







EM:Expectation-Maximization
一、极大似然估计
1. 举例
举个栗子: 假如你去赌场,但是不知道能不能赚钱,你就在门口堵着出来一个人就问一个赚了还是赔了,如果问了5个人都说赚了,那么你就会认为,赚钱的概率肯定是非常大的。
已知:(1)样本服从分布的模型(2)观测到的样本
求解:模型的参数
总的来说:极大似然估计就是用样本来估计模型参数的统计学方法
2. 极大似然数学问题
100名学生的身高问题
样本集 X = { x 1 , x 2 , . . . , x n } , n = 100 X=\{x_{1},x_{2},...,x_{n}\},n=100 X={x1,x2,...,xn},n=100
概率密度: p ( x i ∣ θ ) p(x_{i}|\theta) p(xi∣θ)抽到男生 i i i(的身高)的概率, θ \theta θ是服从分布的参数
独立同分布:同时抽到这100个男生的概率就是他们各自概率的乘积
极大似然函数
公式: l ( θ ) = ∑ i = 1 m l o g p ( x i ; θ ) l(\theta)=\sum_{i=1}^mlogp(x_{i};\theta) l(θ)=∑i=1mlogp(xi;θ) (对数是为了乘法转加法)
什么样的参数 θ \theta θ能够使得出现当前这批样本的概率最大
已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。
加大问题的难度
现在这100个人中,不光有男生,还有女生(2个类别,2种参数)
男生和女生的身高都服从高斯分布,但是参数不同(均值,方差)
求解目标:男生和女生对应的身高的高斯分布的参数是多少
用数学的语言描述:抽取得到的每个样本都不知道是从哪个分布抽取的
加入隐变量
用Z=0或Z=1标记样本来自哪个分布,则Z就是隐变量。
极大似然函数: l ( θ ) = ∑ i = 1 m l o g p ( x i ; θ ) = ∑ i = 1 m l o g ∑ Z p ( x i , Z ; θ ) l(\theta)=\sum_{i=1}^mlogp(x_{i};\theta)=\sum_{i=1}^mlog\sum_{Z}p(x_{i},Z;\theta) l(θ)=i=1∑mlogp(xi;θ)=i=1∑mlogZ∑p(xi,Z;θ)
求解:在给定初始值情况下进行迭代求解
二、EM算法
1. 经典案例
从A和B两枚硬币中每次选择1枚抛10次,分别进行5轮,得出下图中左边的正反面样本数据。A和B正面朝上的概率未知,请根据样本数据求解A和B正面朝上的概率。
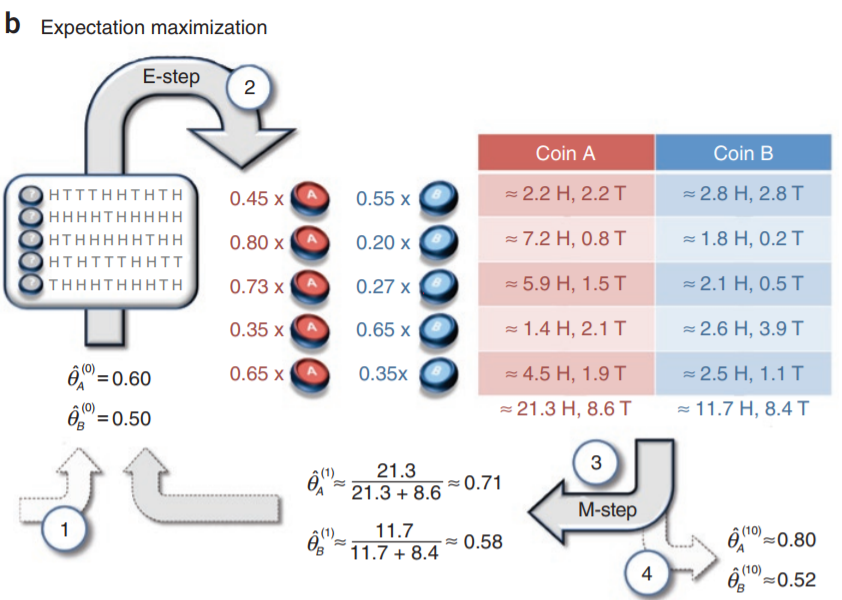
- 假设两枚硬币的初始假设的分布
A硬币:60%概率正面朝上
B硬币:50%概率正面朝上
- E步骤:
(1)由第1条数据,根据初始硬币的概率分布,投掷出5正5反的概率:
p ( A ) = C 10 5 × 0. 6 5 × 0. 4 5 p(A)=C_{10}^5\times0.6^5\times0.4^5 p(A)=C105×0.65×0.45
p ( B ) = C 10 5 × 0. 5 5 × 0. 5 5 p(B)=C_{10}^5\times0.5^5\times0.5^5 p(B)=C105×0.55×0.55
(2)则观测结果来自硬币A的概率: p ( A ) p ( A ) + p ( B ) = 0.45 \frac{p(A)}{p(A)+p(B)}=0.45 p(A)+p(B)p(A)=0.45,观测结果来自硬币B的概率: 1 − p ( A ) = 0.55 1-p(A)=0.55 1−p(A)=0.55
为什么通过
p
(
A
)
p(A)
p(A)和
p
(
B
)
p(B)
p(B)能算出来自A和B的概率?
答:
同理,由第2-5条数据也可以计算出选择硬币A和B的概率。
- M步骤:
(1)对每一条数据,根据E步骤求得的选择A和B的概率分别计算A和B抛出正反面的期望。
(2)将根据五条数据求得的A正反面的期望相加,则A正面朝上的概率: θ A ≈ 21.3 21.3 + 8.6 ≈ 0.71 \theta_{A}\approx\frac{21.3}{21.3+8.6}\approx0.71 θA≈21.3+8.621.3≈0.71;同理,B正面朝上的概率: θ B ≈ 11.7 11.7 + 8.4 ≈ 0.58 \theta_{B}\approx\frac{11.7}{11.7+8.4}\approx0.58 θB≈11.7+8.411.7≈0.58
- 迭代
重复E步骤和M步骤,直到 θ A \theta_{A} θA和 θ B \theta_{B} θB收敛,得到 θ A ≈ 0.80 \theta_{A}\approx0.80 θA≈0.80, θ B ≈ 0.52 \theta_{B}\approx0.52 θB≈0.52
2. EM算法推导
问题:样本集 { x 1 , … , x m } \{x_1,…,x_m\} {x1,…,xm},包含m个独立的样本。
其中每个样本 i i i对应的类别 z i z_i zi是未知的,所以很难用最大似然求解。
l ( θ ) = ∑ i = 1 m l o g p ( x i ; θ ) = ∑ i = 1 m l o g ∑ Z p ( x i , Z ; θ ) l(\theta)=\sum_{i=1}^mlogp(x_{i};\theta)=\sum_{i=1}^mlog\sum_{Z}p(x_{i},Z;\theta) l(θ)=i=1∑mlogp(xi;θ)=i=1∑mlogZ∑p(xi,Z;θ)
上式中,要考虑每个样本在各个分布中的情况。本来正常求偏导就可以了,但是现在log后面还有求和,这就难解了!
右式分子分母同时乘 Q ( z ) : Q(z): Q(z): l o g ∑ Z p ( x i , Z ; θ ) = l o g ∑ Z Q ( Z ) p ( x i , Z ; θ ) Q ( Z ) log\sum_Z p(x_i,Z;\theta)=log\sum_Z Q(Z)\frac{p(x_i,Z;\theta)}{Q(Z)} logZ∑p(xi,Z;θ)=logZ∑Q(Z)Q(Z)p(xi,Z;θ)
为何这么做?答:为了凑Jensen不等式( Q ( Z ) Q(Z) Q(Z)是Z的分布函数)
2.1 Jensen不等式
设 f f f是定义域为实数的函数,如果对于所有的实数 x x x, f ( x ) f(x) f(x)的二次导数大于等于0,那么 f f f是凸函数。
如果 f f f是凸函数, X X X是随机变量,那么: E [ f ( X ) ] ≥ f ( E [ X ] ) E[f(X)]\ge f(E[X]) E[f(X)]≥f(E[X])

实线 f f f是凸函数, X X X有0.5的概率是a,有0.5的概率是b,那么 X X X的期望值就是a和b的中值了,则: f ( a ) + f ( b ) 2 ≥ f ( a + b 2 ) \frac{f(a)+f(b)}{2} \ge f (\frac{a+b}{2}) 2f(a)+f(b)≥f(2a+b)
Jensen不等式应用于凹函数时,不等号取反向。
2.2 推导过程
由于 Q ( Z ) p ( x i , Z ; θ ) Q ( Z ) Q(Z)\frac{p(x_i,Z;\theta)}{Q(Z)} Q(Z)Q(Z)p(xi,Z;θ)是 p ( x i , Z ; θ ) Q ( Z ) \frac{p(x_i,Z;\theta)}{Q(Z)} Q(Z)p(xi,Z;θ)的期望,假设 Y = p ( x i , Z ; θ ) Q ( Z ) Y=\frac{p(x_i,Z;\theta)}{Q(Z)} Y=Q(Z)p(xi,Z;θ),有 Q ( Z ) = P ( Y ) Q(Z)=P(Y) Q(Z)=P(Y),则:
l o g ∑ Z Q ( Z ) p ( x i , Z ; θ ) Q ( Z ) = l o g ∑ Y P ( Y ) Y = l o g E ( Y ) log\sum_Z Q(Z)\frac{p(x_i,Z;\theta)}{Q(Z)}=log\sum_YP(Y)Y=logE(Y) logZ∑Q(Z)Q(Z)p(xi,Z;θ)=logY∑P(Y)Y=logE(Y)
由于Jensen不等式应用于凹函数时( l o g log log函数为凹函数),不等号取反向,可得:
l o g E ( Y ) ≥ E ( l o g Y ) = ∑ Y P ( l o g Y ) l o g Y = ∑ Y P ( Y ) l o g Y = ∑ Z Q ( Z ) l o g p ( x i , Z ; θ ) Q ( Z ) logE(Y)\ge E(logY)=\sum_Y P(logY)logY=\sum_Y P(Y)logY=\sum_Z Q(Z)log \frac{p(x_i,Z;\theta)}{Q(Z)} logE(Y)≥E(logY)=Y∑P(logY)logY=Y∑P(Y)logY=Z∑Q(Z)logQ(Z)p(xi,Z;θ)
( P(Y)和P(logY)是否相等? )答:相等
即: l o g ∑ Z Q ( Z ) p ( x i , Z ; θ ) Q ( Z ) ≥ ∑ Z Q ( Z ) l o g p ( x i , Z ; θ ) Q ( Z ) log\sum_Z Q(Z)\frac{p(x_i,Z;\theta)}{Q(Z)}\ge\sum_Z Q(Z)log \frac{p(x_i,Z;\theta)}{Q(Z)} logZ∑Q(Z)Q(Z)p(xi,Z;θ)≥Z∑Q(Z)logQ(Z)p(xi,Z;θ)
由于 l o g ∑ Z Q ( Z ) p ( x i , Z ; θ ) Q ( Z ) = l o g ∑ Z p ( x i , Z ; θ ) = l o g p ( x i ; θ ) log\sum_Z Q(Z)\frac{p(x_i,Z;\theta)}{Q(Z)}=log\sum_{Z}p(x_{i},Z;\theta)=logp(x_{i};\theta) log∑ZQ(Z)Q(Z)p(xi,Z;θ)=log∑Zp(xi,Z;θ)=logp(xi;θ),可得:
l ( θ ) = ∑ i = 1 m l o g p ( x i ; θ ) ≥ ∑ i = 1 m ∑ Z Q ( Z ) l o g p ( x i , Z ; θ ) Q ( Z ) l(\theta)=\sum_{i=1}^mlogp(x_{i};\theta)\ge \sum_{i=1}^m \sum_Z Q(Z)log \frac{p(x_i,Z;\theta)}{Q(Z)} l(θ)=i=1∑mlogp(xi;θ)≥i=1∑mZ∑Q(Z)logQ(Z)p(xi,Z;θ)
下界比较好求,所以我们要优化这个下界来使得似然函数最大。
优化下界
迭代到收敛

如何能使得等式成立呢?(取等号)
Jensen中等式成立的条件是随机变量是常数: Y = p ( x i , Z ; θ ) Q ( Z ) = C Y=\frac{p(x_i,Z;\theta)}{Q(Z)}=C Y=Q(Z)p(xi,Z;θ)=C
Q ( Z ) Q(Z) Q(Z)是 Z Z Z的分布函数: ∑ Z Q ( Z ) = ∑ Z p ( x i , Z ; θ ) C = 1 \sum_ZQ(Z)=\sum_Z \frac{p(x_i,Z;\theta)}{C}=1 ∑ZQ(Z)=∑ZCp(xi,Z;θ)=1
所有的分子之和等于常数C(分母相同)
Q ( Z ) Q(Z) Q(Z)求解
由 ∑ Z Q ( Z ) = ∑ Z p ( x i , Z ; θ ) C = 1 \sum_ZQ(Z)=\sum_Z \frac{p(x_i,Z;\theta)}{C}=1 ∑ZQ(Z)=∑ZCp(xi,Z;θ)=1 得: C = ∑ Z p ( x i , Z ; θ ) C=\sum_Z p(x_i,Z;\theta) C=∑Zp(xi,Z;θ),则:
Q ( Z ) = p ( x i , Z ; θ ) C = p ( x i , Z ; θ ) ∑ Z p ( x i , Z ; θ ) = p ( x i , Z ; θ ) p ( x i ) = p ( Z ∣ x i ; θ ) Q(Z)=\frac{p(x_i,Z;\theta)}{C}=\frac{p(x_i,Z;\theta)}{\sum_Z p(x_i,Z;\theta)}=\frac{p(x_i,Z;\theta)}{p(x_i)}=p(Z|x_i;\theta) Q(Z)=Cp(xi,Z;θ)=∑Zp(xi,Z;θ)p(xi,Z;θ)=p(xi)p(xi,Z;θ)=p(Z∣xi;θ)
其中, p ( x i , Z ; θ ) p(x_i,Z;\theta) p(xi,Z;θ)为取某一个Z值时的概率, ∑ Z p ( x i , Z ; θ ) \sum_Z p(x_i,Z;\theta) ∑Zp(xi,Z;θ)为所有的可能性。
Q ( Z ) Q(Z) Q(Z)代表第 i i i个数据来自某个 Z Z Z的概率。
2.3 EM算法流程
(1)初始化分布参数 θ \theta θ
(2)E-step:根据参数 θ θ θ计算每个样本属于 Z i Z_i Zi的概率(也就是 Q Q Q)
(3)M-Step:根据 Q Q Q,求出含有 θ \theta θ的似然函数的下界并最大化它,得到新的参数 θ \theta θ
(4)不断的迭代更新,直至收敛。
三、高斯混合模型(GMM)
-
数据可以看作是从数个Gaussian Distribution 中生成出来的
-
GMM 由K 个Gaussian 分布组成,每个Gaussian 称为一个“Component”
-
类似k-means方法,求解方式跟EM一样
-
不断的迭代更新,直至收敛。















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









