






Deformable ConvNets v2 Pytorch版源码讲解_2讲到了如何通过这些生成的offset去生成偏移后的坐标点,但是这些点现在都没有特征值,比如(7.2,8.3)这只是一个偏移后的坐标点,并没有真实的特征值。我们现在需要做的就是用原始输入特征图上的点的特征值去计算偏移后的坐标点上的特征值。关于双线性插值的原理我原来博客中也有讲到过,这里不再赘述。
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1) #[B,H,W,9]
m = m.unsqueeze(dim=1) #[B,1,H,W,9]
tosee = [m for _ in range(x_offset.size(1))]
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out第一步先给p转换了一下shape,原始shape是[1,18,5,5]转换成了[1,5,5,18]。方便后续的一个处理。然后对p进行一个向上取整操作。这取的其实就是每个偏移后的坐标点的左上角坐标点q_lt,对q_rb取的就是右下角坐标点。同时我们前面提到过这些点的前9个代表的都是x,后9个代表的是y。那么我们限定一下x,y坐标分别不能超过图片的宽和高,注意这里的x是padding后的,图像的坐标点范围只能是0-6.那么有了左上角坐标点以及右下角坐标点我们就可以很方便的得出右上角和左下角的坐标了。同时我们对原坐标点也进行了同样的限定。求出满足图片宽和高的坐标点p。好,现在我们可以开始进行双线性插值计算了。注意这里的双线性插值GitHub上有人提问说作者的双线性插值代码是不是错的。公式里面没有1+,1-这样的操作啊。确实我在之前推导过双线性插值公式的,里面是没有1+,1-的。但这里作者其实绕了一个小圈。我们先看左上角坐标点。
 (x1-x)(y1-y)就是f(A)点对应的系数,又因为1+x0=x1。所以(x1-x)等价于(1+x0-x)这不就是咱们的双线性插值公式的另一种表达方式吗,也就是作者源码中的写法.。其他的位置咱们可以按同样的方法分析。所以这里的双线性插值代码是没有问题的。
(x1-x)(y1-y)就是f(A)点对应的系数,又因为1+x0=x1。所以(x1-x)等价于(1+x0-x)这不就是咱们的双线性插值公式的另一种表达方式吗,也就是作者源码中的写法.。其他的位置咱们可以按同样的方法分析。所以这里的双线性插值代码是没有问题的。
那么后面就是对f(A)取值了。用到了self._get_x_q函数,传入的是原始输入x(padding过后),偏移过后的坐标点q_lt(整数值)。
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
x原来的shape是[B,C,H,W]把他转换成[B,C,H*W],方便后续的一个取值操作。index是获取它的索引,为什么这么做?我们举个例子来说,我们想求(4,3)这个坐标点的在x中的索引,(5,4)这个点如下图所示


其在图中索引位置就应该是4*7+3=31,也即源码中的q[...,:N]*poadding_w+q[...,N:].这样操作完后其实每个坐标点对应原图中的索引位置咱们找到了,注意这里只是一个通道上的索引,其实网络的输入x是有多个通道的,我们需要针对多个通道进行一个操作,代码中是先将index扩充第二个维度变成(B,1,H,W,N),在沿第二个维度复制C份,变成(B,C,H,W,N),最后同样把其reshape至(B,C,H*W*N),这里打印一下index
tensor([[[ 0, 0, 1, 7, 0, 2, 14, 8, 8, 1, 1, 2, 7, 1, 3, 15, 9,
9, 2, 2, 3, 8, 2, 4, 16, 10, 10, 3, 3, 4, 9, 3, 5, 17,
11, 11, 4, 4, 5, 10, 4, 6, 18, 12, 12, 7, 7, 8, 14, 7, 9,
21, 15, 15, 8, 8, 9, 14, 8, 10, 22, 16, 16, 9, 9, 10, 15, 9,
11, 23, 17, 17, 10, 10, 11, 16, 10, 12, 24, 18, 18, 11, 11, 12, 17,
11, 13, 25, 19, 19, 14, 14, 15, 21, 14, 16, 28, 22, 22, 15, 15, 16,
21, 15, 17, 29, 23, 23, 16, 16, 17, 22, 16, 18, 30, 24, 24, 17, 17,
18, 23, 17, 19, 31, 25, 25, 18, 18, 19, 24, 18, 20, 32, 26, 26, 21,
21, 22, 28, 21, 23, 35, 29, 29, 22, 22, 23, 28, 22, 24, 36, 30, 30,
23, 23, 24, 29, 23, 25, 37, 31, 31, 24, 24, 25, 30, 24, 26, 38, 32,
32, 25, 25, 26, 31, 25, 27, 39, 33, 33, 28, 28, 29, 35, 28, 30, 42,
36, 36, 29, 29, 30, 35, 29, 31, 43, 37, 37, 30, 30, 31, 36, 30, 32,
44, 38, 38, 31, 31, 32, 37, 31, 33, 45, 39, 39, 32, 32, 33, 38, 32,
34, 46, 40, 40],
[ 0, 0, 1, 7, 0, 2, 14, 8, 8, 1, 1, 2, 7, 1, 3, 15, 9,
9, 2, 2, 3, 8, 2, 4, 16, 10, 10, 3, 3, 4, 9, 3, 5, 17,
11, 11, 4, 4, 5, 10, 4, 6, 18, 12, 12, 7, 7, 8, 14, 7, 9,
21, 15, 15, 8, 8, 9, 14, 8, 10, 22, 16, 16, 9, 9, 10, 15, 9,
11, 23, 17, 17, 10, 10, 11, 16, 10, 12, 24, 18, 18, 11, 11, 12, 17,
11, 13, 25, 19, 19, 14, 14, 15, 21, 14, 16, 28, 22, 22, 15, 15, 16,
21, 15, 17, 29, 23, 23, 16, 16, 17, 22, 16, 18, 30, 24, 24, 17, 17,
18, 23, 17, 19, 31, 25, 25, 18, 18, 19, 24, 18, 20, 32, 26, 26, 21,
21, 22, 28, 21, 23, 35, 29, 29, 22, 22, 23, 28, 22, 24, 36, 30, 30,
23, 23, 24, 29, 23, 25, 37, 31, 31, 24, 24, 25, 30, 24, 26, 38, 32,
32, 25, 25, 26, 31, 25, 27, 39, 33, 33, 28, 28, 29, 35, 28, 30, 42,
36, 36, 29, 29, 30, 35, 29, 31, 43, 37, 37, 30, 30, 31, 36, 30, 32,
44, 38, 38, 31, 31, 32, 37, 31, 33, 45, 39, 39, 32, 32, 33, 38, 32,
34, 46, 40, 40]]]) 可以观察到2个channel其实都是一样的索引,也就是前面中咱们提到的,每一个通道上的点学到的offset都是一样的,举个例子:通道1上的(0,0)学到的offset和通道2上的(0,0)学到的offset是一模一样的,即都offset至一个固定点,但得出的像素值肯定不一样。比如说都offset至(1,1)这个点,但其来自于不同通道它们的像素值肯定不一样。
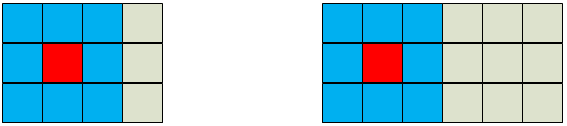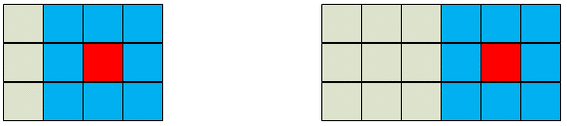
到这里咱们就可以利用x.gather取出这些索引对应的特征值了。最后特征值拿到后,就可以利用双线性插值公式算x_offset了。拿到offset的值后,如果采用Deformable ConvNets v2的思想的话,在用m(网络学到的特征值权重)和得出的offset后相乘,得到一个经过更正后的采样特征值,得到的应该是一个(b, c, h, w, N=9) ,但这没办法和正常卷积进行卷积(卷积要求输入shape是(B,C,H,W)).最后作者将其reshape成(b,c,h*3,w*3)了。其实就像下图。然后在5*5的特征图上,一共是有五个这样的操作的。所以作者在这里将其reshape成(B,C,15,15)。再用一个常规的3*3的卷积,卷积步长为3(=kernel_size),padding=0的普通卷积去滑动。最后得出的就是咱们经过可变形卷积后的一个结果了。















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









