






大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
AI大模型领域,最近真可谓是“风波诡谲”。
故事的发展脉络是这样的。
在11月14日之前,GPT-4o模型,确切的说,是ChatGPT-4o-latest (2024-09-03)模型长期在LMSYS聊天机器人排行榜(Chatbot Arena Leaderboard) 霸榜,牢牢占据首位。
11月14日,谷歌发布新版实验模型Gemini-Exp-1114,这款模型出道即巅峰,迅速登上了LMSYS排行榜的第一名。为此,LMSYS官方专门发帖祝贺。
当时的大模型竞技场排名是这样的。
大约一周后的11月20日,OpenAI不甘示弱,发布新模型ChatGPT-4o-latest (2024-11-20)。本次更新就是我在上周的文章中提到的针对GPT-4o的创意写作能力进行的提升。
该模型一经发布,同样迅速帮助OpenAI重新夺回了榜首的位置。

然而,另所有人没有想到的是,OpenAI才刚刚高兴了一天,就在11月21日,谷歌再次官宣发布了升级版实验模型Gemini-Exp-1121,该模型在上一代的基础上增强了代码能力、推理能力、多模态视觉能力,也使得谷歌Gemini力压GPT-4o和Claude 3.5 Sonnet重回榜首,夺得第一名的桂冠。

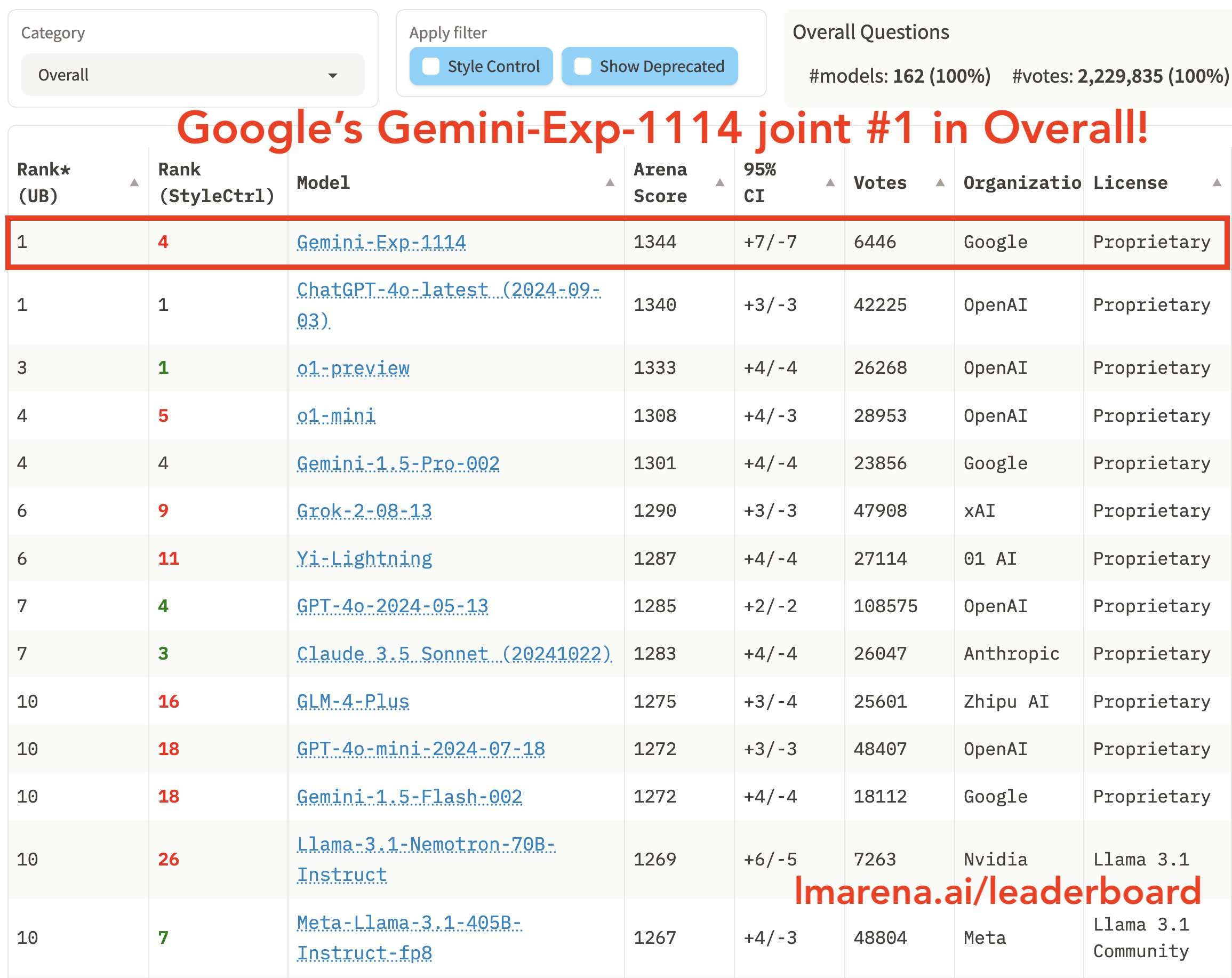
LMSYS竞技场排行榜上的数据更新截止于11月21日,最新的综合排名是这样的。
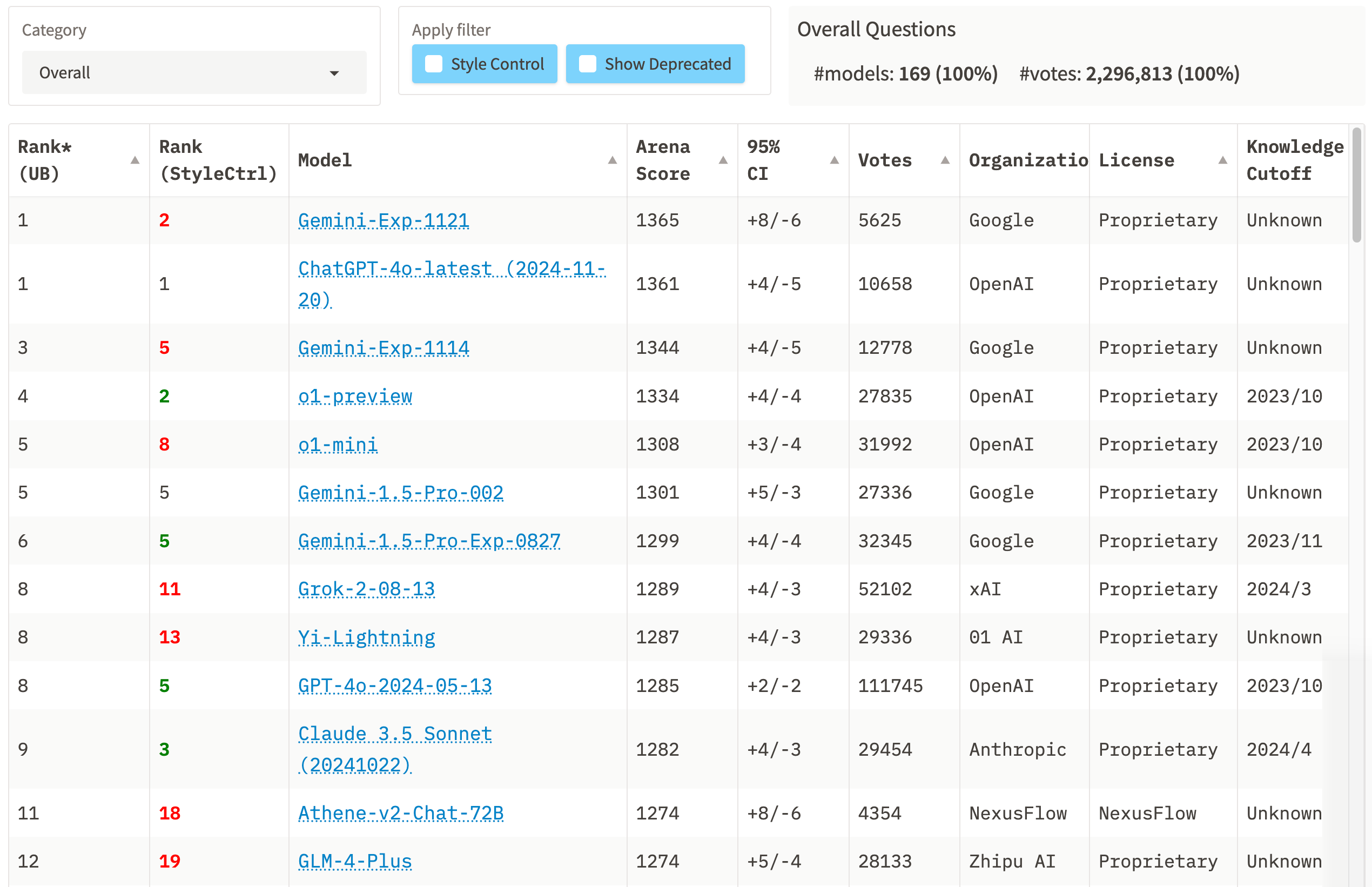
在解读这个排名前,需要了解两点重要信息:
-
该排名是根据模型的综合表现进行排名的,“综合”指的是在评估时,不仅会考虑AI模型的实际回答质量,并且会考虑回答的风格,比如回答长度、Markdown格式的使用等因素。
-
由于
Gemini-Exp-1121和ChatGPT-4o-latest (2024-11-20)都是刚发布不久的模型,所以其投票数都还没有很高,分别是5625、10658个投票。并且这两个新模型的95%置信区间(95% CI)会相对较大,说明它们的综合得分还不够稳定。以Gemini-Exp-1121为例,其综合得分为1365分,95% CI为+8/-6,也就意味着我们有95%的信心认为该模型的真实评分在1359到1373之间。
如果剔除掉大模型的回答风格因素,我们需要在LMSYS排行榜上的Apply filter中勾选Style Control,这样大模型的排名将更加“纯碎”,因为排除了某些可能影响得分的混淆因素。
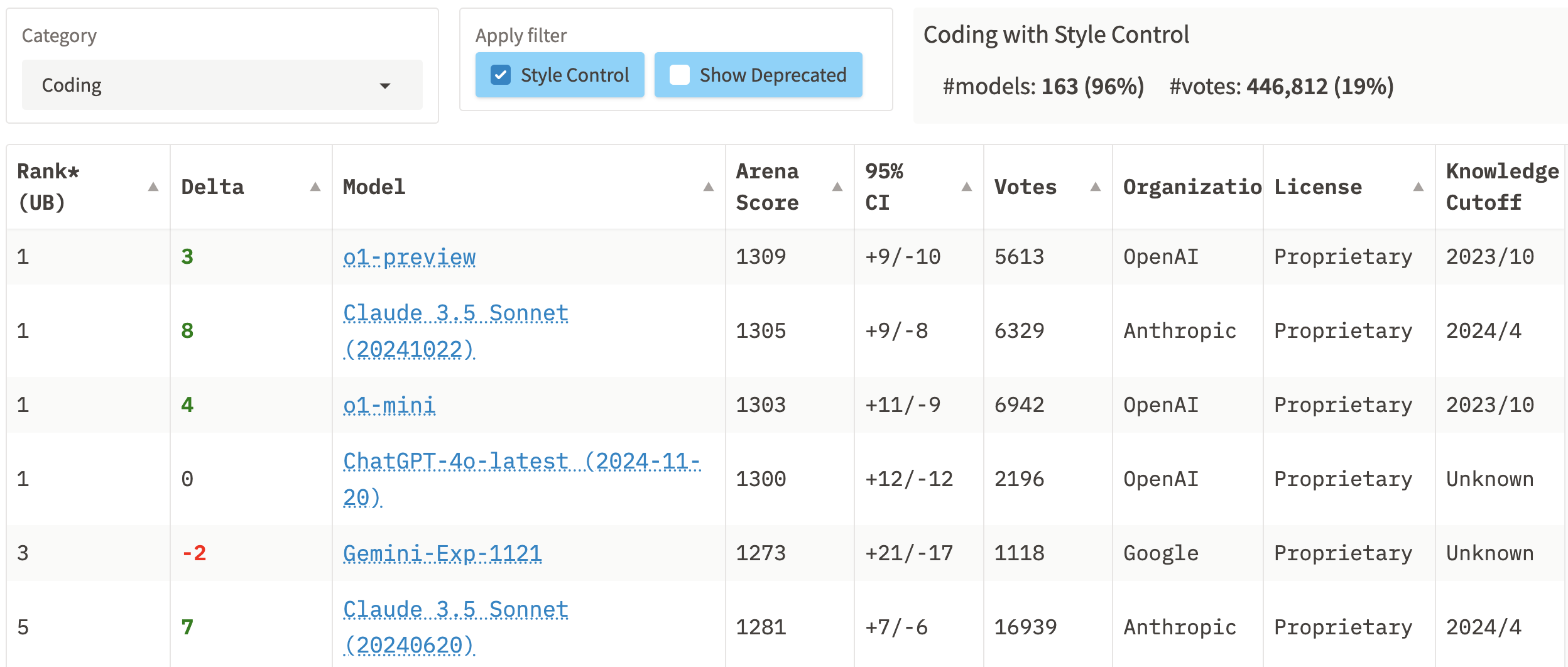
过滤过回答风格这一因素后,带有风格控制(Style Control)的大模型最新排名是这样的。看起来是不是更加符合你的预期,第一名是ChatGPT-4o-latest (2024-11-20),o1-preview和Gemini-Exp-1121并列第二名,第三名是Claude 3.5 Sonnet (20241022)。
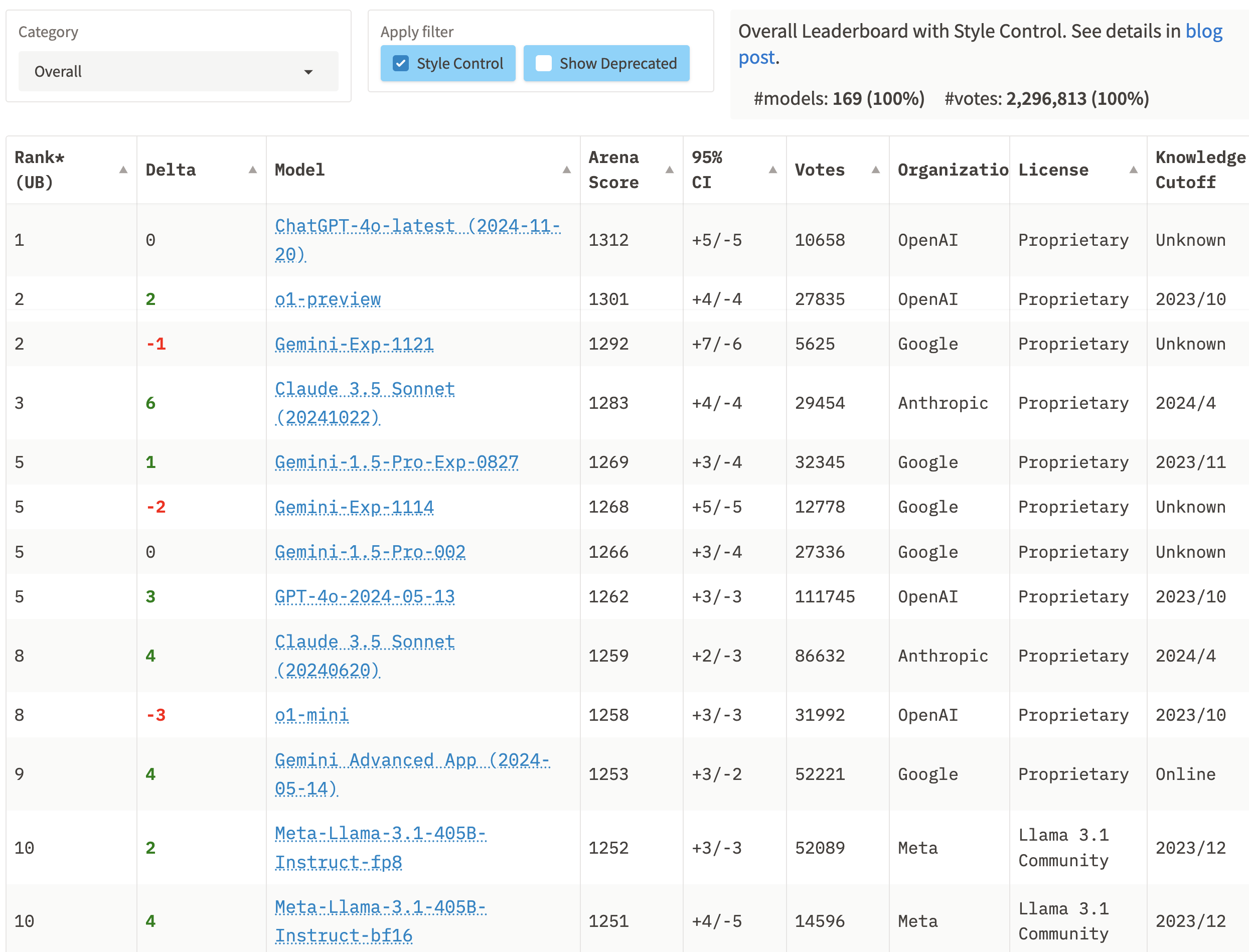
至于到底应该看哪种排名,则仁者见仁智者见智了。需要注意的是,以上排名均为综合排名,即评估的是大模型的综合能力,各个分项的排名可能会有较大变化,比如代码能力(Coding),Claude 3.5 Sonnet必然是名列前茅的。
第一名:Gemini-Exp-1121
谷歌最新的Gemini系列模型,目前以1365的综合得分占据榜首,尽管投票数少了点,只有5625票,但确实是实打实的第一名。根据谷歌官方最新的宣传,该模型在三个方面有显著提高:代码能力、推理能力、视觉理解能力。
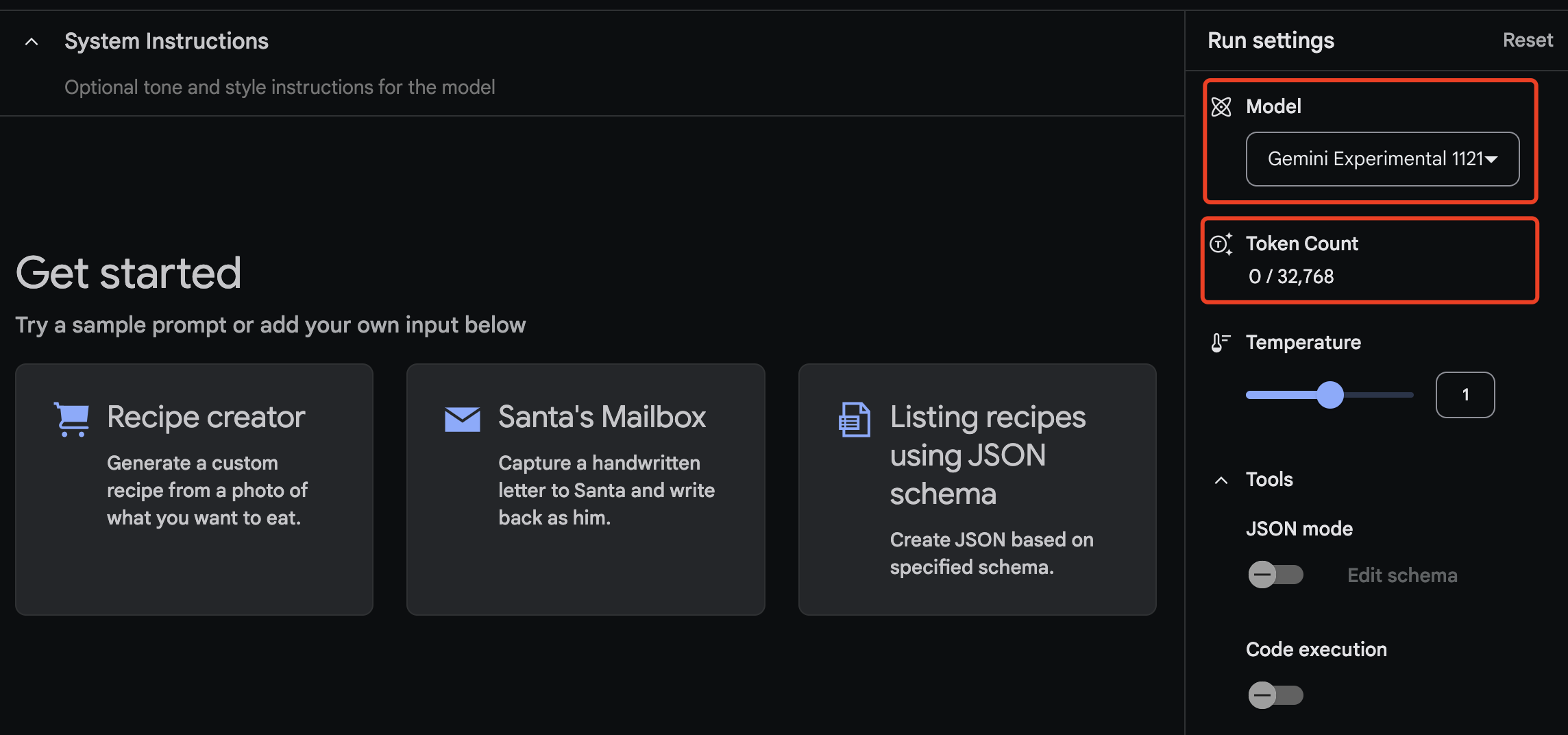
目前Gemini-Exp-1121模型在谷歌AI Studio可以免费体验,并且已支持API调用。在AI Studio中选择该模型后可以看到,其上下文窗口为32768 tokens,也就是常说的32K(并不算大)。
第二名:ChatGPT-4o-latest (2024-11-20)
GPT-4o系列最新模型,发布一天后就被谷歌Gemini从第一名挤到了第二名。目前ChatGPT上集成的GPT-4o就是这个模型,该模型也同样已支持API调用。API定价与老版本GPT-4o模型一致。
第四名:o1-preview
OpenAI的o1系列目前出了两个模型,分别是o1-preview和o1-mini(备注:均不是正式版本),在LMSYS排行榜目前分列第四名和第五名。
可能有小伙伴会有疑问,o1应该是当前最强大模型才对,为什么才排在第四名?这是因为LMSYS的这个排行榜是根据大模型的实际使用体验由用户进行评价打分的。虽然o1模型很强,但它作为一个推理模型,其实并不适合所有任务。具体分析可以翻看我之前的文章。
第九名:Claude 3.5 Sonnet (20241022)
尽管在UB(upper-bound)模式下的排名中,Claude 3.5 Sonnet仅仅排在第九名,但其实在风格控制(Style Control)下的排名中,它排到了第三名。
并且Claude模型在代码方面尤为突出,风格控制下的代码分项排名Claude 3.5 Sonnet更是排到了第一名,与o1-preview模型并列第一。
结语
在这里,附上LMSYS竞技场排行榜的地址,感兴趣的小伙伴可以去查看详情。
https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard
精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









