







TOPSIS法(Technique for Order Preference by Similarity to an Ideal Solution )可以理解为逼近理想解排序法,国内也称作优劣解距离法。该方法只要求各效用函数具有单调递增(或递减)性就行。TOPSIS法是多目标决策分析中一种常用的有效方法。
举个例子:一个寝室四个人的高数成绩如下:
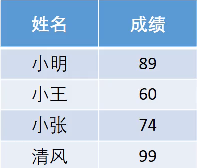
在这种情况下,我们如何确定权重(评分)呢?归一化!
归一化:是一种无量纲处理手段,使物理系统数值的绝对值变成某种相对值关系。简化计算,缩小量值的有效办法。
那么你可能也听说过标准化这个词
标准化:当几种参数的单位不一致时,使用标准化去除量纲。
这里我们采用的构造方式为
(
x
−
m
i
n
m
a
x
−
m
i
n
)
\genfrac (){1pt}{1}{x-min}{max-min}
(max−minx−min) ,缩小量值,然后归一化,让他们评分相加为1.

我们为什么采用这样的评分标准:
- 首先一般评价的对象一般远超于2个。
- 比较的指标也往往不是一个方面。
- 有很多指标不存在理论上的最大最小值,例如GDP增速。
当我们增加一个指标时:
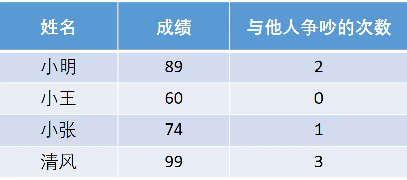
成绩属于极大型指标(效益性指标),属于越大越好。
争吵属于极小型指标(成本型指标),属于越小越好。
此时,我们需要把两种指标转化为相同方向。(统一指标类型)
将所有指标正向化处理,极小型指标转化极大型指标公式
m
a
x
−
x
max-x
max−x

此时我们可以发现,争吵次数与成绩是两种不同单位的指标参数,所以我们利用标准化来去除量纲的影响。
假设有n个要评价的对象,m个指标参数(都已经正向化),构成的正向化矩阵为:X =
[
x
11
.
.
.
x
1
m
x
21
.
.
.
x
2
m
.
.
.
.
.
.
.
.
.
x
n
1
.
.
.
x
n
m
]
\begin{bmatrix} x_{11} & ... & x_{1m} \\ x_{21} & ... & x_{2m} \\ ... & ... & ... \\ x_{n1} & ... & x_{nm} \\ \end{bmatrix}
⎣⎢⎢⎡x11x21...xn1............x1mx2m...xnm⎦⎥⎥⎤,那么标准化后的矩阵记为Z,Z中的每一个元素:
z
i
j
=
x
i
j
/
∑
i
=
1
n
x
i
j
2
z_{ij}= x_{ij}/\sqrt{\displaystyle\sum_{i=1}^nx_{ij}^2}
zij=xij/i=1∑nxij2,经过变换:
[
89
1
60
3
74
2
99
0
]
\begin{bmatrix} 89 &1 \\ 60 &3\\ 74&2\\ 99&0 \\ \end{bmatrix}
⎣⎢⎢⎡896074991320⎦⎥⎥⎤ =====>
[
0.5437
0.2673
0.3665
0.8018
0.4520
0.5345
0.6048
0
]
\begin{bmatrix} 0.5437 &0.2673 \\ 0.3665 &0.8018\\ 0.4520&0.5345\\ 0.6048&0 \\ \end{bmatrix}
⎣⎢⎢⎡0.54370.36650.45200.60480.26730.80180.53450⎦⎥⎥⎤ 相关代码:清风数学建模
1.类比只有一个指标的计算得分
假设有n个要评价的对象,m个指标指标的标准化矩阵: Z = [ z 11 . . . z 1 m z 21 . . . z 2 m . . . . . . . . . z n 1 . . . z n m ] Z = \begin{bmatrix} z_{11} & ... & z_{1m} \\ z_{21} & ... & z_{2m} \\ ... & ... & ... \\ z_{n1} & ... & z_{nm} \\ \end{bmatrix} Z=⎣⎢⎢⎡z11z21...zn1............z1mz2m...znm⎦⎥⎥⎤,我们定义每一指标的最大值 Z i + Z^+_i Zi+ ,最小值 Z i − Z^-_i Zi−,定义第i(i=1,2,3…n)个评价对象与最大值的距离 D i + = ∑ j = 1 m ( Z i + − z i j ) 2 D_i^+= \sqrt{\displaystyle\sum_{j=1}^m(Z_i^+-z_{ij})^2} Di+=j=1∑m(Zi+−zij)2,第i(i=1,2,3…n)个评价对象与最小值的距离 D i − = ∑ j = 1 m ( Z i − − z i j ) 2 D_i^-= \sqrt{\displaystyle\sum_{j=1}^m(Z_i^--z_{ij})^2} Di−=j=1∑m(Zi−−zij)2,那么评价对象未归一化的得分: S i = D i − D i − + D i + S_i =\tfrac{D_i^-}{D_i^-+D_i^+} Si=Di−+Di+Di−,明显可以看出 S i S_i Si一定是在0到1之间,即 D i + D_i^+ Di+这个最大距离越小, S i S_i Si越大,即越接近最大值。这也是为什么TOPSIS也叫做优劣解距离法
2.解题步骤
第一步:将原始矩阵正向化
最常见的四种指标:
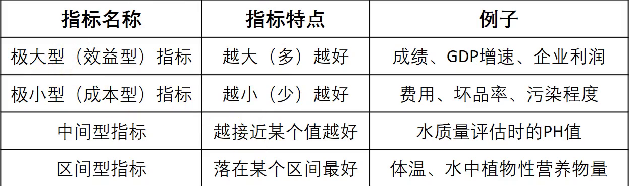
如何极小型转化极大型:
- max - x:最大值减去当前x
- 如果所有元素都为正数,直接变成倒数 1 x \tfrac{1}{x} x1
如何中间型转化极大型:
设中间型为
x
b
e
s
t
x_{best}
xbest,那么未归一化得分公式为
M
=
m
a
x
(
∣
x
i
−
x
b
e
s
t
∣
)
M = max(|x_i-x_{best}|)
M=max(∣xi−xbest∣),
x
i
~
=
1
−
∣
x
i
−
x
b
e
s
t
∣
M
\widetilde{x_i}=1-\tfrac{|x_i-x_{best}|}{M}
xi
=1−M∣xi−xbest∣
如何区间型转化极大型:
是指值落在某个区间内最好,设区间为[a,b],有
M
=
m
a
x
(
a
−
m
i
n
(
x
i
)
,
m
a
x
(
x
i
)
−
b
)
M = max(a-min(x_i),max(x_i)-b)
M=max(a−min(xi),max(xi)−b)
x
i
~
=
{
1
−
a
−
x
M
,
x
<
a
1
,
a
<
=
x
<
=
b
1
−
x
−
b
M
,
x
>
b
\widetilde{x_i} = \begin{cases} 1- \tfrac{a-x}{M} ,x < a \\ 1 ,a <= x <= b\\ 1- \tfrac{x-b}{M} ,x > b \end{cases}
xi
=⎩⎪⎨⎪⎧1−Ma−x,x<a1,a<=x<=b1−Mx−b,x>b
第二步: 将正向化转换成标准化:假设有n个要评价的对象,m个指标参数(都已经正向化),构成的正向化矩阵为:
X
=
[
x
11
.
.
.
x
1
m
x
21
.
.
.
x
2
m
.
.
.
.
.
.
.
.
.
x
n
1
.
.
.
x
n
m
]
X = \begin{bmatrix} x_{11} & ... & x_{1m} \\ x_{21} & ... & x_{2m} \\ ... & ... & ... \\ x_{n1} & ... & x_{nm} \\ \end{bmatrix}
X=⎣⎢⎢⎡x11x21...xn1............x1mx2m...xnm⎦⎥⎥⎤,那么标准化后的矩阵记为Z,Z中的每一个元素:
z
i
j
=
x
i
j
/
∑
j
=
1
m
x
i
j
2
z_{ij}= x_{ij}/\sqrt{\displaystyle\sum_{j=1}^mx_{ij}^2}
zij=xij/j=1∑mxij2
每
一
个
元
素
/
其
所
在
列
的
平
方
和
每一个元素/\sqrt{其所在列的平方和}
每一个元素/其所在列的平方和
第三步: 计算得分并归一化。
这就是TOPSIS的流程~
补充:基于熵权法对TOPSIS模型的修正
由于层次分析法的主观性影响太大,所以我们利用熵权法(一种客观客观赋权的方法)。
什么是熵权法:
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量;如果指标的信息熵越大,该指标提供的信息量越大,在综合评价中所起作用理当越大,权重就应该越高。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
这里的信息熵我们看作是方差,方差越大,波动程度越大,意味着权重也就越大。

越可能发生的事情,信息量越小;
越不可能发生的事情,信息量就越大。
熵权法的计算步骤
1.判断输入的矩阵中是否存在负数,如果有则要重新标准化到非负区间(后面计算概率时要保证每一个元素为非负数)
Z
(
i
j
)
=
x
(
i
j
)
−
m
i
n
(
x
(
i
j
)
)
m
a
x
(
x
(
i
j
)
)
−
m
i
n
(
x
(
i
j
)
)
Z_(ij) = \tfrac{x_(ij)-min(x_(ij))}{max(x_(ij))-min(x_(ij))}
Z(ij)=max(x(ij))−min(x(ij))x(ij)−min(x(ij))
2.计算第j项指标下第i个样本所占的权重,并将其看作相对熵计算所用到的概率。
Z
~
=
[
z
~
11
.
.
.
z
~
1
m
z
~
21
.
.
.
z
~
2
m
.
.
.
.
.
.
.
.
.
z
~
n
1
.
.
.
z
~
n
m
]
\widetilde Z = \begin{bmatrix} \widetilde z_{11} & ... &\widetilde z_{1m} \\ \widetilde z_{21} & ... &\widetilde z_{2m} \\ ... & ... & ... \\ \widetilde z_{n1} & ... &\widetilde z_{nm} \\ \end{bmatrix}
Z
=⎣⎢⎢⎡z
11z
21...z
n1............z
1mz
2m...z
nm⎦⎥⎥⎤
p
i
j
=
z
~
i
j
/
∑
i
=
1
n
z
~
i
j
p_{ij} = \widetilde z_{ij}/\sqrt{\displaystyle\sum_{i=1}^n\widetilde z_{ij}}
pij=z
ij/i=1∑nz
ij
保证了每一个概率之和相加为1.
3.计算每个指标的信息熵,并计算信息效用值,并归一化得到每一个指标的熵权。对于第j个指标而言,其信息熵的计算公式为:
e
j
=
−
1
l
n
n
∑
i
=
1
n
p
i
j
l
n
(
p
i
j
)
e_j = - \tfrac{1}{lnn}\sum_{i=1}^np_{ij}ln(p_{ij})
ej=−lnn1i=1∑npijln(pij)
e
j
e_j
ej越大,所代表第j个指标的信息熵越大,信息熵越大他本身所包含的信息量就越少,就像前面例子所说,每次考试都考第一名高考一定会考上清华,毋庸置疑,大家是一定相信的,所以包含的信息相对少;而吊车尾突然考上清华,大家就会猜测,他是怎么考上的呢?这里包含的信息量就相对大。
信息效用值:
d
j
=
1
−
e
j
d_j = 1 - e_j
dj=1−ej信息效用值越大,其对应所含的信息就越多。将信息效用值进行归一化,我们就能得到每一个指标的熵权:
W
j
=
d
j
/
∑
j
=
1
m
d
j
(
j
=
1
,
2
,
3...
)
W_j = d_j /\displaystyle\sum_{j=1}^md_j (j = 1,2,3...)
Wj=dj/j=1∑mdj(j=1,2,3...)
熵权法的依据原理
指标的变异程度越小,所反映的信息量也越少,其对应的权值也相应越低。















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









