python包,是在Numpy、Scipy和Matplotlib三个模块基础上编写的,最初是包含在Scipy中。

scikit-learn官方网站(http://scikit-learn.org/stable/)
scikit-learn主要有6大功能:
分类(Classification)
回归分析(Regression)
聚类(Clustering)
降维(Dimensionality reduction)
模型选择(Model selection)
数据预处理(Preprocessing)
scikit-learn包括了大量模型,如涉及分类的模型包括决策树、SVM、KNN、朴素贝叶斯、随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees等。
用户需要根据数据特征和任务目标选择合适的模型。
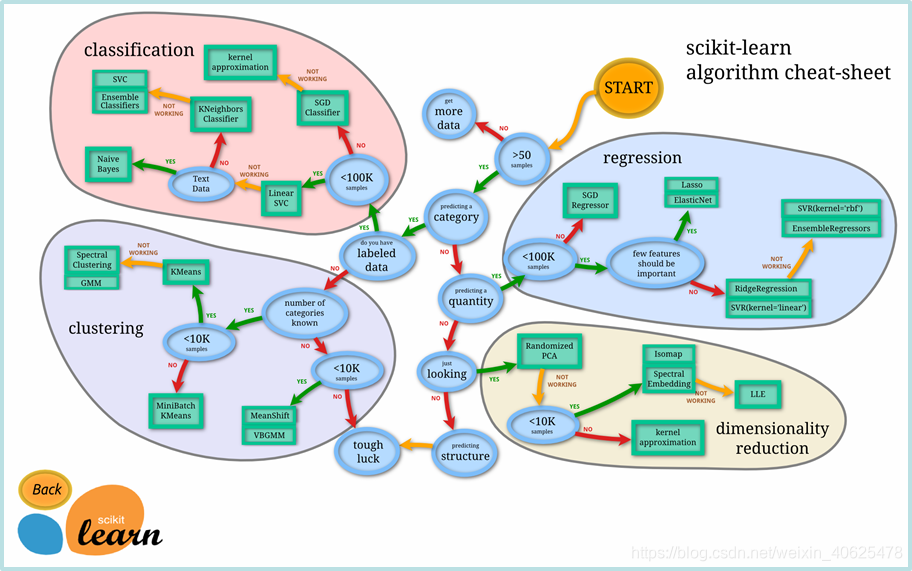
根据数据特征和任务目标选择模型
scikit-learn包的名称是sklearn,包里有很多模块(子包),在应用时,通常是根据需要导入相应的模块,如:from sklearn.cluster import DBSCAN该语句是从cluster子包中导入DBSCAN模块。
2. 样例数据集及模拟数据生成函数
scikit-learn包中包含了一些样例数据集用于机器学习实验,包括:
iris(鸢尾花)数据集
digits(手写数字)数据集
Boston房价数据集
Diabetes(糖尿病)数据集
……
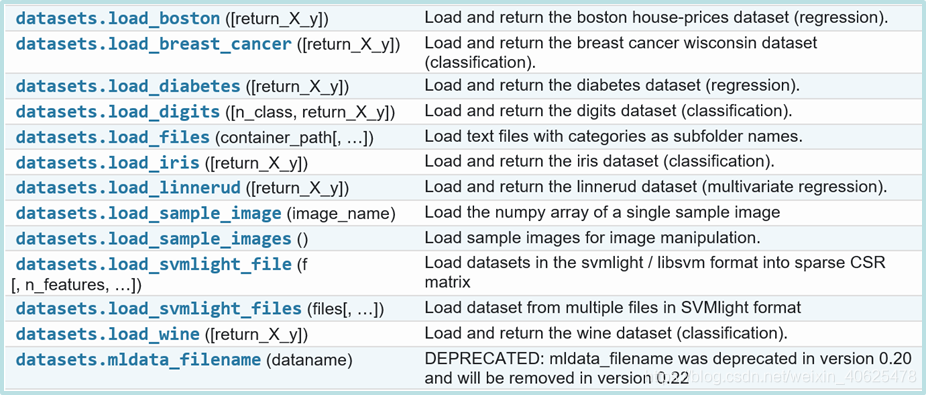
datasets模块提供了加载这些数据集的函数
iris(鸢尾花)数据集共有150个样本,每个样本记录鸢尾花的4个特征(萼片长和宽、花瓣长和宽)和对应的类别(共三个类别),每个类别的样本为50,按类别顺序记录,该数据用于分类。

datasets模块的load_iris()函数返回iris数据集对象,该对象有如下属性:
DESCR,该属性返回数据集的说明信息。
data,该属性返回150*4的二维数组,记录每个样本的4个特征。
target,该属性返回一个由150个元素组成的一维数组,记录对应的类别(0、1或2)。
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
frame = pd.DataFrame(X)
frame['class']= y
frame
digits(手写数字)数据集包括1797张88像素的灰度图,每张图的内容是一个手写数字,每张图实际的数字是分类类别,每张图中每个像素(栅格)值是用于分类的特征。该数据集用于分类。

datasets模块的load_digits()函数返回digits数据集对象,该对象有如下属性:
DESCR,该属性返回数据集的说明信息。
images,该属性返回179788的图像数组,数组中的每个元素表示一个图像。
data,该属性返回一个179764的二维数组,每一行记录一个8*8图像的栅格值。
target,该属性返回一个由1797个元素组成的一维数组,记录对应图像实际表示的数字(图像类别)。
from sklearn import datasets
digits = datasets.load_digits()
images = digits.images
data = digits.data
target = digits.target
print(images.shape)
print(data.shape)
print(target.shape)

%matplotlib inline
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
digits = datasets.load_digits()
fig = plt.figure()
for i in range(1,11):
ax = fig.add_subplot(3,4,i)
image = digits.images[i-1]
plt.imshow(image, cmap=plt.cm.gray_r)
print(digits.target[i-1])

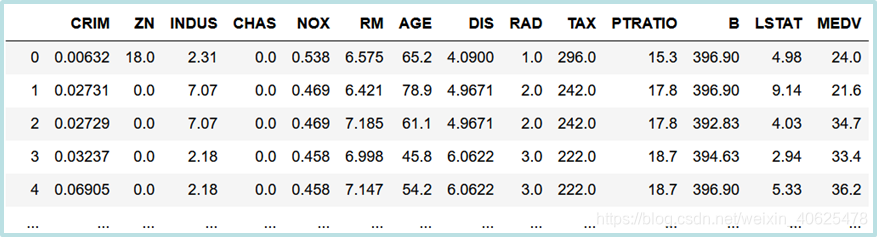
Boston房价数据集记录了506个区域的平均房价及区域相关的数据(包括人均犯罪率、居住用地比例、非零售商业比例等13个数据),用于回归分析,区域平均房价作为因变量,区域相关的数据作为影响房价的因子(特征)。
datasets模块的load_boston()函数返回boston数据集对象,该对象有如下属性:
DESCR,该属性返回数据集的说明信息。
data,该属性返回一个506*13的二维数组,每一行记录一个区域不同特征值。
target,该属性返回一个由506个元素组成的一维数组,记录每个区域的房价。
feature_names,该属性返回特征名一维数组
import pandas as pd
from sklearn import datasets
boston = datasets.load_boston()
frame = pd.DataFrame(boston.data,
columns=boston.feature_names)
frame['MEDV']=boston.target
frame
2.2模拟数据生成函数
scikit-learn包还提供了一些用于生成模拟数据的函数,可生成的数据包括:
用于分类的数据
用于回归的数据
用于聚类的数据
……

make_classification()函数用于生成分类数据,函数返回一个元组,第一个元素为m×n的二维数组(m为样本数,n为特征数),表示data;第二个元素为m个元素组成的一维数组(m为样本数),表示target(分类类别),分类类别数k小于样本数m
在实际的分类中,用于分类的数据并不是所有的特征都是和分类类别有关系的,对分类没有关系的特征称为噪声。此外,特征之间会有重复和相关。在生成模拟数据时,可以模拟这些特性。
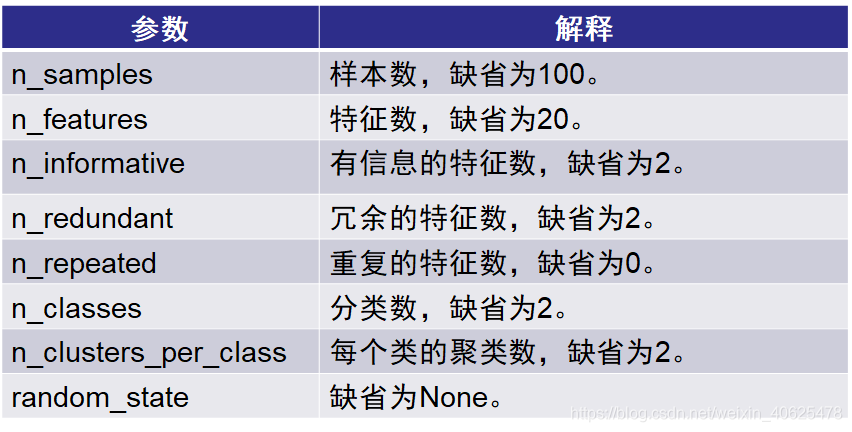
n_informative、n_redundant和n_repeated之和是非噪声的特征数,剩余的是噪声特征数。
n_classes*n_clusters_per_class必须小于等于2**n_informative。
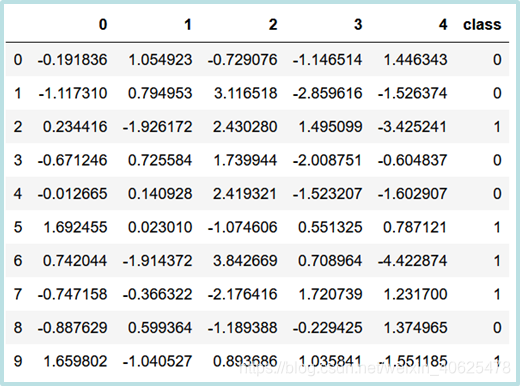
import pandas as pd
from sklearn import datasets
dataset = datasets.make_classification(n_samples=10,
n_features=5,
n_classes=2,
random_state=1)
frame = pd.DataFrame(dataset[0])
frame['class']=dataset[1]
frame
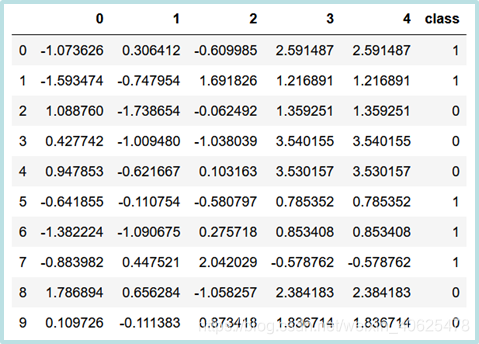
import pandas as pd
from sklearn import datasets
dataset = datasets.make_classification(n_samples=10,
n_features=5,
n_redundant=0,
n_repeated=1,
n_classes=2,
n_clusters_per_class=1,
random_state=1)
frame = pd.DataFrame(dataset[0])
frame['class']=dataset[1]
frame
random_state参数的缺省值是None,即根据随机值产生模拟结果,如要得到同样结果,需要设置random_state参数为同个值,如random_state=1。
make_regression()函数用于生成回归数据,函数返回一个元组,第一个元素为m×n的二维数组(m为样本数,n为特征数),表示data,第二个元素为m个元素组成的一维数组(m为样本数)或m×k的二维数组(m为样本数,k为目标数),表示目标值。
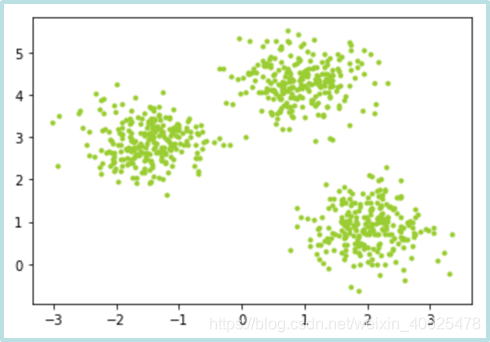
make_blobs()函数用于生成聚类数据,可通过centers参数设置聚类的个数或每个中心的位置,通过cluster_std参数设置聚类的标准偏差。
函数返回一个元组,第一个元素为m×n的二维数组(m为样本数,n为特征数),表示data,第二个元素为m个元素组成的一维数组(m为样本数),表示聚类的编号。
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot as plt
dataset = make_blobs(n_samples=750, cluster_std=0.5,random_state=0)
x = dataset[0][:,0]
y = dataset[0][:,1]
plt.scatter(x, y, color='yellowgreen', marker='.')
3. 分类
分类是通过学习的方法建立分类模型,然后利用模型对输入的数据进行分类,也称为监督分类。
分类可以是多类别分类,如利用遥感数据进行土地利用/土地覆盖分类;也可以是二值分类,如目标探测(是或不是)。
scikit-learn包提供了多个类用于监督分类,包括支持向量机分类、K近邻分类、决策树分类等。
scikit-learn包提供的用于监督分类的类
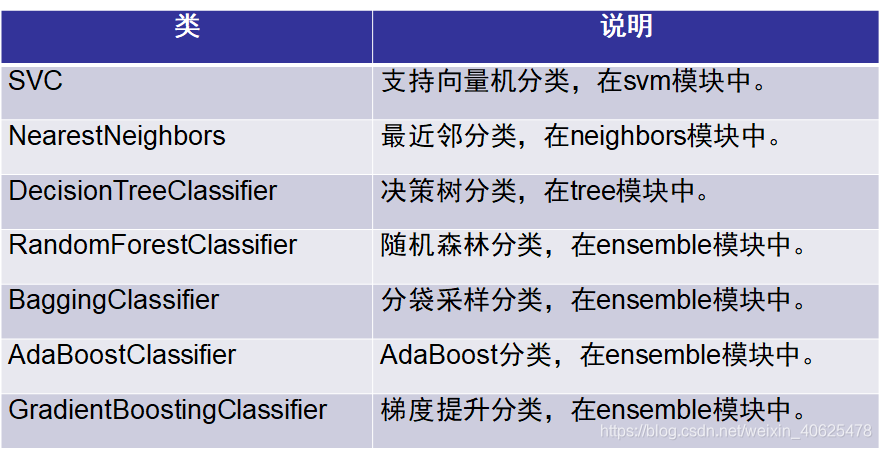
所有监督分类的步骤是一致的,具体步骤如下:
利用类的构造函数实例化一个分类对象,如SVC = svm.SVC()。不同的分类对象在实例化时有相应的关键词参数。
利用训练样本训练分类模型(利用模型对象的fit方法),如SVC.fit(X, y),X是训练样本的特征值,是一个m×n的二维数组,m为训练样本数,n为特征数;y是训练样本的类别值,是一个m个元素组成的一维数组。
利用训练后的分类模型对象预测其它样本的值,如SVC.predict(X),这里的X是待分类样本的特征值,也是一个m×n的二维数组,m为待分类样本数,n为特征数;预测结果返回一个m个元素组成的一维数组,每个元素表示分类值。















 2695
2695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











