







任务简介:
了解序列化与反序列化;了解transfer learning 与 model finetune
详细说明:
本节第一部分学习pytorch中的模型保存与加载,也常称为序列化与反序列化,本节将学习序列化与反序列化的概念,进而对模型的保存与加载有深刻的认识,同时介绍pytorch中模型保存与加载的方法函数。
本节第二部分学习模型微调(Finetune)的方法,以及认识Transfer Learning(迁移学习)与Model Finetune之间的关系。
一、序列化与反序列化
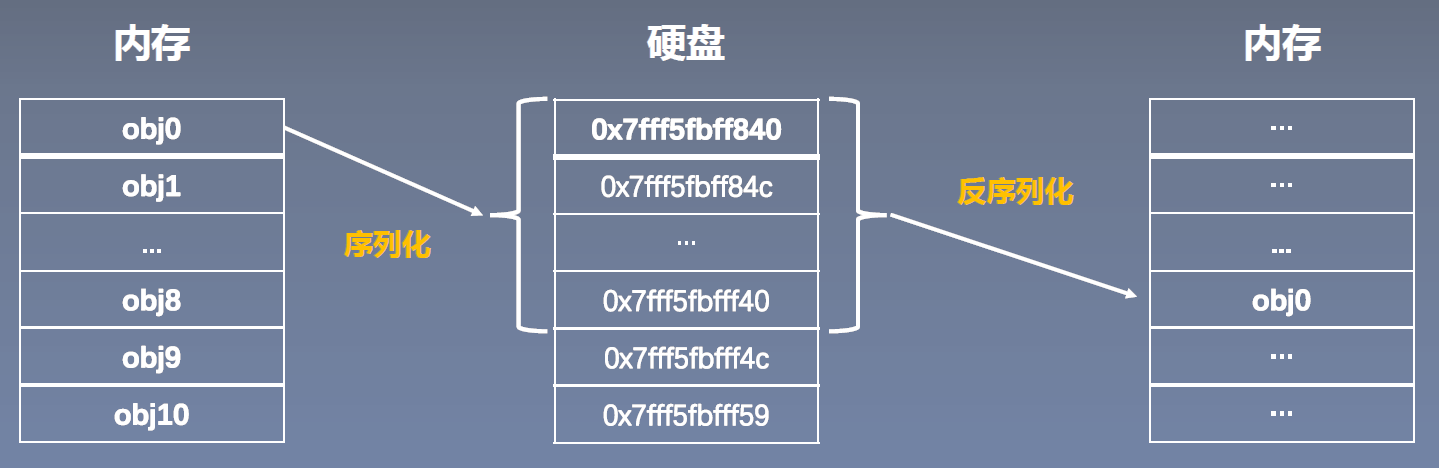
PyTorch中的序列化与反序列化:

二、模型保存与加载的两种方式
模型保存的两种方式:
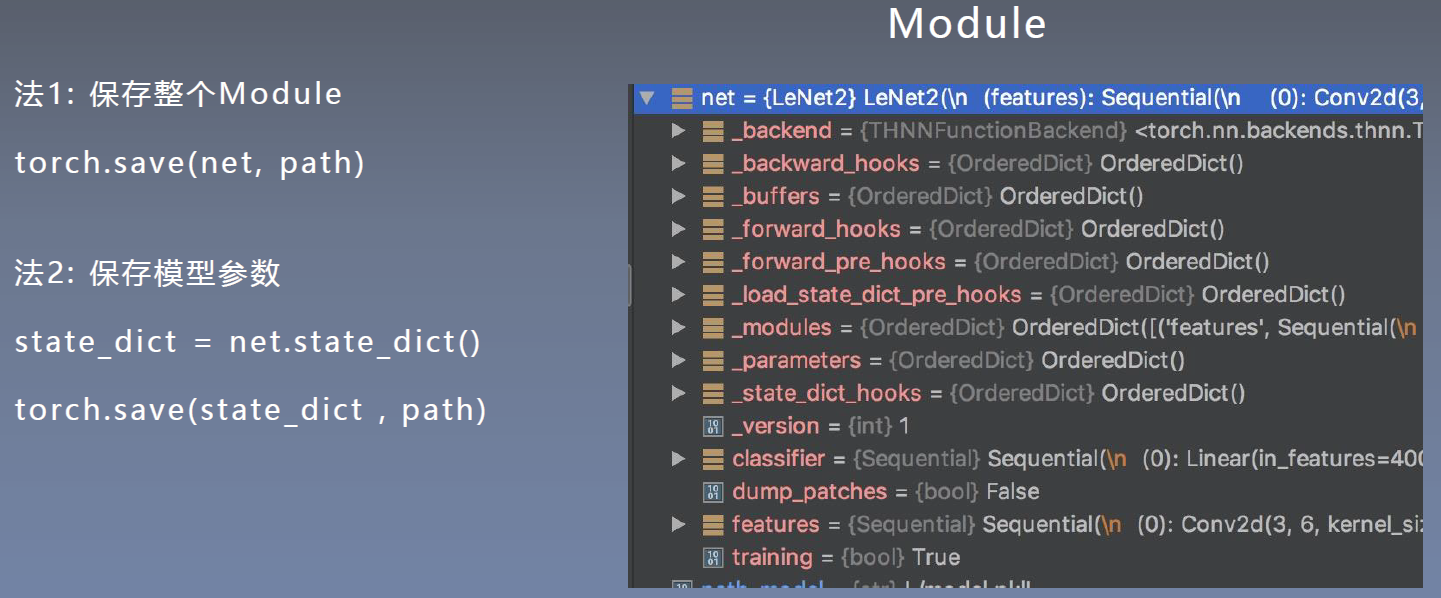
方法2比方法1速度快,但方法2只保存了模型的参数,加载时需要将参数放入网络中才能获得完整模型。
- 保存模型:
测试代码:
import torch
import numpy as np
import torch.nn as nn
from tools.common_tools import set_seed
class LeNet2(nn.Module):
def __init__(self, classes):
super(LeNet2, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
def initialize(self):
for p in self.parameters():
p.data.fill_(20191104)
net = LeNet2(classes=2019)
# "训练"
print("训练前: ", net.features[0].weight[0, ...])
net.initialize()
print("训练后: ", net.features[0].weight[0, ...])
path_model = "./model.pkl"
path_state_dict = "./model_state_dict.pkl"
# 方法1:保存整个模型
torch.save(net, path_model)
# 方法2:保存模型参数
net_state_dict = net.state_dict()
torch.save(net_state_dict, path_state_dict)
输出:
训练前: tensor([[[-0.0688, 0.0352, -0.0851, 0.0967, 0.0009],
[ 0.0147, -0.1099, -0.0771, -0.0724, -0.0115],
[ 0.0284, -0.0681, 0.0173, 0.0605, -0.0532],
[ 0.0633, 0.0034, -0.0758, -0.0935, -0.0514],
[ 0.0535, 0.0779, 0.0763, -0.0133, 0.0908]],
[[-0.0762, -0.0750, 0.0036, 0.0081, -0.0599],
[ 0.0548, -0.0073, 0.0883, -0.1042, -0.0900],
[-0.0010, 0.0885, -0.0534, 0.0154, -0.1147],
[ 0.0680, -0.0678, 0.0944, 0.0110, 0.0928],
[-0.0784, 0.0951, 0.0315, 0.0429, 0.0558]],
[[-0.0358, -0.0080, -0.0291, -0.0984, -0.1106],
[-0.0667, -0.0410, 0.0611, 0.1053, -0.0444],
[-0.1016, -0.0010, -0.0353, 0.0638, 0.0796],
[-0.0542, -0.1152, -0.0167, 0.0984, -0.0854],
[-0.0337, -0.0077, -0.0425, 0.0431, -0.0985]]],
grad_fn=<SelectBackward>)
训练后: tensor([[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]],
[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]],
[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]]],
grad_fn=<SelectBackward>)
- 加载模型
测试代码:
import torch
import numpy as np
import torch.nn as nn
from tools.common_tools import set_seed
class LeNet2(nn.Module):
def __init__(self, classes):
super(LeNet2, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
def initialize(self):
for p in self.parameters():
p.data.fill_(20191104)
# ================================== load net ===========================
flag = 1
# flag = 0
if flag:
path_model = "./model.pkl"
net_load = torch.load(path_model)
print(net_load)
输出:
LeNet2(
(features): Sequential(
(0): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=400, out_features=120, bias=True)
(1): ReLU()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): ReLU()
(4): Linear(in_features=84, out_features=2019, bias=True)
)
)
加载和更新state_dict:
# ================================== load state_dict ===========================
flag = 1
# flag = 0
if flag:
path_state_dict = "./model_state_dict.pkl"
state_dict_load = torch.load(path_state_dict)
print(state_dict_load.keys())
# ================================== update state_dict ===========================
flag = 1
# flag = 0
if flag:
net_new = LeNet2(classes=2019)
print("加载前: ", net_new.features[0].weight[0, ...])
net_new.load_state_dict(state_dict_load)
print("加载后: ", net_new.features[0].weight[0, ...])
输出:
odict_keys(['features.0.weight', 'features.0.bias', 'features.3.weight', 'features.3.bias', 'classifier.0.weight', 'classifier.0.bias', 'classifier.2.weight', 'classifier.2.bias', 'classifier.4.weight', 'classifier.4.bias'])
加载前: tensor([[[ 0.0147, 0.0484, 0.0264, 0.0008, -0.0298],
[-0.0247, -0.0993, -0.0027, 0.0430, -0.0955],
[ 0.0153, 0.0394, -0.0076, -0.0450, -0.1092],
[ 0.0114, 0.1027, -0.0189, -0.0330, 0.0977],
[ 0.0666, -0.0971, -0.0930, 0.0110, 0.0638]],
[[ 0.0006, -0.0326, 0.0263, 0.0948, -0.0631],
[-0.1066, -0.0316, 0.0757, -0.0114, 0.1028],
[ 0.0704, 0.0368, 0.1142, -0.0035, -0.1099],
[ 0.0567, -0.0815, -0.0002, -0.1015, 0.0845],
[ 0.0235, 0.0542, 0.0773, 0.0409, 0.0635]],
[[-0.0032, -0.0301, 0.0489, 0.0596, -0.0180],
[ 0.0137, 0.0171, 0.0843, -0.1067, 0.0658],
[-0.0924, -0.0611, 0.0802, -0.0018, 0.0137],
[ 0.0364, -0.1142, -0.0575, 0.0875, -0.0954],
[-0.0945, 0.0257, 0.0327, 0.0037, -0.0766]]],
grad_fn=<SelectBackward>)
加载后: tensor([[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]],
[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]],
[[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.],
[20191104., 20191104., 20191104., 20191104., 20191104.]]],
grad_fn=<SelectBackward>)
三、模型断点续训练

模型和优化器会随着迭代训练而变化,优化器中的缓存如momentum数值会改变。
- 模拟意外中断
测试代码:
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
import torchvision
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
checkpoint_interval = 5
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
start_epoch = -1
for epoch in range(start_epoch+1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
if (epoch+1) % checkpoint_interval == 0:
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
if epoch > 5:
print("训练意外中断...")
break
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val/len(valid_loader), correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
输出:
Training:Epoch[000/010] Iteration[010/010] Loss: 0.6846 Acc:53.75%
Valid: Epoch[000/010] Iteration[002/002] Loss: 0.4902 Acc:53.75%
Training:Epoch[001/010] Iteration[010/010] Loss: 0.4099 Acc:85.00%
Valid: Epoch[001/010] Iteration[002/002] Loss: 0.0414 Acc:85.00%
Training:Epoch[002/010] Iteration[010/010] Loss: 0.1470 Acc:94.38%
Valid: Epoch[002/010] Iteration[002/002] Loss: 0.0018 Acc:94.38%
Training:Epoch[003/010] Iteration[010/010] Loss: 0.4276 Acc:88.12%
Valid: Epoch[003/010] Iteration[002/002] Loss: 0.1125 Acc:88.12%
Training:Epoch[004/010] Iteration[010/010] Loss: 0.3169 Acc:87.50%
Valid: Epoch[004/010] Iteration[002/002] Loss: 0.0616 Acc:87.50%
Training:Epoch[005/010] Iteration[010/010] Loss: 0.2026 Acc:91.88%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0066 Acc:91.88%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.0866 Acc:98.12%
训练意外中断...
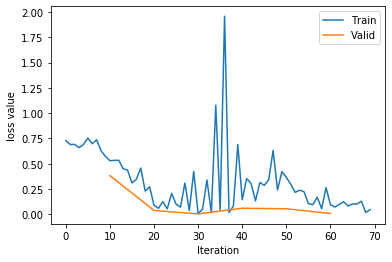
- 继续训练
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
import torchvision
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
checkpoint_interval = 5
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5+/5 断点恢复 ============================
path_checkpoint = "./checkpoint_4_epoch.pkl"
checkpoint = torch.load(path_checkpoint)
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
scheduler.last_epoch = start_epoch
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
if (epoch+1) % checkpoint_interval == 0:
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dic": optimizer.state_dict(),
"loss": loss,
"epoch": epoch}
path_checkpoint = "./checkpint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
# if epoch > 5:
# print("训练意外中断...")
# break
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val/len(valid_loader), correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
输出:
Training:Epoch[005/010] Iteration[010/010] Loss: 0.2066 Acc:90.62%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0410 Acc:90.62%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.2115 Acc:91.25%
Valid: Epoch[006/010] Iteration[002/002] Loss: 0.0111 Acc:91.25%
Training:Epoch[007/010] Iteration[010/010] Loss: 0.0876 Acc:98.12%
Valid: Epoch[007/010] Iteration[002/002] Loss: 0.0173 Acc:98.12%
Training:Epoch[008/010] Iteration[010/010] Loss: 0.0466 Acc:98.75%
Valid: Epoch[008/010] Iteration[002/002] Loss: 0.0045 Acc:98.75%
Training:Epoch[009/010] Iteration[010/010] Loss: 0.0249 Acc:98.75%
Valid: Epoch[009/010] Iteration[002/002] Loss: 0.0016 Acc:98.75%
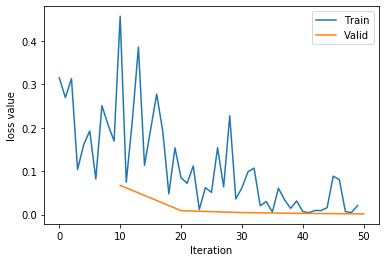















 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









