







文章目录
相关阅读:https://blog.csdn.net/weixin_40844116/article/details/85260796
一、安装pymysql包
Cmd命令窗口输入:pip install pymysql,根据提示选择是否更新
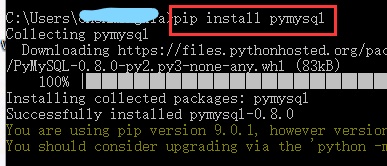
如果之前有2版本

二、读取数据库
1、直接连接:.connect()——.cursor()——.execute()——.fetchall()——.close()
Step1:导入pymysql包
import pymysql
Step2:新建连接.connect()
- host – 127.0.0.1或者localhost
- uesr和password – 设置数据库是使用的用户名和密码
- db – 要连接的数据库
- port – 默认3306
- charset – 使用数据库时设置的编码格式
conn=pymysql.connect(
host='localhost',
user='root',
password='123456',
db='data',
port=3306,
charset='utf8')
Step3:获得游标.cursor()
cur=conn.cursor()
Step4:游标执行sql语句.execute()
注意:每次查询更改,从这一步开始往下都要重新执行一遍
>>>cur.execute("select * from company")
2296#返回数据行数
Step5:获取所有数据.fetchall(),获得一个元组
data=cur.fetchall()
>>>type(data)
tuple
data

Step6:使用数据库
#逐一读取该元组里面的数据
for d in data:
print(d)

#逐一读取该元组里面的数据,切片
for d in data:
print(d[0],d[1])

Step7:关闭游标cur.close()、关闭连接conn.close(),如果对数据库进行实质操作,需要提交conn.commit()
cur.close()
#conn.commit()
conn.close()
2、pandas+pymysql:.read_sql
Step1:导包
导入 pymysql 、pandas包
再从’sql魔法盒‘(sqlalchemy)导入“制造引擎”(create_engine)
#如果直接import sqlalchemy ,则之后使用create_engine的时候前面加sqlalchemy.
import pymysql
import pandas as pd
from sqlalchemy import create_engine
Step2:准备一个sql和一个con
格式: mysql+pymysql://帐户名:密码@主机地址:端口/数据库名?charset=编码格式
注意:以前的pandas版本con可以直接使用pymysql.connect()的方式创建,新版本不能(之前的conn可能不能用)
sql="select * from company where companyShortName='聚美优品'"
#格式 mysql+pymysql://帐户名:密码@主机地址:端口/数据库名?charset=编码格式
con=create_engine('mysql+pymysql://root:123456@localhost:3306/data?charset=utf8')
Step3:使用pandas读取sql的方法.read_sql,获得一个数据框dataFrame
df=pd.read_sql(sql,con)
三、写入数据库
#Step 1:导包
import pymysql
import pandas as pd
from sqlalchemy import create_engine
#Step2:读表(可以读取单个表或者多个表,再把多表用merge等连接成新表)
方法1,定义sql语句执行的函数
def reader(sql#,db,char#):
#{0}、{1}等代替参数,最后.format(参1,参2.。。)
#con=create_engine('mysql+pymysql://root:123456@localhost:3306/{0}?charset={1}'.format(db,char))
con=create_engine('mysql+pymysql://root:123456@localhost:3306/data?charset=utf8')
df=pd.read_sql(sql,con)
return df
df_company=reader('select * from company')
df_company

方法2:直接.read_sql将要的表读出来
sql='select * from dataanalyst'
con=con=create_engine('mysql+pymysql://root:123456@localhost:3306/data?charset=utf8')
df_dataanalyst=pd.read_sql(sql,con)
df_dataanalyst

Step3:将读出来的表进行操作形成新表
#连接两张表
m=pd.merge(df_dataanalyst,df_company,on='companyId')
#reset_index()是将series转换成dataframe
result=m.groupby(['city','companyShortName']).count()['positionId'].reset_index()
result.head()
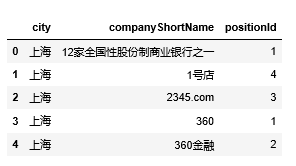
Step4:将新表写入数据库 to_sql
#if_exists='append'如果表存在就在后面追加,如果不存在就新建
#index=False 不将索引作为字段写入
result.to_sql(name='newtabel',con='mysql+pymysql://root:123456@localhost:3306/data?charset=utf8',
if_exists='append',index=False)
数据库中就生成了新表
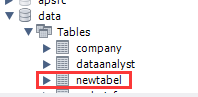
四、新表整理
由于用python生成的新表格式与传统建立的表不同,因此,需要我们整理该表,整理的方法是再去建一个表2,将里面的字段填写完整,字段类型选择合适的
原表

新表

重新执行.to_sql语句,将name改成已经建立好的表名

此时新表的内容已经被写入,并且按照之前建立的格式
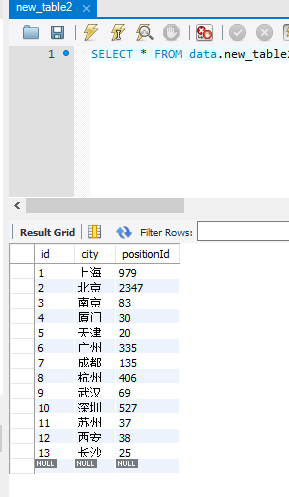
注意:append重复执行导致重复插入
Index=True会报错,因为新表没有给index预留位置,相反,如果插入的数据字段比表少,则未写入的字段在表中自动为空
如果想把表写成csv格式,在.to_sql改成.to_csv,将表名的后缀.csv















 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









